
Kaggle TravML 粒子追踪挑战赛的颁奖仪式即将在 NIPS 2018 大会上进行。这个比赛不仅是机器学习助力其它领域科学研究的经典案例,而且来自中国台湾的 Pei-Lien Chou 也获得了挑战赛的第二名。
TrackML 粒子追踪挑战赛介绍
为了探索我们的宇宙是由什么构成的,欧洲核子研究中心的科学家们正在碰撞质子,本质上就是重现了小型大爆炸,并且用复杂的硅探测器仔细观察这些碰撞。

虽然编排碰撞和观测已经是一项巨大的科学成就,但是分析由实验产生的大量数据正成为一个最为严峻的挑战。
实验的速率已经达到了每秒数亿次的碰撞,这意味着物理学家必须每年对数十千兆字节的数据进行筛选。而且,随着探测器分辨率的提高,需要更好的软件来实时预处理和过滤最有用的数据,从而产生更多的数据。
为了帮忙解决这个问题,一个在 CGRN(世界上最大的高能物理实验室)工作,由机器学习专家和物理学家组成的小组,已经与 kaggle 和著名的赞助商合作来回答这个问题:机器学习能帮助高能物理学发现并描述新粒子吗?
具体来说,在这次竞赛中,参赛者们面临着一个挑战,那就是建立一个算法,它需要能够从硅探测器上留下的 3D 点快速重建粒子轨迹。这一挑战包括两个阶段:
●在 kaggle 上的调整精确度的阶段是从 2018 年 5 月到 2018 年 8 月 13 号(获奖者将在 9 月底公布)。在这一阶段,主办方只关注最高分数,而不会管得到这个分数需要运行的时间。这个阶段是一个正式的 IEEE WCCI 竞赛(会议地址在里约热内卢, 2018 年 7 月举办)。
●生产阶段将在 2018 年 9 月开始,参与者将提交他们的软件,由平台进行评估。激励取决于系统达到良好的分数时,评估的吞吐量(或速度)。这个阶段是一个官方的 NIPS 竞赛(会议地址在蒙特利尔,2018 年十二月举办)。
在 Kaggle 比赛官方页面(https://sites.google.com/site/trackmlparticle/)上可以获得精确度调整阶段的所有必要信息。
挑战赛亚军 Pei-Lien Chou 访谈
Pei-Lien Chou 是 TrackML 粒子追踪挑战赛亚军。他带领了一只研究用深度学习方法解决图像相关问题的团队参加了这次比赛。Pei-Lien Chou 在视频监控领域有 12 年经验。他在国立台湾大学读取了数学学士学位,并在中国台湾国立清华大学攻读了语音信号处理的硕士学位。
在这次竞赛中,kaggle 参赛者被要求建立一个算法,这种算法能够快速地从硅探测器上留下的3D点重建粒子轨迹。 这是这个比赛两阶段挑战的一部分。在 2018 年 5 月至 8 月 13 日的精确度调整阶段,只关注最高分数,而不考虑评估需要的运行时间。第二阶段是正式的NIPS竞赛,这个阶段重点关注准确性和算法速度之间的平衡。
比赛结果出炉后,Kaggle Team 与 Pei-Lien Chou 进行了访谈。
基础知识
在参加这次比赛前,你的背景是什么?
我拥有数学学士学位和电子工程硕士学位。从去年开始,我就一直是以基于图像的深度学习的工程师。
你是如何开始在kaggle上参加比赛的?
大约 1.5 年前,我加入了 Kaggle 来练习深度学习,这对我的工作帮助很大。我在第一次比赛中就进入了前 1%,在接下来的下一次比赛中就赢了。参加 kaggle 比赛真令人兴奋。
是什么促使你参加这次比赛的?
起初我没有注意到这次比赛,因为它不是基于图像的,尽管我在这次比赛中尝试了一些点云方法。但当我意识到组织者是欧洲核子研究中心(CERN),也就是制造黑洞的那些人时,我毫不犹豫地加入了。
有关技术
你的方法是什么?
