


就在最近,生成式 AI 又火了,这次是国内的平台!
9月,一个叫做「盗梦师」的微信小程序悄悄上线,却一鸣惊人,达成日增5万新用户的纪录,足以见得国内玩家对亲手玩到 AI 绘画渴待已久。
不怪玩家们太热情,从Midjourney 到 Stable Diffusion,AI「以文生图」一直是好几个月来最炙手可热的话题。「以文生图」AI 打通了文字和图像的隔阂,只要输入一段文字描述,AI 就可以把用户脑海中想象的画面呈现出来。用户输入的文字越大胆,AI 生成的图片就越突破人类想像,宛如盗来了梦中的绚烂画卷。
盗梦师正是一个能根据输入文本生成图片的 AI 平台,属于AIGC(AI-Generated Content,即人工智能生成内容)的分支,由蓝振忠博士带领的西湖大学深度学习实验室和西湖心辰科技有限公司共同推出。
在用户发挥想象,输入文字描述后,盗梦师便可生成1:1、9:16和16:9三种比例的图片,还有24种绘画风格可以选择——除了基础的油画、水彩、素描等绘画种类,还包括赛博朋克、蒸汽波、像素艺术、吉卜力和 CG 渲染等特别风格。
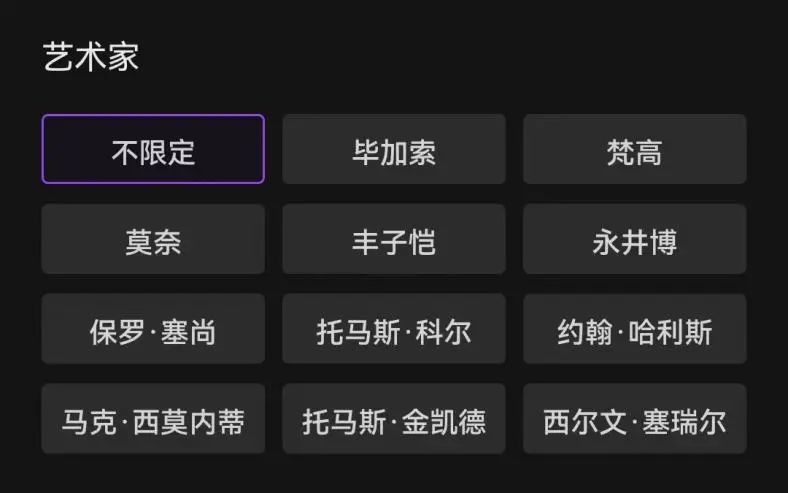
如果用户有明确想要生成的艺术家风格,还能在毕加索、梵高、莫奈等11位艺术家中进行选择。
在9月24日,盗梦师上线了图生图的功能,这是在文生图基础上的进一步尝试。只要上传一张参考图,便可以生成与该图风格相近的图片,也可以在原画的基础上添加自己的创意。
而盗梦师最为接地气的设定,还要属「图片版权由生成用户所有」。
有许多用户接触 AIGC 的目的并不是纯「玩」,他们更希望自己可以拥有生成图片的版权,从而利用这些 AI 产物玩转社交平台、成为自己艺术创作的素材、抑或是创造更大的价值——而盗梦师正满足了国内 AIGC 用户的这份野心。
看小说时,谁没有脑补过几个惊呼叫绝的场景?可跨不过的绘画门槛,却成了普通人表达想象力的大难题。盗梦师之所以受到极大关注,正是因为盗梦师能让不会画画的人绘出自己脑海中的画作,这才以一己之力激起惊人浪花。
而懂先生、斧头哥和薄荷三位玩家,就是掌握了 AI 绘画语言密码的几位佼佼者。
我们先来看看玩家懂先生生成的梦幻人物肖像——
盗梦师生成的图像:

盗梦师生成的图像:

lili 则是一位 AIGC 新玩家,她几乎没有相关经验,只靠在社区中学习到的文字描述方式,加上自己投入时间调试,制作出的人物肖像也颇为美丽,极具东方美感。
盗梦师生成的图像:

