
近日, 在第 68 届年度 IEEE 国际电子器件会议 (IEDM) 上,台积电发表了题为“用于移动SoC和高性能计算应用的3纳米CMOS FinFlexTM平台技术具有更高的功效和性能”的论文。WikiChip 在这篇论文中发现,虽然逻辑电路仍在或多或少地沿着历史轨迹前行,但 SRAM 在这方面的路线似乎已经完全崩溃。对于新的 N3E 节点,高密度 SRAM 位单元尺寸并没有缩小,依然是 0.021 m ,这与 N5 节点的位单元大小完全相同。但N3B 实装了 SRAM 缩放,其单元大小仅有 0.0199 m ,相比上一个版本缩小了 5%。由此可见,SRAM的微缩性瓶颈已经到来。


这意味着什么?
随着AI算力需求的不断提升,除了传统冯·诺伊曼架构面临着多重瓶颈外,传统存储器件也到达了尺寸的极限,摩尔定律面临失效。依靠先进制程工艺不断缩小器件面积、同时提升算力的方式似乎已经走入死路。 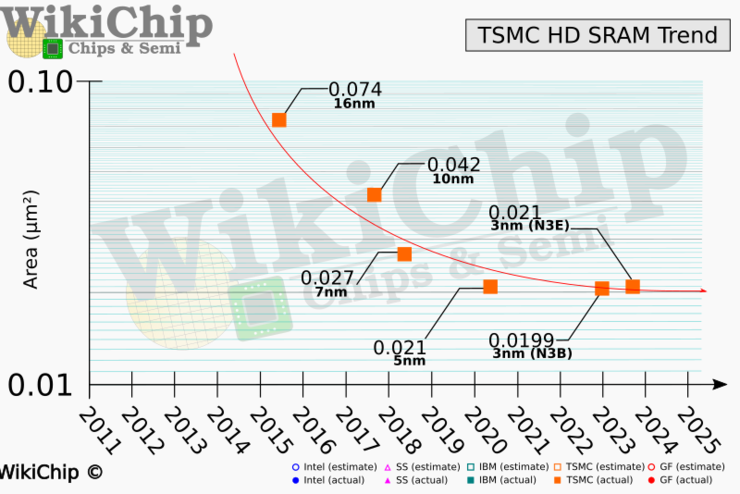
是什么限制了AI大算力的发展?
北京大学集成电路学院院长蔡一茂认为,一方面是器件层面上的瓶颈,一些传统存储器例如SRAM, Nand Flash 等,由于器件本身微缩性差,支撑芯片制造的尺寸缩小接近物理极限,也就是通常所说的摩尔定律面临失效的风险;其次是架构瓶颈,即计算与存储单元分离带来的数据交换存在存储墙和功耗墙问题。 第三则是能耗瓶颈,基于目前器件尺寸越小且密度越大的趋势,若产品功耗无法等比例缩小或大致缩小,那么其功耗便会面临较大问题。数据显示,预计到2040年,大数据1040次运算需要1027焦耳的能耗。此外,除了工艺之外,冯·诺依曼架构的瓶颈可说是从底层上限制了神经网络和AI智能芯片的进一步发展。
近年来,围绕AI芯片大模型算力突破进行的尝试很多,而当前普遍认为突破AI算力困境的方式,有着两条清晰的路线:架构创新与存储器件创新。
2021年 5月14日,国家科技体制改革和创新体系建设领导小组第十八次会议提出了面向后摩尔时代的集成电路潜在颠覆性技术。用架构和技术来划分,可以分成四类:
一、全新技术与架构下的基础物理探索(量子计算机)
二、搭“摩尔”便车在冯架构下进行应用创新(GPGPU AI芯片)
三、基于现行架构探索非“硅”技术(存储器创新)
四、基于现行硅技术探索非冯架构(架构创新)
架构创新的道路似乎是可行的。2020年初,阿里达摩院发布《2020十大科技趋势》报告显示,在人工智能方面,计算存储一体化,类似于人脑,将数据存储单元和计算单元融为一体,能显著减少数据搬运,极大提高计算并行度和能效。
该报告指出,对于广义上计算存储一体化计算架构的发展,近期策略的关键在于通过芯片设计、集成、封装技术拉近存储单元与计算单元的距离,增加带宽,降低数据搬运的代价,缓解由于数据搬运产生的瓶颈;中期规划是通过架构方面的创新,设存储器于计算单元中或者置计算单元于存储模块内,可以实现计算和存储你中有我,我中有你;远期展望是通过器件层面的创新,实现器件既是存储单元也是计算单元,不分彼此,融为一体,成为真正的计算存储一体化。近年来,一些新型非易失存储器,如阻变内存,显示了一定的计算存储融合的潜力。
从存储器入手,能否打破AI大算力困局?