我的方法是从一个简单的想法开始的。我想建立一个模型,这个模型可以把每个事件的所有轨道(模型输出)映射到检测器中(模型输入),就和我们使用 DL 解决其他问题的方法一样。
如果一次事件有 N 个命中(通常 N 在 100k 左右),则输出可以很容易地用 NxN 矩阵表示,如果 i 和 j 在同一轨道上,则 Mij=1,否则为 0 。但是模型太大了,所以我把它分成了最小的单元:输入两个点击并输出它们的关系(如图 1 )。和真实的只连接相邻的点的“连接点”游戏不一样,为了稳健性,我连接了所有属同一轨道的点。此时,我已经准备好了参加这次比赛。 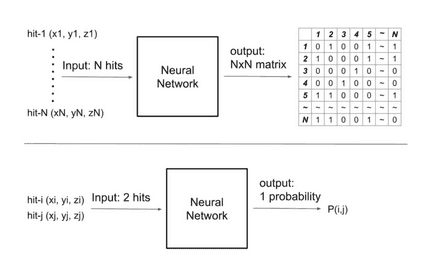 你是怎么做的?
你是怎么做的?
首先,我使用命中位置(x,y,z)作为输入,通过 10 个项目的训练,很容易获得 99% 的准确率。但我很快发现这并不足以重建轨道。问题是,即便误差率 0.01,对于给定的命中,负对数目可以达到 0.01*100k = 1000,而实际的负对数目在 10 左右(轨道的真实平均长度)。但是为了得分,我们需要真实的数据和模型有超过 50% 的部分是重叠的。
接下来怎么做?
我第一次在自己的计算机上尝试运行的时候就得到了 0.2 的得分,这与当时的公共内核相同。我猜也许我做到 0.6 就能赢,并且希望通过我的方法可以做到。天晓得!
你是如何得到更好的预测结果的?
我尝试了很多方法,并且我的进步大大超出了我的预期。
●采用更大的模型,更多的训练数据。
具有 4k-2k-2k-2k-2k-1k 神经元的 5 个隐层 MLP,总共训练 3 组,5310 次事件,大约 24 亿个正例对和更多的负例对。
●选取更好的特征
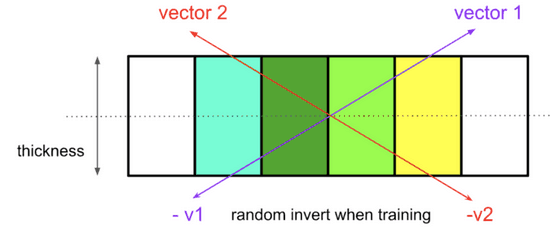
一对 27 个特征:x,y,z,count(cell),sum(cell.value),两个单位向量来自神经单元,用于估计命中方向和训练时的随机反转(如图2),并且假设两个击中是线性的或螺旋形的 (0,0,z0),用前两个估计向量和曲线的切线计算 abs(cos()),并且最后一个是 z0。
●更好的负样本
多对接近正例对的负例对进行采样(也就是重点提高模型分辨相近的正例负例的能力),并且我做了一些很难负例的挖掘。
最后,在 0.97TPR 下,对于给定的命中,我平均得到了 80 个负对,并且只有 6 个假阳性对的概率大于真阳性对的平均值。并且只有 6 个负对的概率大于正对的平均值。
你是如何重建轨迹的?
