


“天空为什么是蓝的?萤火虫为什么可以发光?为什么双眼总是一起转动?”面对小朋友的十万个为什么,父母、老师总会借助储备的知识,或者查阅书籍解答疑问。
但随着内容的爆发性增长,想要得到一个问题精准的答案难度越来越大。
早年使用网上购物平台的用户,需要一步步根据商品的分类搜索,才能在海量的商品中找到适合自己的商品。
2022年的双十一,普通的消费者不仅可以轻轻松松就筛选出自己想要的商品,还会收到非常符合自己喜好的商品、直播的推荐。
这背后隐藏了推荐系统的变迁,在小朋友问父母问题的场景里,父母其实就充当的是小朋友的推荐系统,但普通人的知识储备毕竟有限。互联网时代,有了搜索引擎,但还不足够。
再后来,AI技术的兴起,帮助了推荐系统大步前进,无论是购物平台的商品推荐,直播平台的主播推荐,还是视频平台的视频内容推荐,越来越多的人开始感叹,AI更懂自己。
AI推荐系统,也默默成为了互联网公司业务中重要的组成部分。数据显示,在一些全球大型在线网站上,即使推荐内容的相关性仅提高 1%,其销量也会增加数十亿,AI推荐系统无疑是藏在众多互联网应用背后的高价值系统。
不过,高价值的AI推荐系统目前还有被少数公司负担得起,如何才能实现AI推荐系统的普及?我们又合适才能拥有完美的AI推荐系统呢?
推荐系统背后的算力演进
推荐系统并不新鲜,互联网公司们为了能够提升业绩和客户满意度,十多年前就开始了推荐系统的研究与应用,早年间他们采用传统的方法,比如协同过滤等,CPU也足以满足那时推荐系统的需求。
但随着推荐系统应用需求和算法的演进,系统越来越复杂,需要更加强大的底层算力作为支撑,推荐系统的开发者发现一个问题,通信节点间的性能遇到了瓶颈。也就是说,在服务器达到一定的规模之后,继续增加服务器的数量已经很难提升推荐系统的效果。
这就促使推荐系统的推动者们寻找更强大且更合适的算力支撑。当然,这个过程中还有一个重要的推动力——AI。在推荐系统中引入AI之后,能够增加推荐系统的效果,但与此同时也让推荐系统变得越来越复杂。
一个典型的推荐系统,包含了召回、过滤等过程,AI的引入,需要使用越来越多的数据进行训练,以达到预期的效果。
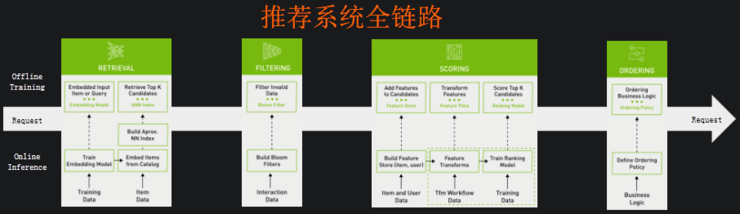
“推荐系统中引入深度学习之后,大家还是会习惯性先用CPU,但后来发现在深度学习的算法里多加几层神经网络可能就算不动了。”NVIDIA亚太区开发与技术部总经理李曦鹏在2022云栖大会期间说,“GPU此时有明显的优势,GPU的算力远高于CPU,同时GPU的带宽比CPU高非常多,我们的Hopper架构GPU的带宽已经达到3TB / s。”
但要加速推荐系统,不止是从CPU迁移到GPU这么简单。
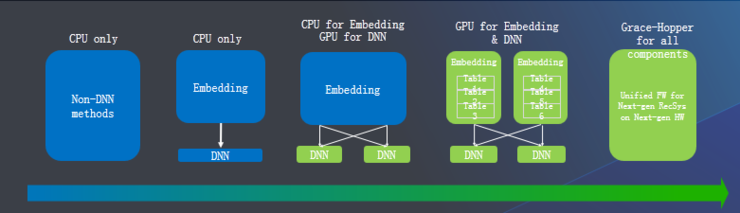
GPU如何加速AI推荐系统?
