
编者按:2023年8月14日-15日,第七届GAIR全球人工智能与机器人大会在新加坡乌节大酒店成功举办。
论坛由GAIR研究院、小编、世界科技出版社、科特勒咨询集团联合主办。大会共开设10个主题论坛,聚焦大模型时代下的AIGC、Infra、生命科学、教育,SaaS、web3、跨境电商等领域的变革创新。这是国内首个出海的AI顶级论坛,也是中国人工智能影响力的一次跨境溢出。
在「AIGC 和生成式内容」分论坛上,joinrealm.ai 创始人蔡丛兴以《 AI Generation Challenges 》为主题分享了AIGC 的历史与发展、机遇和挑战。


蔡丛兴在演讲开始即指出,当下生成式 AI 产品落地的基础难度在不断上升,同时对于生成式技术的边界认知也在逐渐提高。
蔡丛兴认为,内容生成里有三个相互 dependent 的因素,一个是 foundational model,第二个是基于 foundation model 创建出来的 fine tune,第三个是文字上的 prompt 的engineering。因此,这一相互依赖的系统在很大程度上依赖于一个社区,即在 fine tune 和 foundational model space 内找到新的、最适合的 prompt language,也就是特殊的使用语言。
由于 AIGC 技术还没像 ChatGPT 一样达到一个爆点,所以蔡丛兴判断,当下的创业者需要回归到对三个问题的思考:其一为是否能够清晰地为目标用户画像;其二为是否能够找到最适合用户的 unique 的workflow;其三为是否能够 tap into existing distribution 以实现增长。
以下为蔡丛兴的现场演讲内容,小编在不改变原意的前提下进行了编辑和整理:
很荣幸今天可以在这里和大家一起交流讨论关于这AIGC 创业的一些收获,我来这里的主要目之一也是想认识更多的 AIGC 创业者,然后大家可以更深入地讨论这个问题。在接下来二十几分钟的时间,我就做一些抛砖引玉,讲一讲我们的收获。
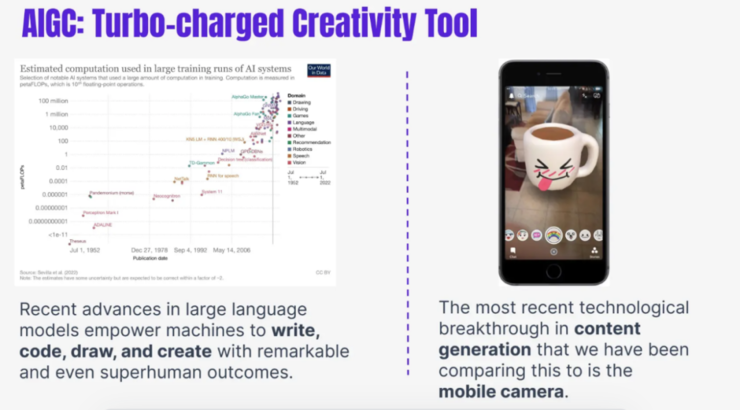
在过去的几年里,生成式 AI 发展很快,尤其是过去的一年,其中最主要的原因可能是生成式内容的用户接受度很高,所以导致市场的发展都很迅猛。随着更多的投入,我们对于生成式技术的认知也发生了很大的变化。
今天去讨论这个问题的时候,最主要的一个感受是我们在这个过程中对于产品落地的基础难度的认识是在不断的增加的,但同时对于生成式技术可能产生的边界也在不断的成长。所以今天将会聚焦在我们所意识到的真实挑战上的一些问题,然后从这里开始展开。
做一个简单的介绍,Realm 主要是做基于 AIGC 的社交网络,待会我会介绍更多我们的工作。
目前团队主要是在美国加州。就我个人的经历而言,十几年前开始做语言模型,从研究到工程,再由工程到产品,再由产品到商业。我早期的研究工作主要是在语言模型,在摘要和 ranking 能力的应用。加入 Google 之后,我接触到的第一个项目实际上是的 YouTube 早期的视频广告,当时就发现这样的一款短视频广告能够产生非常大的效果,就是它很快就成为了 YouTube 的 revenue dominate source。
当时我就有一个很简单的假设,如果所有的内容都是由短视频代替的话,会产生什么样的效果?所以2011年左右我就找了很多好朋友去讨论,说有没有一种可能性,短视频会取代用户的内容。当时有一个很大的限制,就是在内容的制作工具上达不到这种实名制的效果。
