
ChatGPT正在变成一场竞赛,中国企业争先恐后抢发“自研”的ChatGPT,争当所谓的赢家。但实际上,ChatGPT并非竞赛的终点,而是起点,只是堪堪拉开了人工智能新时代的一角序幕。这场对于通用人工智能的角逐,实际上是一场无尽的长跑、而非百米冲刺。假设真有一个这样新的时代到来,哪些力量可以一争高下?此前,小编盘点了追赶「ChatGPT」的学术、创业与大厂三派力量:学术一派,清华大学一骑绝尘;创业一派,王小川、王慧文财大气粗;大厂一派,则以百度、阿里为代表,它们在 2020 年就已经开始布局大模型研究。(推荐阅读:《ChatGPT群雄逐鹿:陆奇屠龙,号令天下;小川不出,谁与争锋》《AIGC:我不是元宇宙的附庸品》)其中,大厂派有技术、有资源、有产品,最为突出。如同微软之于 OpenAI,谷歌之于 DeepMind,大厂与科研团队合作成为群雄逐鹿的主要形式。由于 ChatGPT 的成功背后是强科研投入与新产品优化的结合,大厂的资源(数据、算力)与产品平台,将扮演至关重要的角色。有小型初创团队就告诉小编,大厂下场是意料之中,国内 AI 小公司囿于客观条件,如 OpenAI 依靠微软也是它们发展与生存的必要条件。人工智能的市场很大,每个公司都可以在其中找到自己的位置,区分的关键点其实只在于:能否在未来的持续竞争中保持投入,并最终以最低的成本提供最好的体验。
01ChatGPT 的本质
关于 ChatGPT 的讨论中,有一个常见的问题是:OpenAI 的 ChatGPT 这么火,我们(中国)还有机会吗?就模型来看,对 ChatGPT 来说,语言大模型是起码的敲门砖。作为 ChatGPT 的技术基础,GPT-3 在 2020 年首次面世,以 1750 亿参数,在多项语言任务(包含文字理解、文本生成、智能问答、文本续写、文本总结等等)中取得优异表现。从此,以 GPT-3 为代表的语言大模型成为自然语言处理研究者(NLPer)的兵家必争之地。在区分各家的 ChatGPT 实力时,大模型的实力也就成为重要考量。科技大厂中,目前在大模型上有布局的企业包括阿里(通义)、百度(文心)、华为(盘古)等。自研大模型的训练难度并不低,涉及数据、算法与算力三个维度,传言全球不超过 200 人能从头自研、训练一个大模型:•数据层面:对于深度学习,当样本数量较少时,不正确的模型复杂度会导致过拟合和欠拟合。当样本数量增多时,这种风险就会变小,因此,大模型对数据的数量与质量要求都极高。GPT-3有1750亿参数,数据量达到45TB,表现出色。而对数据的采集、清洗与标注,需要人力,也需要资金。•算法层面:除了海量数据,大模型训练对 AI 框架的深度优化和并行能力提出更高要求。这一块对 AI 人才的科研与工程能力要求最高,也是近日各大厂抢人才的源头。•算力层面:这一块参差不齐,但公开消息表明,为了 OpenAI 训练 GPT-3,微软帮忙建设了一个搭载 1 万张显卡,价值 5 亿美元的算力中心,模型在训练上则消耗了 355 个GPU年的算力,单独一次的训练成本则是 1200 万美金。OpenAI 的 GPT-4 还未揭晓,面对较为确定的不确定,企业的 AI 底层建设也显得尤为关键,算力就是其中之一。算力层面,据小编了解,早年各大厂虽然如火如荼地建设各自的 AI Lab,但在计算资源的投入上却参差不齐,还有的知名大厂连一万张显卡都没有。更多详情可添加VX:Fiona190913,持续关注大厂 ChatGPT 的后续报道。除了显卡数量的不足,企业与企业拉开差距的地方还可能体现在:往期算力积累,以及运用有限算力资源训练无限大模型的应对能力。这波 ChatGPT 中,除了「利好英伟达」的声量,国内众多云计算厂商与计算服务商的声量微弱,本质在于:芯片需要与算法适配。也就是说,有算力固然重要,但找到适合大模型训练、能让大模型训练的芯片更为重要。尤其是前两年大模型的风潮中,部分大厂由于成本顾虑、没有入局,已经落后一大截,难以追赶。模型与算力的高压之下,团队与团队之间的天花板其实已昭然若揭。在这波ChatGPT浪潮中,阿里颇为低调,但因为在大模型和基础设施上长期积累的优势,阿里是一个绝不容忽视的重要玩家,一举一动都牵动着整个AI行业的神经。