到目前为止,我有一个不太精确的 NxN 关系矩阵,但如果我把它们全部用上,就可以得到很好的轨迹。
重建:找到 N 个轨迹
1. 以一次撞击作为种子(例如第 i 次命中),找到最高概率(这个概率大于阈值)对 P(i,j),然后将第 j 次撞击添加到轨道。
2. 求最大值 P(i,k)+P(j,k),如果两对概率大于阈值,则将第 k 次撞击添加到轨道 。
3. 测试新的命中,看看它是否和 x-y 平面上的圆匹配,圆是有两三次命中的轨迹后面的圆。(这句话也不是很懂)(没有这一步,我只能得到0.8分)。在轨迹有两次或者三次撞击后,根据现有的命中在 x-y 平面中组成一个圆,然后看新一次的撞击是否在这个圆内
4. 找到下一个撞击,直到没有更多的撞击符合这个圆。
5. 循环步骤1用于所有 n 次撞击(如图 3)。
合并扩展
1. 计算所有轨道的相似度作为轨道的质量,这意味着在轨道中,如果所有撞击(作为种子)对应的轨道相同,则轨道的合并优先级较高。(图 6)
2. 首先选择高优先级轨迹,然后通过放松重构步骤中的约束条件对其进行扩展。
3. 循环
其它的工作
我最后添加了 z 轴约束和两个模型的集成,得到了 0.003 改进。
我还尝试应用 PointNet 在预测的样本中找到轨迹并细化跟踪。这两种方法都表现良好,但没有更好。
 图 3:用 6 个命中重建一次事件的例子 图 6:合并优先级确定的一个实例
图 3:用 6 个命中重建一次事件的例子 图 6:合并优先级确定的一个实例
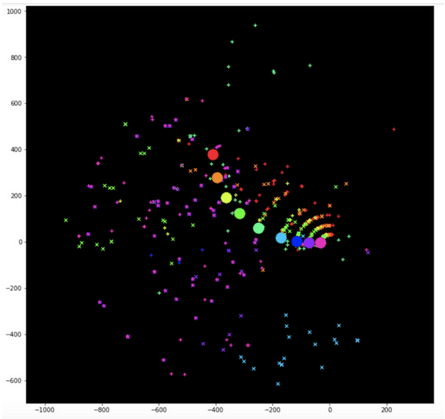 图 4:x-y 平面上的种子(大圆)及其对应的候选(匹配颜色)。很明显种子是在一条轨道上的。
图 4:x-y 平面上的种子(大圆)及其对应的候选(匹配颜色)。很明显种子是在一条轨道上的。
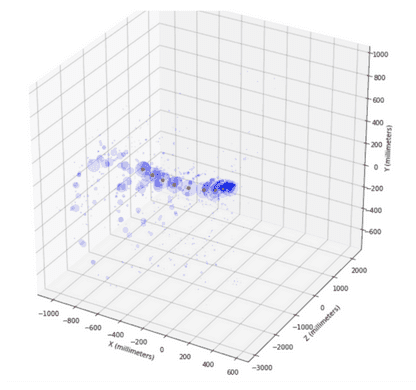 图 5:每个命中的直径与九个真命中(红色)的预测概率之和成正比。
图 5:每个命中的直径与九个真命中(红色)的预测概率之和成正比。
这里是一个参考的内核。
我把这个过程称为无止境的循环,这离我原来的想法很远。尽管如此,当我的准确率超过 0.9 的时候,我还是很高兴。
训练和预测获胜方案的运行时间是多少?
你知道,我的训练数据有 5k 个事件,而且我还要做难的负例的挖掘。对于每个测试事件,我必须预测 100k*100k 对,重建 100k 轨道(实际上在获胜解决方案中是 800k+),合并它们并扩展到 10k 轨道。所以运行时间是天文数字。在一台计算机上再做一次这项工作可能需要几个月的时间。
赛后感想
DL 适合这个主题吗?
在我看来,这取决于目标能否被很好的描述。如果目标可以被描述,那么基于规则的方法应该更好。换句话说,在这种竞赛中,使用聚类的方法就可以得到0.8的准确率,所以用深度学习来做简直是自找麻烦。但是这依然是有趣的。
对于刚刚开始从事数据科学的人,你有什么建议吗?
你如果还没有加入 Kaggle,那一秒钟都不要耽搁,现在就加入吧!
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!