当时有一位同学分享了国内的快手这样一款 APP,然后那款 APP 当时还是以 gif 的制作为主,就是它生成的内容已经有了一定的故事性,但是还远远达不到短视频的效果和视频广告的效果。但过了两年多之后,随着苹果推出了前置相机,包括高清视频的录制这些功能都出现,短视频的这趋势也就一发不可阻挡。我在 15 年左右的时候加入了 Snapchat ,是海外最有潜力的短视频的公司,在过去几年的时间里一直都是 Snapchat 所有的短视频的产品开发。2021 年左右,由于 TikTok 的成功,我发觉到表达式的生成式视频一定会有新突破。
所以我和我的同伴一起出来成立这家创业公司,专注在做生成式视频,这是我和我的cofounder的联系方式,大家可以加我们的 Linkedin,欢迎之后有更多的讨论。
接下来,我们来讲AIGC。我觉得 AIGC 是一个特别宽泛的概念,它实际上非常抽象。从技术的角度来看,在过去的几年里,大家已经达到了认知的共识,它指代的是由大语言模型引发的、由文字生成内容的一种生产手段。那我们去解读它的时候,我觉得有必要来讲一讲 mental model,因为它会决定我们从哪个角度去看。
从细到远,mental model 大概有三种不同的layer。最新的layer就是直接把它做一个 ATI service,比如微软、谷歌上线的一些产品会直接拿 AIGC 作为一个service,去加强现有的产品。更远一点的话,从整个软件开发模式上来看,已经从过去 50 年中微软的这一套以 API 为主的软件开发模式过渡到自然语言为界面的软件开发模式,这可能会是一个软件开发形式的变化,更多的是一些哲学上、包括产品管理上的一些讨论。
在中间地带,就是我们创业公司对于新的商业模式的一个探索。这一探索主要有三个方向,第一是摘要,摘要最主要的应用是搜索,包括 QA 都是摘要里面最主要的模式。第二是推理,推理主要集中偏智能助手应用之类的应用模式;第三是在创作,我们主要专注于内容创作这一商业模式。
为什么内容创作模式很重要?根据我过去十年对短视频的观察,很大的一个变革是因为智能相机的出现,智能相机的普及不仅仅是给了每个人一个手机,而是给了几十亿个行走在世界各地的录制设备。
如果用智能相机促成成功的创业公司也有很多,比如TikTok、Instagram、Snapchat,很多很新的 to consumer 产品都是由于智能相机的普及才产生的。
我们一开始出来创业的时候,对表达式视频的脑海中的 mental model是,如果智能相机给了几十亿人一个行走的记录设备,去记录这个真实的世界,那么有没有一种相机是可以记录人的脑海中的假象。
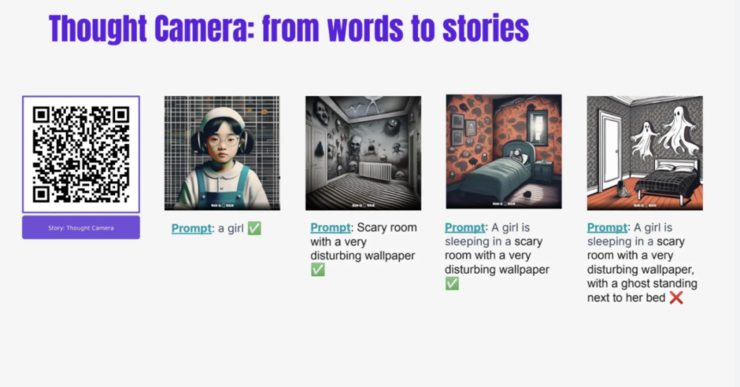
我这有一个博客,起初 AIGC 还没有那么成功,我们当时做了大概 10 款不同的产品,每一款产品用了不一样的技术,最后进行了聚焦。它的本质上从用户体验的角度来讲其实就是用 word 到story。这是我们最新的 APP 上的效果,你可以说 a girl、一个很恐怖的卧室、然后这个 girl 在恐怖的卧室里面睡觉、这个 girl 在这个恐怖的卧室里面睡觉的同时旁边站着两个ghost,但是到第四个的时候就已经不work,因为 ghost 的空间关系,包括它们之间的空间距离感是 lost 的。
这样一个简单的example,可以告诉大家两个点:第一点是我们还没有办法很好地做到第三步,但是这个速度发展很快,因为三个月前我们卡在了第二步,所以现在到了第三步,也有很多人觉得第四步也OK,但如果你让上百万的用户去用那就不 OK 了。