02长跑者阿里
诚如上文所言,大模型的研究难度极大,门槛极高。大多数中小企业在声称「自研大模型」时,往往是基于已开源的大模型与数据集,用监督学习算法进行微调,获得一个新的模型后,然后基于这个模型来开发产品。虽然性价比高,但由于底层基础差异化不大,上层建筑在产品体验上也难以区分开来。这就造成了,若要从数据、算法与算力的底层部署开始深耕,大模型的开发注定是大厂与大厂之间的军备竞赛(人力、资本、数据)。而且,开始地越早,越有先发优势。
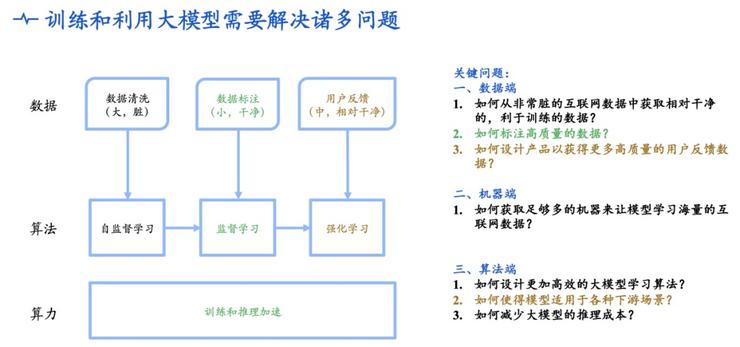

图注:大模型训练需要解决的数据、算法与算力难题(源于心辰科技分享)
作为国内最早入局语言大模型的团队之一,阿里在超越 ChatGPT 上有领先其他团队的优势,也意味着其在数据、算法与算力上有先行试错与解决问题的经验,甚至在产品落地上有探索与实验。公开资料表明,阿里在大模型的研究上有深厚基础:•阿里早在 2020 年 1 月前便开始研发多模态大模型(MultiModality-to-MultiModality Multitask Mega-transformer,简称为「M6」),6 月研发出 3 亿参数的 M6,有了一个好的开端;•2021 年是阿里大模型的快速腾飞时期:3 月发布千亿参数多模态大模型 M6,4 月发布首个中文语言大模型 PLUG(270亿参数,号称中文版「GPT-3」),5月发布万亿参数大模型 M6,10 月又发布 10 万亿参数大模型 M6……•2022 年,阿里「通义」大模型体系出世,囊括被谷歌、微软、DeepMind、Mega等国际顶尖团队引用的通用统一模型M6-OFA 。当年云栖大会期间推出国内首个 AI 模型社区魔搭 ModelScope,贡献 300 多个优质 AI 模型,百亿参数以上大模型超过10个……对比国内其他互联网科技大厂在大模型上的投入与产出,阿里的模型研究在前沿领域走得最远,成果间隔产出时间最短,中文语言模型意识突出,多模态结合与通用架构的研发落实也最透明(尤其体现在魔搭社区上),很难不被人关注。单看阿里的大模型成果数量,实际不足以窥见它的研发差异化。小编试着从以下几个角度分析:首先,阿里大模型从M6、PLUG发展到通义,在训练方法上已经历经了一个明显的转变:从 BERT 到自回归。国内的大模型开发,尤其是 2021 年出现的许多大模型,基本是以 BERT 为先锋基础,而阿里在 2021 年开始从 BERT 转向自回归,复刻 GPT-3。鉴于大多数对 GPT-3 的复刻均以失败告终,阿里想必也是试错多次才成功。目前,在魔搭社区上,我们可以看到复刻成功的 GPT-3 多个中文版本,参数从base直到175B。这些版本已经开源开放,最高的下载量达到72k,可见受到 AI 算法开发者的广泛肯定。
图注:中文 GPT-3 在魔搭社区上的页面(源于魔搭社区)
Google发布的 BERT(Bidirectional Encoder Representation from Transformers)是首个预训练大模型,BERT 没有采用传统的单向语言模型,或者将两个单向语言模型进行浅层拼接的方法进行预训练,而是采用MLM(masked language model)以生成深度的双向语言表征。OpenAI 发布的 GPT-3 后来者居上,GPT-3 延续了单向语言模型训练方式,但是将模型尺寸扩充到1750亿参数。