
日前,全球最负盛名的 AI 学术会议之一NeurIPS(Neural Information Processing Systems)公布了2022年论文接收结果。创新奇智投稿论文 《An Embarrassingly Simple Approach to Semi-Supervised Few-Shot Learning》成功被NeurIPS 2022接收。
作为当前全球最负盛名的 AI 学术会议之一,NeurIPS 是每年学界的重要事件。NeurIPS全称是 Neural Information Processing Systems,神经信息处理系统大会,通常在每年 12 月由 NeurIPS 基金会主办。大会讨论的内容包含深度学习、计算机视觉、大规模机器学习、学习理论、优化、稀疏理论等众多细分领域。 今年 NeurIPS 已是第 36 届,将于 11 月 28 日至 12 月 9 日举行,为期两周。第一周将在美国新奥尔良 Ernest N.Morial 会议中心举行现场会议,第二周改为线上会议。NeurIPS 2022 论文投稿早已在 5 月 19 日截止,今日官方终于公布了录用结果。根据官网邮件中给出的数据,本届会议共有 10411 篇论文投稿,接收率为 25.6%,略低于去年的 26%。


论文解读:

图1:论文概要
论文概述:
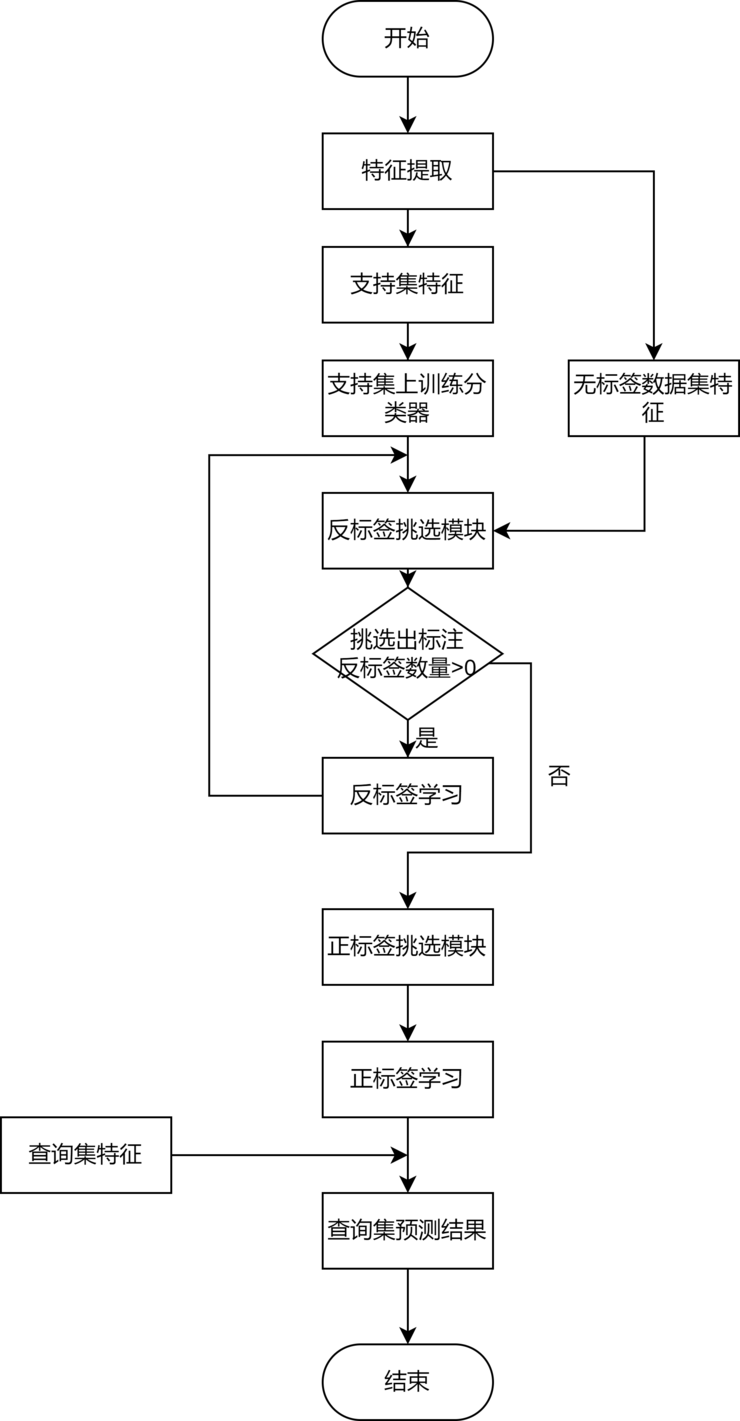
本文提出了一种基于反标签学习的半监督少样本图像分类学习方法,包括以下步骤:构造元任务,使用预训练的神经网络作为特征提取器,提取元任务中支持集、查询集以及无标签图像数据集对应的特征,并在支持集上训练一个分类器用于后续分类任务;反标签学习模块以较高正确率给无标签数据打上反标签,分类器在反标签上进行学习更新,不断迭代直到无法选出反标签。正标签学习模块,在反标签模块迭代结束之后,得到类别均衡且正确率较高正标签,并用分类器进行学习更新。
本文通过卷积神经网络提取元任务中对应数据的特征,通过反标签构造模块以较高正确率利用无标签数据,并用分类器在反标签数据上进行学习更新,进行迭代之后设计正标签学习模块获得类别均衡且正确率较高的正标签,用分类器在正标签数据上进行学习更新,以更加充分且高质量的利用无标签数据,可以获得更高的少样本学习图像分类准确率。
创新背景:
随着深度学习的发展,卷积神经网络在多个图像任务上已经超过了人类的水平,但是这些模型的训练依赖大量的数据,在现实生活中有些数据的采集难度较大,例如对液晶显示屏幕所有种类缺陷数据的采集,另外这些数据的标注也需要耗费大量的人力和财力。 相比之下,人类视觉系统可以从少量的例子中快速学习到新的概念和特征,然后在新的数据中识别相似的对象。为了模仿人类的这种快速学习的能力,减少方法对于数据的依赖,少样本学习近年来受到了越来越多的关注。少样本学习旨在结合先验知识快速地泛化到只包含少量有监督信息的样本的新任务中,在此设定下识别每个类别仅需要极少甚至一张带标签的样本,所以可以极大地减少人工标注成本。
基于少样本学习这样数据量较少的设定,一个需要面临的问题就是,在极少的带标注数据上,很难让模型较好的拟合到数据的分布。因此为了解决这样的问题,少样本学习中出现了结合半监督的研究方向。另外为了解决数据标注困难的问题,反标签学习的方法也应运而生。反标签顾名思义就是给数据打上相反的标签,是一种间接的方式代表该数据不属于某个类别。这样的做法可以大大降低数据标注的错误,例如对于一个5分类问题来说,给数据打真实标签即正标签错误的概率为给数据打反标签错误概率的4倍。另外在半监督少样本学习当中,由于带标签数据很少,因此模型在初始阶段很难有好的效果。用这样的模型给无标签数据标记伪标签将会出现大量的错误以及类别不平衡的现象。在这样的情况结合反标签学习的方法就可以解决这样的问题。本发明研究的基于反标签学习的半监督少样本学习方法,针对半监督少样本学习,设计适合的反标签标注方法,并结合反标签学习解决半监督少样本学习中出现的无标签数据利用不充分等问题。
目前,出现了许多研究半监督少样本学习的方法,但依然存在一些问题: 1)给无标签数据标注伪标签的正确率较低,错误标记的样本会影响最后的结果;2)无标签数据上标注的伪标签存在类别不平衡现象;3)方法较为复杂。
本论文主要贡献:
本论文提出了一种基于反标签学习的半监督少样本图像分类学习方法。 方法具体如下:
步骤1,构造元任务,使用预训练的神经网络作为特征提取器用来提取图像数据,提取元任务中支持集、查询集以及无标签数据集对应的特征,并在支持集上训练一个分类器,用于后续图像分类任务;