刚才分享了我们是怎样去探索这个新的商业模式的,以什么样的 mental model 去探索商业模式。最终我们选择从 text image 开始出发,选择它最主要的原因是我们觉得它是 storytelling 最核心的部分,是最后的 foundation。那这张图是我上周五在那个伦敦旁边的那个巴斯的修道院拍的。当时有个新一代的画家,会用自己新的画具体重新解释一个故事,非常 impressive,但是它本质上是说画作为人类历史里面的一个重要的 story telling的这样的一个工具,它实际上是抓住了这个故事本身最重要的部分。
另外一个原因是生成式内容可以很容易地和其他的文字组合去支持其他内容形态,比方说 me 、coffee都很容易。
第三点是由于技术本身也非常容易去 scale 到,对于音乐生成、语音的生成也都非常的简单。
如果我们最终的目的是生成视频的话,视频的维度非常多。从我们自身的角度来讲,内容本身的故事性是视频成功最关键的因素。所以说我们选择从 text image 作为我们最核心的这种 focus 的点当中,我们也做和 ChatGPT 的整合,之后如果有机会也可以一起讨论。

那么它什么地方还不行?第一个最不行的地方在于它还不能是 word to story,它实际上是 prompt to story。prompt 是一个非常 confuse 的一个概念,它实际上是一个就是这样一个过程,可以通过语言不断地用文字去描述这个你脑海中的这个细节,可以通过加定语去描述 context、加一个形容词去描述framing、加入 subject、 可以加各种各样的style, vocabulary 越 rich 就越好。

这个时候你可以去画想象中的这个女神是什么样子,但如果只有一个beautiful,那肯定是不行的。你要知道美的 20 种说法,要知道关于形态、眼神的无数个单词,还有很多单词可能字典里都找不到,这是最主要的难点。
其实 prompt是一种程序语言,它比程序语言更难的地方在于它没有 structure ,所以需要很多的 try and error 才能够真正达到想要的效果。另外一点是需要对于某种方向有非常密实的词汇量的掌控,词汇量越丰富,细节就会越多。也包括在 account 里面有更多的markup,有更多的 advance target,可以做非常精确的控制。
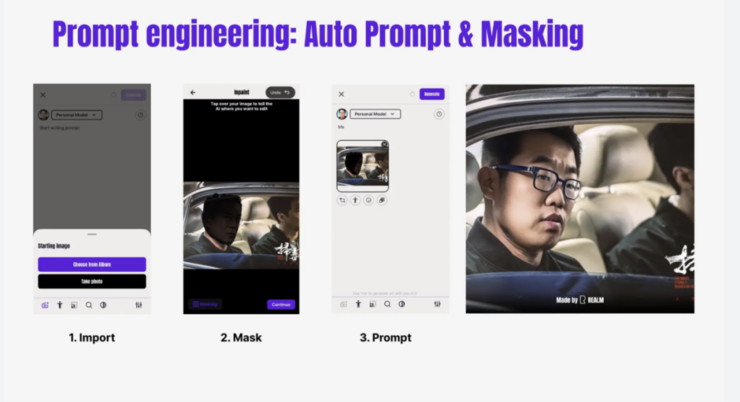
这里也可以通过简单的文字去进行两个 concept 的mix,比方说你喜欢两个这个角色,你可以轻松用这两个词去把它拼成一个词,比如刘德华和周润发,可以拼成一个人。

还有很多数据上的操作,是 Pixel 上的一些精确的控制,比方说我们随便做一个简单的一个端口,上传一个图片,把人脸给画下来,然后换一个词mix。除了这个 Pixel 上的控制,还能有 sematic 上的控制,可以控制它的形状、结构、位置,包括后续的这些post,这些工作都是朝 Prompt 的角度进行深入。那我们今天在这个角度上就不再继续深入地聊聊,但希望大家能 take back 到的最重要的点就是 Prompt 还不是自然语言,它是非常难掌握的一种编程语言。

第二个点是 foundation model。目前所有的新闻 、research 主要的关注点实都在 foundation model上。关于foundational model我想分享几个观念:
观念一是图像生成的早期 foundation model 的效果不是很好,没有什么可供参考的针对用户的数据,我们内部对数据的一个判断就是对于一个新用户来说,他愿意分享的用于生成的照片比例是大概是低于20%。
观念二是 foundation 的 model 进步得非常快,在过去六个月的时间里面, SDXL 的效果大概能提高 4 到 5 倍。所以我们内部的数据还没有完全出来,因为所有的整合还没有完全完成,我们会继续观察大概效果是多少。