人像是 AIGC 界中公认容易失调的生成对象,虽说盗梦师偶尔也会跳出五官不和谐的人像,但总的来说,只要文字「调教」得好,一幅充满质感的人物肖像便会跃然纸上。如再经过专业人士加工,几乎达到了直接能在游戏中派上用场的级别。
除人像以外,盗梦师生成的风景图无论虚拟还是写实,都称得上绝美,比如玩家斧头哥生成的这些风景每张都有可圈可点之处——
盗梦师生成的图像:

盗梦师生成的图像:

盗梦师生成的图像:

盗梦师生成的图像:

盗梦师生成的图像:

这五幅风景画风格各异,共同点则是都牢牢把握住了用户输入的风格需求,如将这一工具善加使用,小团队也不愁做不起烧钱的炫酷场景了。
为了更深入了解盗梦师这个「盗取艺术火种」的趣味平台,小编对盗梦师团队进行了一次专访,并提出一系列问题,与大佬们探索生成式 AI 的无限可能。
以下是小编与盗梦师团队的对话:
小编:请问在什么样的场景下,贵团队产生了想要做文本生成图像 AI 的想法?
盗梦师团队:我们之前一直在做文生文和可控文本生成的产品,近来我们发现,文生图走到了一个商业可用的阶段。而图片给人的冲击力会更强,信息的传播能力也很好,所以我们希望能够在这个领域也做出一些能够帮助到大家的产品。
小编:盗梦师所用的模型是什么?
盗梦师团队:是在 Stable Diffusion 的基础上做改进。
我们在几个月前已经开始研究文生图,那时已经有很多的图片生成技术,比如生成对抗网络 GAN、DALL·E 的自回归模型,当时我们用自己的数据和 follow instruction 方式去做过一些训练,但是我们认为生成效果都没有达到可商用的水平。
就在一个月前, Stable Diffusion 一经发布,我们用自己的 follow instruction 方式对它重新做了训练,发现生成的图片效果非常惊艳,我们也被震撼了,于是花了两周的时间,和前后端、产品同学一起把盗梦师推上线。
小编:Follow instruction 方式是什么?
盗梦师团队:Follow instruction 方式是盗梦师最大的一个创新。一张生成的图片被用户保存下来,这表示用户认可这张图的效果,这就是一个训练的信号,我们可以根据这个信号去训练更好的图像。我们之前在文生文这一块也有做类似工作,就是让模型更好地 follow instruction,即更好地听懂用户的指令,生成用户想要的东西。
小编:盗梦师还有哪些创新思想?
盗梦师团队:盗梦师还在引导用户更好地输入方面不断进行改进。现在大家可以看到,在模型生成的10张图里,有一张用户想要的就很不错了,尤其是初阶玩家还不太熟悉如何输入,生成效果也会打折扣,所以模型 follow human instruction 方面做得还不够好。
举个例子,在研究用户保存图片行为的时候,我们发现那些用户没有保存的图,其平均输入文字大概是14个字,而用户保存下来的图片,其平均输入文字是18个字。这说明用户的输入与图片质量有很大关系,我们需要在引导用户更好地输入这方面不断改进。
小编:我在玩盗梦师的时候,看到文字输入框下有输入提示,也在用户手册中读到指导用户输入的内容。除此之外,盗梦师还有哪些从产品角度出发的设计?
盗梦师团队:从整个产品用户体验的角度来看,我们希望尽量让所有的用户都能轻松上手玩 AIGC(AI-Generated Content)。虽然现在有很多UP主和各种推文在介绍怎么玩,甚至尝试在自己电脑上搭起来,但仍然只有少量的技术型用户和极客能够玩 AIGC。
而我们希望凡是对此有兴趣的创作者,甚至没有一点技术基础的用户,都能够很快上手玩起来。所以盗梦师会对用户输入有许多提示,并且给出了毕加索、梵高、莫奈等艺术家画风供用户直接选择。
同时,盗梦师还用图片的形式表现可生成的艺术风格。