步骤2,反标签学习模块以较高的95%正确率给无标签图像数据打上反标签,用分类器在反标签上进行学习更新,通过不断迭代直到无法选出反标签;
步骤3,正标签学习模块得到类别均衡且正确率高达85%的正标签,并用分类器进行学习更新;
步骤4,用训练好的分类器在查询集上预测得到最后图像分类的类别结果。
本文提出的方法与已有技术相比,其显著优点为:
(1)本发明设计的反标签学习模块,通过给无标签图像数据标注反标签并进行学习的方式,在模型效果还不好的初始阶段,大大降低给无标签图像数据标注标签的错误率;
(2)经过反标签学习模块之后,本发明设计的正标签学习模块可以得到正确率高且类别均衡的正标签,继续对模型进行训练;
(3)本发明提出的方法相较于之前的方法流程简单,可以更充分且高质量利用无标签图像数据进行学习,最后在图像分类任务上得到了更好的效果。
创新奇智CTO张发恩(论文作者之一)表示:“当前的深度学习技术对人工标注的数据样本(也即带标签数据样本)数量具有很大依赖性,如何减少对带标签数据样本的依赖,利用较少的带标签数据样本训练出理想的视觉算法模型成为当下亟待突破的技术难点。 少样本学习旨在从已有类别的数据中学习先验知识,然后利用极少的标注数据完成对新类别的识别,打破了样本数据量的制约,在传统制造业等样本普遍缺失的领域具有实用价值,有助于推动AI落地。”
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!