GPT-3聚焦于更加通用的NLP模型,解决了目前BERT类模型的两大缺点:对领域内有标签的数据过分依赖,以及对于领域数据分布的过分拟合。BERT 与自回归的区别在于,基于 BERT 架构训练的语言大模型更擅长「理解」,而基于自回归(即 GPT-3 的方法)更擅长「生成」。达摩院成为国内少有的布局自回归的大模型团队。此外,值得注意的是,谷歌的一项研究(论文「Emergent Abilities of Large Language Models」)表明,模型的规模从 700 亿参数到 2800 亿参数会有明显质变,验证了千亿级参数是大模型从量变到质变的一个坎。而阿里是国内第一个做出千亿参数大模型的团队。其次,从大模型背后最关键的算力技术来看,阿里在训练大模型上的工程积累也有明显提升,这主要体现在算力的部署上。从 2020 年 GPT-3 的出现以来,大模型「大力出奇迹」就成为 AI 领域公认最有前景的方向之一,但大模型的训练难度大,算力要求高。尤其当模型的参数超过万亿、十万亿(如阿里的 M6),训练过程中,已经不是单纯靠堆算力就行。实验表明,工程师在算法上下功夫,是可以降低计算能耗的。例如,GPT-3 推出两年后,2022 年 Meta 参照它所研发的 OPT 模型计算量就降低到了 1/7。2022 年还有文章表明,2018 年需要几千块 GPU 训练的 BERT 大模型,如今只需要单卡 24 小时就能训练完。类似的例子不胜枚举。提升训练速度、降低训练成本的途径主要有两种,一种是注重对训练数据的优化,而非参数规模;另一种则是依赖算法与架构的创新,如 ALBERT、「孟子」等工作。而这两种方法,都对研发团队的技术经验有要求。据公开资料,阿里在大模型训练这块有「两把刷子」。一方面,阿里从数据、算法上入手,降低计算能耗。2021 年 5 月,阿里达摩院的团队仅用 480 卡 GPU 就训练出万亿参数多模态大模型 M6,与英伟达、谷歌等公司实现万亿参数规模相比,能耗降低超八成。同年 10 月,他们把 M6 的参数规模扩大到 10 万亿,训练号称只用了 512 卡 GPU。另一方面,阿里在云计算上加大投入,专门建设了一个智能算力系统——飞天智算平台。飞天智算融合了通用计算、异构计算等多种计算形态,单集群算力峰值高达12 EFLOPS,对万卡规模的 AI 集群提供无拥塞、高性能的集群通讯能力,其中专设的机器学习平台 PAI 部署了分布式训练框架 EPL(训练 M6 的功臣)能大幅度能耗、提升速度。一个公开的数据是,截至 2023 年 1 月底,ChatGPT 官网总访问量超过 6.16 亿次,每一次与 ChatGPT 的互动,算力云服务成本在 0.01 美元,如果用总投资在 30.2 亿元、算力 500P 的数据中心支撑 ChatGPT 的运行,这样的数据中心至少需要 7-8 个,基础设施投入数以百亿。如果不是依托微软的 Azure 云平台,ChatGPT 难以提供稳定服务。而阿里云在云计算产品这块,是国内第一、全球第三,对于之后支持类似 ChatGPT 的产品有天然优势。最后,阿里从大模型研究中体现的另一个特点,是「模型服务」与「中文生态建设」的意识。阿里注重大模型的落地,解决行业问题,在 2022 年 9 月推出「通义」大模型系列,划分三层:模型底座层、通用模型层和行业模型层。

图注:阿里通义大模型架构