如果没有图片,很多用户可能不知道蒸汽波和未来主义是什么样的艺术风格,但是用图片做示例后,用户就可以轻松选择,能获得更多尝试的动力。
同时我们还做了艺术展,这是一个展示区,可以看到其他用户的作品。有的高阶用户本身是美术从业者,可以设计出非常惊艳的图。在展示区里,较为初阶的用户就可以学习别人怎么去写出好的 prompt(即输入文字描述)。
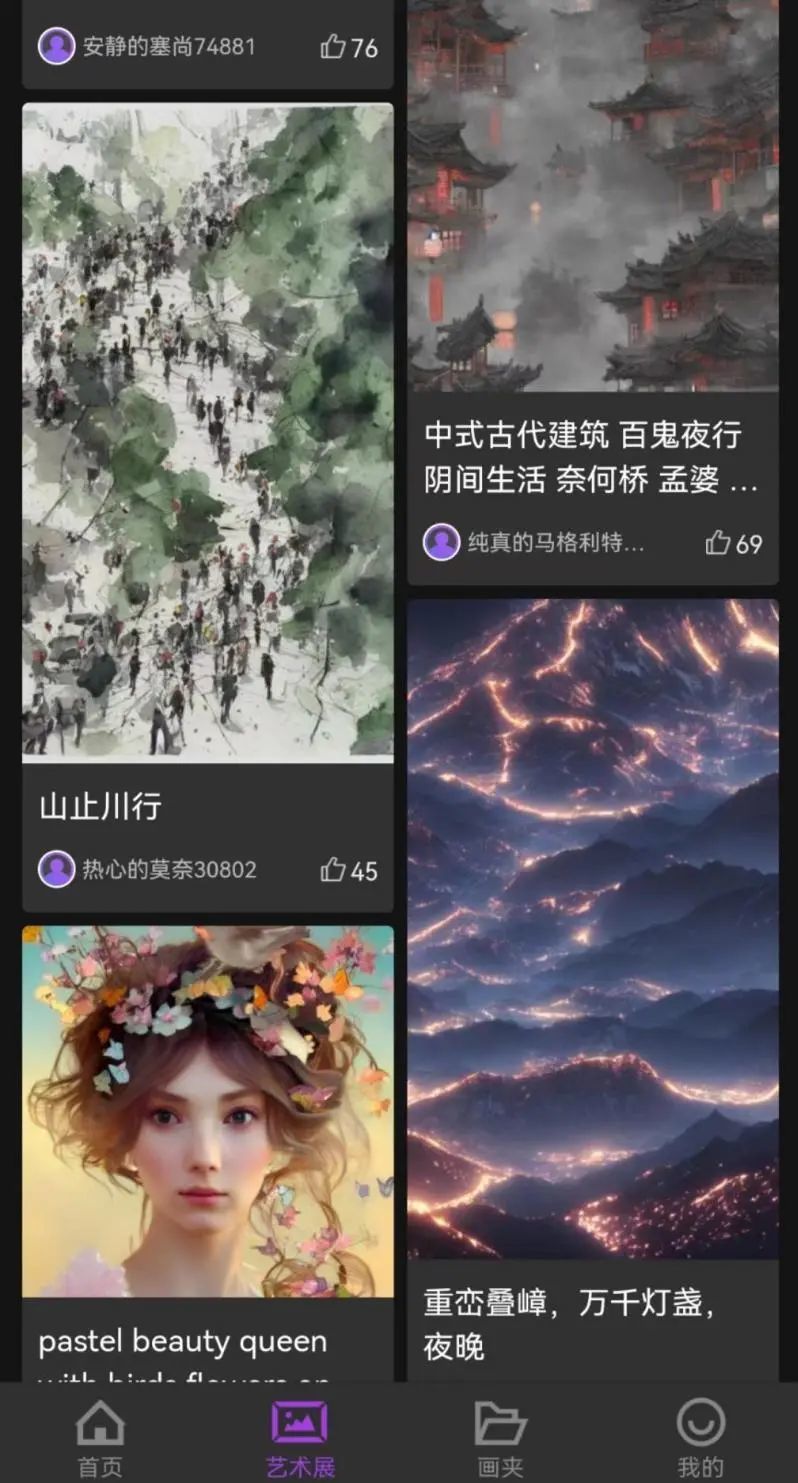
图注:盗梦师艺术展
盗梦师算法团队近期准备上线一个小功能,可以在输入侧帮助用户填充文本。很多新用户刚开始玩,不知道要输入什么文本,可能只会输一个“太阳”或“月亮”等特别简短的内容。
但深度玩家会就发现,盗梦师要玩得好,需要关键词、效果词,再加上艺术家和风格的各种搭配。针对用户保存的、在艺术展展出的好图,我们会把这些好图的 prompt 收集起来,在用户输入的时候做一个近似度的匹配,便于用户更快学习到文本输入的诀窍。
小编:在盗梦师输入“画一个自行车并标明在地面滚动的部分”,其生成的图片缺乏逻辑,效果不佳,这是否说明盗梦师不理解自己所画物体的运作方式,而是和其他 AI 一样“学习大规模数据集并以新方式融合” ?
盗梦师团队:是的,生成式 AI 的现状基本都是模仿。
小编:请问盗梦师如何突破这个普遍现状,达到“理解自己画出的世界,运用知识进行推理并决策”的水平?投入什么样的技术有可能实现呢?
盗梦师团队:虽然目前的图片生成 AI 能力确实到达了历史上的峰值,但是我觉得还是需要更大的规模的数据以及更长时间的训练。
而这个数据,不仅仅是数量更大,还需要包含更全面的信息,比如说,图片不仅仅只是图画,也可以是医院的x光片,也可以是建筑设计师画出的设计图,囊括了生活的方方面面。
同时,我们使用 follow instruction 的方式,也就是使用用户的反馈、点赞等信号,加上专业美术生帮助我们做标注和评测。将人类的反馈信息结合到我们的模型训练中,然后以期待生成更加遵循用户输入指令的图片。
第三,根据过往做语言对话、文本生成方面工作的经验,我们认为在文生图这方面我们还需要用更大的语言模型来帮助盗梦师画出它理解的世界。
由于语言中蕴含了极为丰富的知识,所以运用我们之前在语言方面预训练过的模型,会对盗梦师图片生成中的一些数字问题、常识问题会有很大的帮助,我们可以通过这方面的训练,让盗梦师逐步去达成运用知识进行推理和决策。
小编:图像生成AI的出现让我们离通用人工智能(AGI)又近了一大步吗?您认为图像生成AI与AGI之间有什么联系?
盗梦师团队:我认为不是这样。没有太大联系,生成式 AI 更多是概率模型。