计算存储一体化也被称为存算一体化,国内外早已有不少玩家入局。但各家采用的存储器类型不尽相同。由于该架构带来低功耗的特性,多被应用于中小算力,而试图打破大算力困局的企业则选用了一些新型非易失存储器来抵消传统存储器的天然劣势。
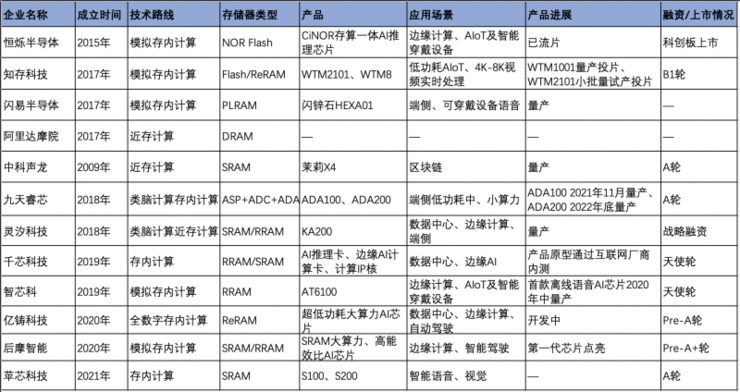
(图片来源:与非网)
IEEE Fellow Lee 博士认为,SRAM的问题在于它的静态电流非常大,面积也比较大,所以并不适合做大算力的存算一体化芯片,因为当大量的SRAM堆积在芯片上时,会产生一种被称为DI/DT的工程性问题,也就是电流在短时间内大量变化,非常具有挑战性。
GraphCore是英国一家做AI训练芯片的公司,他们将198兆的SRAM堆叠在训练芯片上,采用分布式的设计。即使这样,GraphCore还要借助台积电的新工艺,专门打造另外一个晶圆,布满充电电容,以解决DI/DT的问题。这导致了生产成本十分昂贵。
另外,Lee 博士补充道:“ SRAM的体积是比较大的,我们知道要想提高算力就必须要提高器件的密度,从这点来说,SRAM是不太适合做大算力场景的。也正因于此,采用SRAM的这些公司都在基于边缘端做小算力的场景,比如语音识别、智能家居的唤醒、关键命令词的识别等。”
国内也有已经量产的芯片商基于另一种传统存储器件闪存(Flash)来做存算一体。据了解,该企业是利用美国SST公司基于Flash的存算一体IP进行设计。Flash因为依靠在沟道里面trap电荷的方式进行记忆,所以当沟道的尺寸随着工艺缩小的时候,就会产生很多稳定性的问题,导致Flash在22纳米以下很难做到稳定,目前业内提升Flash密度的方式普遍是通过3D堆叠的方式来实现,也不太适合做大算力的场景。
基于以上两种普遍认知,行业内将目光逐渐转向了新型存储器。比如近期英飞凌宣布其下一代 AURIX ™微控制器 (MCU)将采用新型非易失性存储器 (NVM) RRAM (ReRAM);STT-MRAM和SOT-MRAM也已在各种PIM架构中得以实现。相信未来AI大算力的困境将会因这些新型存储器的创新而改写。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!