观念三是,研究过 SDXL 相关结果生成的一些 example ,我个人感觉,open source 的模型已经远远超过 OpenAI 的这些 close source ,也已经超过了最新版的 Mid-Journey 。昨天很多人讲,做大模型需要很多资源,三驾马车之类的,但其实大模型还是很多机会的。如果在座的各位是创业者没有大量的机器,图像生成是一个很好的选项,只需要一台电脑就可以。
第三个点是我们有一个非常大的一个 community contribution,主要是基于 Dreambooth 的 technology 做了很多对房地产模型的优化,还有特定场景,包括二次元、人物画像等,我们对这些模型做了内部的evaluation,在特定应用场景上的效果是非常好的。

叙述想象世界的过程中,除了需要有生成的工具和好的 prompt,第三个就是需要有 concept。就是我不仅仅需要一个girl在一个恐怖的房间里,我需要一个 specific girl,我们设计出来的那个人在我想要的房间里面做一件 specific 的事情,获得一个 specific 的效果。那么,这需要大量的用户利用各种已有的 framework 去创建各种各样的 fine tune 机制。这个机制有很多的 know how、knowledge,我们对这个机制的一些体会,也会随着实践过程不断变化。
但我们可以看到一些非常好的应用,比如对人物的设计,可以设计出想象中的人物,然后也可以去设计想象中的场景和风格,甚至可以控制拍摄的视角,而且控制的方法都很简单,那就是创建出属于你的独特的单词,用词去控制故事的讲述。
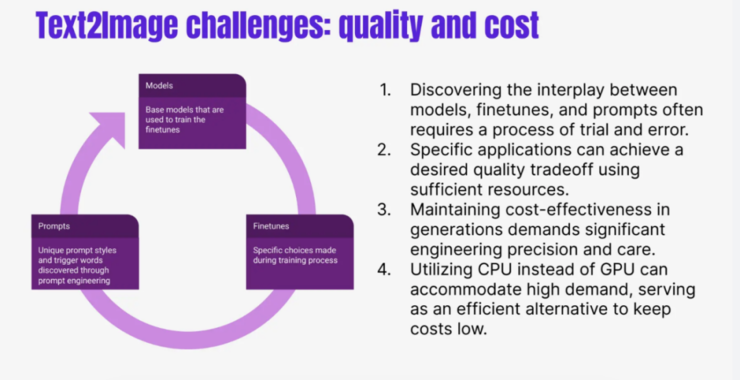
讲到这里,我们解释清楚了内容生成里三个相互 dependence 的因素,一个是 foundational model,第二个是基于 foundation model 创建出来的各种 fine tune,然后是基于 fine tune 的文字上的 prompt 的engineering。这三个因素之间是相互 dependent 的,也就是当你的 foundational model change 的时候, fine tune 实际上是会对特定的 foundation model 产生特定的效果,然后特定的这一套 foundation model 实际上会对 prompt effect 产生效果。
所以这在很大程度上依赖于社区,在 fine tune 和 foundational model space 内找到新的、最适合它 prompt language,也就是特殊的使用语言,这就是他的 depending 思路。
接下来还有几点分享,由于这样的 trade off 和你可以 navigate 一个空间,所以如果你心目中有一个特定的application,比如拍写真照或拍一个二次元的东西,那么就总是可以通过某种 trade off 达到想要的效果,但同时很 complicit 就是 cost,即你会用多少的代价去实现这件事情。如果希望做出一款非常general的,那么就需要很多的 engineering 的 carefully decision。
同时,如果想做大规模的 to consumer 场景, GPU 的 cost 是一个很重要的问题。我们团队的解决方案是对所有的实践的 influence 做了一套 CPU 的 solution,然后也建立了他们的 quality,可以 compare, cost 会更低,而且效果上也可以重复。但是我们也见过其他人有别的想法和尝试,就像通过手机上的应用,用 GPU 去做这些事情。不过我们主要的 focus 在 CPU 的解决方案,而且已经得到了验证。