小编:有学者老师做过一个环境相机,通过融合温度、湿度等传感器的多模态信息,可以提升相机的成像质量。那么图像生成AI是不是也可以通过融合更多其他模态信息的方式,提高图像的生成质量?
盗梦师团队:有可能。我们已经有类似的 idea,文生图服务不一定只能通过文字生成。例如盗梦师有参考图的设置,用户可以上传一张图片,加上文字描述,从而生成更好玩的图片。
我们还有更多的想法,比如,也许可以加上用户的交互操作,或者用户可以选中图片的某些地方,甚至是用户之间通过协作画图……像这些交互式的信息,将来都有可能作为训练数据,从而实现提高生成图片的质量、提高对图片的可控性。
小编:“利用盗梦师平台生成的图片版权属于用户”,这个版权的设定和其他AI平台不同,请问贵团队为何决定如此设定?
盗梦师团队:我们做出这个设定是基于两点:一是盗梦师建立在CCO协议的基础上,二是因为用户会花很多精力和时间去调试 prompt,而且 AIGC 的创作灵感是来源于用户,没有用户的灵感就没有新图的诞生,所以我们觉得应该将创作版权归还给用户。
小编:有人认为生成式AI的出现会使某些行业从业者的大面积失业,您对生成式AI给社会带来的便利和冲击有什么看法?
盗梦师团队:原来不能作画的人,现在能够享受创作带来的愉悦;也有一些插画师开始思考怎么利用盗梦师才能更好、更快地完成作品。但盗梦师带来便利、提高生产力的同时,肯定也会对一部分人有所冲击,就像汽车的出现造成了马车夫的大面积失业一样。但失业的马车夫也可以转行去做司机。
总的来说,我们认为生成式 AI 的到来鼓励了广大从业者与新技术进行结合,更好更快地做出作品。
B站上有一个热评,说目前 AI 生成图片有两大使用功效,一是出概念、找灵感,二是当成p图素材与手工结合,我们非常认可这两点。
小编:但仍有一些美术从业者不愿意自己的作品被 AI 学习,您怎么看?
盗梦师团队:我觉得在新浪潮当中大家可以保持自己的观点。例如在相机出现之后,有的画家转向了非写实流派,也有一些艺术家走向了摄影艺术。
对于现在的手绘工作者来说,可以选择调整自己的风格,也可以选择与 AI 结合,成为一个数字艺术家。我们觉得生成式 AI 更多带来的还是一种新的艺术业态。
AI生成图片的版权争议应该还会继续一阵子,包括图片被用来训练模型的艺术家们该如何从AI生成的图片中获益一定也是大家探讨和研究的热门话题。相信随着创作形态的改变,版权本身的定义和保护方式也会有更多发展。我们相信类似区块链等新技术最终会带来新形态的版权保护和收益分享机制,更好的促进创新和创作。我们大胆猜测不久的将来,有一部分艺术家会很乐意自己的图片成为AI的训练素材。
小编:在充满竞争的环境当中,盗梦师如何脱颖而出?
盗梦师团队:除了本身算法能力强,我们还积累了丰富的产品经验,我认为这算是一个天生的优势。在竞争较为激烈的环境里,我们会去尝试更多将艺术和 AI 结合的产品设计,去引领 AIGC 的潮流,这个是我们非常想做的事情。