推荐系统中AI的引入,让推荐系统变得更加复杂的同时,对算力的需求也呈现出指数级的上升。
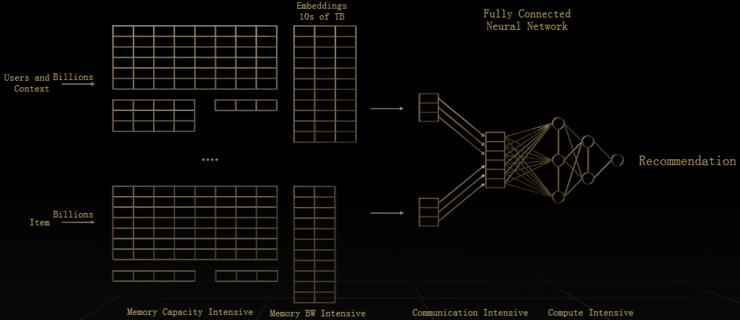
在推荐系统中,有大量的嵌入表(Embedding),包含各种推荐系统所需的特征,比如性别、年龄等等,嵌入表被用于将输入数据中的离散特征映射到向量,以便下游的神经网络进行处理,大小可以达到TB级。嵌入表通常是内存带宽和容量密集型,对于计算的需求不大,需要很大的内容容量和带宽进行快速读取,这对于CPU而言是一个明显的挑战。
此时,采用GPU有两个显著的优势,李曦鹏说:“一个是GPU的内存带宽远高于普通服务器,另一个是迁移之后将原来节点上的通信从原来CPU和GPU的PCIe通信,变成了GPU和GPU之间的NVLink通信,速度提升几倍。”
接下来,就需要用AI模型进行计算,此时可能是计算密集也可能是内存带宽密集。更麻烦的是,由于模型越来越大,超出了GPU板载的存储容量,没办法存储完整的模型,需要把它分块,嵌入表就需要做模型并行,而DNN部分需要数据并行。在这个过程中,从模型并行到数据并行,需要做非常多数据交换,成了大量计算节点间密集的通信。
“推荐系统需要的不仅仅是GPU,而是加速计算。”李曦鹏指出,“加速计算不是一个简单的芯片或者硬件,而是一个包含硬件、软件以及上层应用的一整套解决方案。”
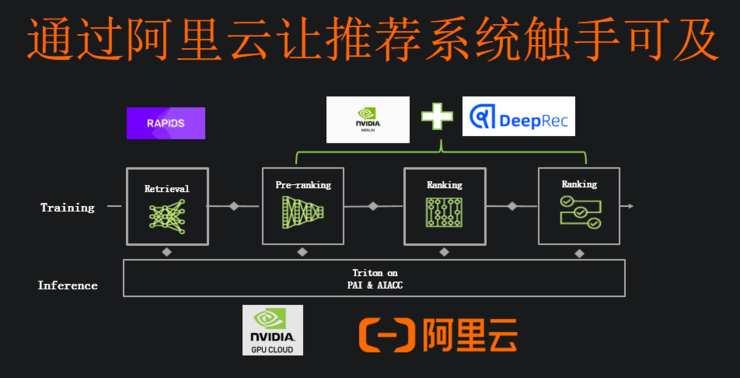
比如英伟达为推荐系统推出的NVIDIA Merlin。在预处理方面,NVIDIA Merlin NVTabular可以实现加速。
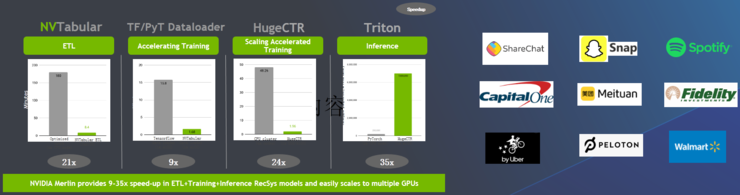
针对嵌入表,Merlin Distributed-Embeddings可以方便TensorFlow 2 用户用短短几行代码轻松完成大规模的推荐模型训练。并且,NVIDIA Merlin Distributed-Embeddings 的性能表现也十分突出,DGX-A100上的Merlin Distributed-Embeddings 方案比仅使用 CPU 的解决方案实现了惊人的683倍加速。
NVIDIA Merlin还有HugeCTR的开源框架,目标是优化 NVIDIA GPU 上的大规模推荐。
也就是说,NVIDIA Merlin是一个针对推荐系统,近似于一个端到端的解决方案。
即便如此,推荐系统的普及依旧面临着巨大的挑战。
普及推荐系统的两大挑战
推荐系统作为高价值的AI系统,普及面临的两大挑战就是差异化以及高门槛。
“我们充分理解,由于业务的不同于推荐系统有很大的差异,我们会尽量把NVIDIA Merlin的功能进行模块化,客户可以根据需求选择不同的模块,使用的模块越多,效果也会更好。”李曦鹏说,“我们通过Merlin的模块化解决问题的同时,也通过和像阿里云这样的云计算服务商合作推动推荐系统的普及。”