模型底座上,他们以统一学习范式OFA(One-For-All)等关键技术为支撑,在业界首次实现模态表示、任务表示、模型结构的统一。M6-OFA 模型在不引入新增结构的情况下,可以同时处理图像描述、视觉定位、文生图等10余项单模态和跨模态任务。2021 年,OpenAI 推出文生图产品 DALL·E,其背后的关键技术是为文字与图像两种模态搭建桥梁的架构 CLIP。阿里达摩院是国内最早注意到 CLIP 对多模态影响的团队,投入研发,在2022年推出了中文版 CLIP(ChineseCLIP),对中文跨模态有重要作用。这为提升模型泛化能力有很大影响。举例而言,在文本、图像、语音、视频等模态结合的基础上,任务表示和结构统一的设计可以让上层模型不仅服务单一领域(如电商),还能服务其他领域(如金融、医疗、法律等等)。在中文生态的建设上,阿里的另一个贡献是建设魔搭社区,对标 HuggingFace。魔搭社区成立不到半年,在促进中文 AI 模型的开源上,以清晰的文档格式、丰富的模型种类、优质的中文模型(包括大模型)吸引了许多开发者。语言大模型的研究中,中文语料的短缺一直是行业难题。阿里带头贡献自家模型和数据集,促进 AI 应用开发,推广 AI 产品与用户的交互,促进整个中文语言研究的语料积累,并开源布公。用一位 AI 从业者的评价来形容,在国内追赶 ChatGPT 的前赴后继中,阿里武器齐全,数据、算法、算力三风具备,场景丰富,很难缺席和失败。
03假如 AIGC 时代全面来临
ChatGPT 虽然是一款智能对话机器人,但提供问题的能力,本质上还是文本生成,即 AIGC 的一个分支。无论是文本生成,还是图像生成、文生图、文生视频,甚至早已出现的各类语音生成,其技术的成熟与产品的薄发,都代表了人工智能生成数字内容的无限想象力。AIGC,正在造出一个新的赛道,正在改变传统产品的形态。比如,语音音箱的市场将被激活和重塑。以天猫精灵为例,其家庭用户超过4000万,月交互次数超过80亿,这还是在原来AI对话能力下的情况。通过大模型的底座训练,再结合声音这种富有情绪的信息媒介,天猫精灵有可能升级成真正的家庭伴侣,成为包含知识、情感、个性、记忆的全新家庭交互系统,展现超乎期待的能力。更重要的是,我们正在一个转折点上,AI不仅是产品,更有可能变成一种服务「AI as Service」,这将成为科技大厂竞争的核心战场。如何对外输出AI能力,怎样以最低的成本来提供最好的体验,将成为大厂竞争的关键。擅长「为他人做嫁衣」的阿里,已经通过算力基础设施为客户减少研发成本。从之前情况来看,目前国内只有阿里一家具备支撑超万亿参数大模型研发的「云 + AI」全栈技术实力。同时,因为过去支持超大模型研发的经验,阿里练出了AI训练提效11倍、推理提效6倍的独家本领。这种「低碳训练」技术,后续无疑也将为阿里云的客户提供具有高性价比的AI算力。在提供产品体验上,阿里的策略不是与生态链伙伴抢终端客户,而是先做大生态。魔搭社区就是一个典型例子,让没有自研能力的 AI 开发者或中小企业在魔搭平台上就能体验五花八门的 AI 模型,构建自己所需的AI能力。换言之,在 AI 深入行业的蓝图上,阿里的策略貌似也是为 B 端客户提供技术服务,通过 B 端去触动 C 端,形成一张网。在魔搭社区,广大开发者或者中小企业主可以下载使用免费开源的模型,可以对模型进行二次优化,无需布卡就能快速生成基于 AI 模型的服务应用,使 AI 真正成为一种触手可及的生产要素。截至现在,已经有澜舟科技、深势科技、智谱AI、启智社区、哔哩哔哩、IDEA研究院等等十多家知名机构贡献模型,魔搭社区模型量已超过600个,较 2022 年 11 月上线之初翻了一番。除去用大模型服务自己的淘宝、天猫、天猫精灵、钉钉等等业务,阿里安心做一个 AI 时代的模型基础设施服务商,也不失为一个明智的选择。根据阿里 2022 财年全年财报,过去一年,阿里在技术相关成本费用上的投入超过 1200 亿元,全球设立 7 个研究中心,开源技术项目超 3000 个、开源活跃度国内企业排名第一,其中相当比例的投入进入人工智能领域。对于需要极高投入的 AI 研发来说,可以看出,阿里也具备了在这场长跑中坚持到底的决心。在最近一片喧嚣沸腾中,真正的主角可能还尚未亮剑,大戏才刚刚开始。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!