
第七届GAIR全球人工智能与机器人大会,于8月14日-15日在新加坡乌节大酒店举办。论坛由GAIR研究院、小编、世界科技出版社、科特勒咨询集团联合主办。这是国内首个出海的AI顶级论坛,也是中国人工智能影响力的一次跨境溢出。GAIR创立于2016年,由鹏城实验室主任高文院士、香港中文大学(深圳)校长徐扬生院士、GAIR研究院创始人朱晓蕊、小编创始人林军等人联合发起。历届大会邀请了多位图灵奖、诺贝尔奖得主、40位院士、30位人工智能国际顶会主席、 100多位 Fellow,同时也有500多位知名企业领袖,是亚洲最具国际影响力的AI论坛之一。
大会共开设10个主题论坛,聚焦大模型时代下的AIGC、Infra、生命科学、教育,SaaS、web3、跨境电商等领域的变革创新。在8月14日下午「大模型时代的超级基建」论坛上,UCloud董事长兼CEO季昕华分享了题为《中立云服务助力AIGC的发展》的主题演讲。
季昕华认为,判断一个大模型能不能做好主要有四个关键要素:一是资金密度;二是人才密度;三是数据密度;四是算力密度。
一家大模型公司如果没有一个亿美金,那基本上压力就会比较大。因此,大模型被称为是互联网的重工业。除资金以外,大模型的训练需要大量的科学家人才、数据、算力。
而UCloud主要做的就是大模型最下面的基础设施。季昕华提到,目前,国内有139家公司在做大模型,其中五六十家都是由UCloud支撑和支持。所以,UCloud对整个模型过程中的技术要求非常清楚,也看到了大模型目前发展阶段在技术上所遇到的挑战,包括功耗、存储、网络等。


以下为季昕华的现场演讲内容,小编作了不改变原意的编辑及整理:
一、从“百模大战”看做好大模型的关键要素
我来分享一下我们是如何用云计算支撑整个大模型发展的,确实在国内现在大模型非常火,按照我们的收集,在国内有139家公司做大模型,包括基础模型和专业模型,所以称之为“百模大战”是非常形象的,而且这个数字还在不断增加。
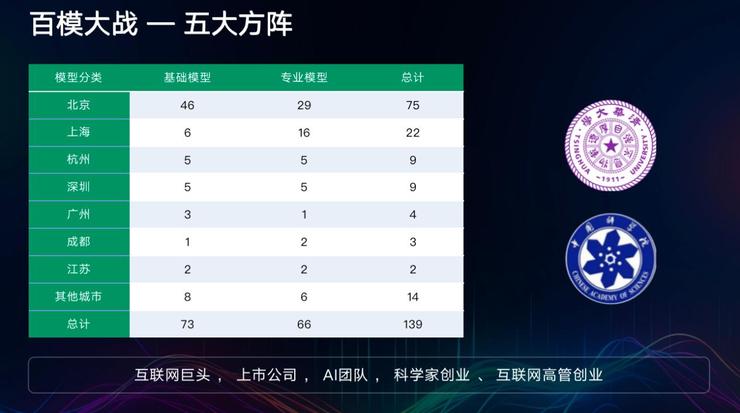
这其中有两点:第一个是我们看到这些公司的人50%以上都是清华大学毕业的,今天早上的主论坛潘院士和黄院士都是清华的;第二个就是中科院自动化所;今天还要加上第三个标签就是南洋理工大学。
按公司类别来分可以分为五大类:第一个互联网巨头,他们几乎什么都会做;第二个是上市公司,像360、科大讯飞等等;第三个就是AI团队,像AI四小龙;第四个是科学家创业,是现在发展比较快的,像智谱华章、衔远科技;第五个是一大批原来互联网的高管出来创业的,像李开复、王小川等这样的公司。
这些清楚以后,其实我们可以看到大模型做的好不好有四大核心要素:资金密度、人才密度、数据密度、算力密度。在资金上,一家大模型企业在国内没有一个亿美金起步的话,做大模型的压力就会很大,所以我们把大模型称之为互联网的重工业;做大模型还需要大量的科学家来做算法分析;大量的数据也必不可少;还有算力的密度,有多少张卡决定了模型做的有多快、有多好。
二、从整个训练流程看大模型的挑战
整个大模型训练其实包括四个步骤:从前期的准备到训练,再到最后的上线推理运行。我在中间加了两步,从前期的数据清洗、预训练、监督微调、奖励建模、强化学习,以及后续的部署运营六个阶段,在这个过程中我们可以看到,往往会面临着多样合规数据获取,计算、存储、网络等一系列难题。
而UCloud主要做的就是大模型最下面的基础设施,“大家知道 OpenAI 做得很好,那么其实背后有微软给OpenAI的大力支持。目前国内139家公司里面大概有五六十家都是由UCloud做支撑和支持,所以我们对整个模型过程中的技术要求非常清楚。”
由于大模型的参数越来越大, 比如1000多亿的参数,这时候就需要把整个模型分配到几千张卡上,那么卡之间的数据同步、网络互联,以及中间出现故障的情况下如何做恢复等问题,在这种情况下对于整个网络、存储,对于整个系统的框架要求会越来越高。

在准备阶段,大家也都清楚最核心的是收集到足够的数据,如何获取有效的数据是最重要的;第二步在训练的阶段需要有大量的GPU卡,而大量的卡之间组网就会产生很多问题,比如存储、网络以及稳定性等问题,具体来看:
首先是功耗和电力的挑战:举例来说,一台A800大概需要6000多瓦的电力,H800更高,耗电11千瓦。比如说新加坡,其实电力成本很高,UCloud乌兰察布数据中心电力充分、电价低廉、可自然制冷且距离北京更近。相较上海、北京等同等质量的数据中心,成本下降40%。
其次是存储的挑战:在大模型的训练过程中,大量非常小的文件,全部分配到服务器上,会有大量的元数据操作,还有高吞吐读的需求,还有大量的顺序写入,这对存储提出了更高的需求。
针对以上这些问题,UCloud做了一些优化,经测试,优化后的读性能有70%左右的性能提升,达到5GBps;写吞吐10%左右的吞吐提升,达到2.2GBps,可充分满足大模型客户在单点挂载时吞吐的性能需求,大幅提升训练效率。后续,UCloud会在和kernel交互的方式上进一步优化并发来提升写吞吐的能力。此外,UCloud研发中的GPUDirect Storage,将会有更高的存储性能。
他谈到,目前UCloud是国内第一个支持GPUDirect Storage,那么可以把GPU内存的数据直接写到存储上,而不需要CPU的处理,所以效果会非常好。
最后是网络的挑战:在大模型的训练过程当中,一般有三种并行策略:张量并行、流水线并行、数据并行,他们的通信量分别是百GB级别、100MB级别、10GB级别,但是由于整个网络带宽的瓶颈限制,GPU不能很好的利用,造成大量浪费。GPT 4 对外的公开数据显示GPU的利用率只有30%多,这是由整个存储的带宽压力和整个网络通信的带宽压力导致的。
现在业界流行的有两种方案:RoCE和InfiniBand,而InfiniBand目前由英伟达控制,开放性不够,所以现在大部分的公司开始逐步采用RoCE网络。
季昕华表示,大模型训练RDMA网络设计要满足“大规模、高带宽”的要求,目前UCloud支持IB和RoCE两种高性能网络方案,IB可以支持万张以上的GPU同时接入;而RoCE的可扩展性和开放性都比较好,当然这里面也存在比较大的一些问题,比如说整个哈希的不均衡问题等,我们目前正在和一些公司进行合作,希望把问题进一步解决,能够提高整个卡的使用率和效能。
三、谈大模型十大应用场景和三大挑战
谈到目前国内的场景应用,季昕华表示,按照对大模型输出内容准确性的容忍度来分类,在游戏NPC、社交辅助、电商、游戏/设计的画图、翻译、客服支持、文字和编程辅助、教育、法律、医疗这10大行业场景有较为广泛的落地。
季昕华介绍到游戏中的NPC使用大模型来做的话,会极大提高游戏用户的粘性;而在社交辅助上,大模型可以模拟人进行交流也非常受欢迎;在电商方面,很多页面设计、文案输出、图片设计,都可以交给大模型来做,可大幅提高生产效率;在法律、教育和医疗领域,更多的是作为辅助功能,最后由老师或者是医生和律师来签字,担责的是人,所以这三类目前是无法被替换的。
另外他还谈到,大模型发展还将持续面临数据安全、政府对于合规性的要求、国际关系对于中国AI发展的限制等挑战。
由于国际关系对于AI发展有一些核心硬件的限制,国内无法购买A100、 H100 或者未来更高一级的卡、更高性能的芯片,所以中国AI的发展会受到很大的挑战,和国外的差距会越来越越大;还有由于政府对与合规性的要求,很多客户开始采用海外磨枪,国内使用的路子,UCloud在全球有30多个数据中心,可以协助用户磨练产品,之后有条件的时候再搬到国内;还有一个重要的挑战就是数据安全,很多用户的数据放在云上,肯定会担心会不会被拿走,UCloud是一个中立的云计算公司,我们有一个模式就是给合作伙伴建立专有云或者私有云,放在自己的云上随意做测试、训练,也不会担心数据的安全问题。
在提问环节,他回答了现场观众关于应用场景的提问,季昕华表示,现在确实是互联网的应用场景会多一些,但我们也在其他领域进行探索,一个是 AI for Science,比如AI for化学,通过无人化的试管试验来验证可能性。第二探索是AI for Brain,在大脑科学领域,我们在跟陈天桥进行合作,通过AI来分析大脑状态、大脑操控各种行为时的变化。第三个探索就是生物医药。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!