小编:请问盗梦师的未来商业计划是什么样的?
盗梦师团队:我们从10月份起会开始低强度的收费,即是说,会以亲民的方式去让大家使用。大部分的普通用户不需要付费,而高强度使用的专业玩家可以选择优惠套餐,这个是 To C(面向消费者)的商业计划。
同时我们认为,To B(面向企业)也有非常多的商业场景。像游戏场景制作、文本图片编辑器、美术教育等方面均已有公司开始接洽。
长期来看,在To B 方向,我们会在行业里继续深耕,我们之前做文生文或者可控文本生成就有经验,要做到更精深,更有护城河的话,要做到去收集和获取行业的知识和数据,才能在这个行业里面取得好的效果。
我们也明白,To C 还是有较大难度的,但我们依然会去探索。从产品角度来说,可能有人会说社交平台的仗已经打完了,而现在出现了内容生成的利器,成为创作者的门槛大幅度的降低了——AIGC 能让每个人都参与到创作中,这是一个全新的浪潮。所以即便知道难度较大,我们也会去探索。
小编:除了向客户提供付费生成服务的“基础模式”外,图像生成 AI 还有什么更远大的用途吗?
盗梦师团队:我们其实有挺多的 idea。我们团队一直在做心理咨询机器人,图像生成 AI 就可以应用到心理咨询服务中。举个例子,有一个心理咨询疗法叫绘画艺术疗法,有的用户很难用语言表达自己的心理状态,咨询师就会请他们绘画,从画中看出他们的心理状态。然而不是每个用户都有绘画的能力,如果在心理咨询中加入盗梦师,用户就可以通过表述来产生简单的画面,经过用户认可后,可以用作心理分析的素材。
AIGC 和元宇宙应该会有非常棒的结合,因为元宇宙相当于重新创造一个载体和环境。元宇宙的部分定义是含有多重场景,而创建场景本来会有非常高的成本,如果 AIGC 的技术越来越成熟,在创造各种新场景时,成本就会变得很低。
同时,AIGC 降低了内容创作的门槛,每个人在元宇宙里的自我角色都可以通过文字生成,所有人都能参与元宇宙环境的搭建,所以我觉得与元宇宙将会是非常有前景的结合。
我们还想过,AIGC 对于未来的内容平台形态会有很大的改变。我们在内部头脑风暴时谈过,现在网络小说是非常受欢迎的,网络小说可以每天更新,但受到绘画技能门槛的影响,几乎没有人能够做到每天更新几十页漫画。如果说 AI 生成图片的能力能够帮到创作者,将1000字的文章自动转化成几十幅图片,或者辅助漫画家根据自己已有底稿的风格快速生成更多的漫画,到了那个时候,可能人们每天看的就不是网络小说了,而是网络漫画——种种情况都有可能,整个生态需要大家一起来建设。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!