不同的推荐系统使用的算法并不相同,虽然如今AI大模型的应用越来越广泛,并且大模型在美国人工智能学术界将其称为基础模型(Foundation Model),但这并不意味着所有推荐系统都需要使用大模型。
李曦鹏的观点是,大模型提供一个更大的尝试空间,其表征能力也更强,所以主流公司的模型越来越大,但主流公司也会有一些小的业务,或许也会有一些小的模型。如今主流的公司已经过渡到了GPU方案,比较重点的业务是全GPU的解决方案。所以,在算法上,即便主流公司也有阶梯。
“先进模型对于中小企业来说收益可能没那么大,因为他们的业务体量没那么大,而通过云计算的方式,以及GPU的解决方案,可以帮他们降低门槛和成本。”李曦鹏进一步表示。
差异化需求之外,推荐系统普及的另一大挑战就是高门槛。
“互联网巨头有成百上千人的团队在做推荐系统,中小企业很难投入这么多。但通过我们和阿里云这样有能力的云服务提供商合作,给中小公司开放一些更高级的API,有一些预定义的模型能够实现不错的推荐系统,投入一两个数据科学家,这将有利于推荐系统的普及。”李曦鹏说。
推荐系统的普及,将能够代表加速计算巨大的想象空间。
10年100倍,加速计算价值千亿的巨大空间
过去几十年间,得益于摩尔定律,算力在持续增长。但如今摩尔定律已经放缓,从最初每年1.5倍性能的提升,下降到如今每年1.1-1.2倍的提升。摩尔定律带来的算力提升已经难以满足包括推荐系统在内应用对算力指数级的性能增长需求。
“接下来的十年,所有的计算任务都将被加速。我们已经加速了世界上5%的计算任务——价值百亿美金。加速计算会降低计算任务的成本,提高能源利用率,给工业界带来更多的能力做更多的事情。”英伟达CEO黄仁勋在今年十月时表示。
仅看推荐系统,Mordor Intelligence 发布的数据指出,推荐系统整体市场将从2020 年仅为 21.2 亿美元提升至2026年的 151.3 亿美元。加速计算显然具有数千亿的市场空间,但要加速如此之大的市场,需要性能的持续提升。
加速计算的目标是保持每年1.6-1.7倍的性能增长,5年可以实现10倍的性能提升,10年就可以实现100倍的提升,这与摩尔定律10年可以实现的4倍性能提升形成了显著的差异。
前面已经提到,加速计算不止是从硬件的层面实现性能的提升,更加强调从硬件到软件再到应用的加速,实现性能的飞跃。
实际上,加速计算的价值已经在AI应用中体现出来,以前训练一个AI模型,周期以周来计算,调整模型训练至少又得等一周,而现在,即便模型越来越大,训练一个模型的时间也只需要几分钟了。
“几年前难以训练的大模型,早已成为了过去式。更多更大规模的工作负载等着去加速。”李曦鹏对于加速计算能够实现目标也十分有信心。小编
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!