讲完 challenge 之后,最后回归到“真正的机会在哪”这个问题上?在过去 6 个月的时间里,大概见了上百位美国最 popular 的 AI creator,大家可以在 YouTube 上去看 AI show。我最近特别喜欢它,是用 AI 做的 movie trailer,把各种各样的角色混到一起,非常有意思。我们对于这个技术或看到这个结构,会觉得这怎么可能?这怎么做到?所以这给我最大的冲击就是creativity,大家是非常有想象力的;其次就是他们每个人都是一套独立的制作方法,没有相似的途径;第三就是他们每个人都会使用大量的工具。
而他们唯一的共同点就是 try and error,通过这个过程不断地去调试、去调节,找到一条属于自己创新的工具,这也是我们对这件事情最重要的总结。所以,最后想要达成这种生产效果,很大程度上依赖于对 workflow 的探索和对 workflow 的实验。
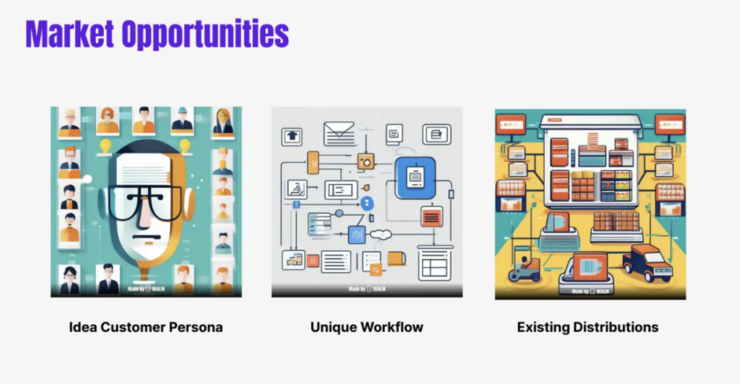
我们再来讲讲 Market Opportunities 。因为技术可能还没有达到像 GPT 那样的一个 break point,成为一个通用技术,每个人都觉得OK, i can get it,它实际上还没有达到这个moment。所以走到今天,创业需要回归到三个问题,第一点是你能不能够清晰地画像目标用户;第二个点是你能不能够去找到最适合用户的 unique 的workflow;第三点是能够 tap into existing distribution 去实现一个增长。这也是我这次来一个主要目的,我相信这里有很多的创业者都是以此作为努力的方向,我们有很多可以交流的地方。
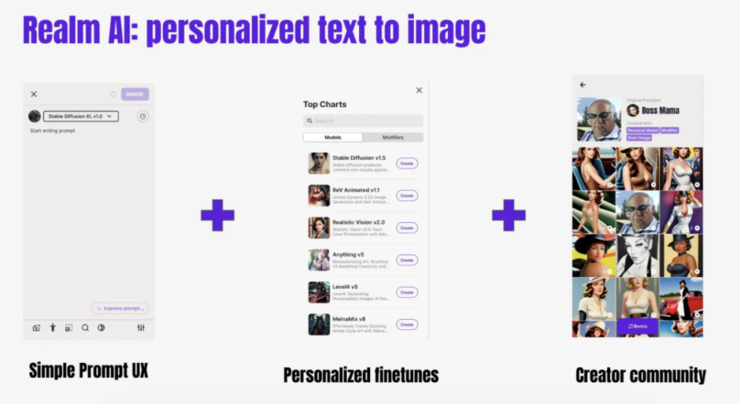
其实,可以把 Realm 理解成一个 Instagram for a personal imagination。我们在做三件事情:第一件事是,把所有最新的 prompt 的 technology 集成一个非常易用的手机端的 interface ,使用它时就像用一款相机一样去描述自己的想象。第二件事是,让每个人都可以在使用、创建自己的 fine tune, share 自己的 fine tune;第三件事是,给大家一个 creator community,因为 prompt 需要很多的 education 和integration,因此可以从别人那里获得灵感和idea。
对于在做的各位来讲,如果你还没有接触 AIGC 或者内容生成,其实 Realm 是一个特别适合 get start 的地方。其一是因为它为普通用户设计,很多非常深的技术名词、技术细节都可以像学自拍管理一样去把这些东西领会到。其二是因为它很便宜,因为用的是CPU,可以用可控的方式去来 lower 它的 generation cost,大概在 mission 上要比很多 generation 便宜很多,如果是普通用户的话,基本上可以不花钱。其三是因为可以接触到最新的technology,所有的 model 都可以随时更新,也会有一个 community 去 learn from each other。
关于 startup 我们还可以有机会一起讨论,做 workflow 最难的点是发现 tradeoff,另外一个是有一个 community 去帮助探索 prompt attention。
除此之外还可以考虑能不能提供一些 besides APP 的access,让大家去 leverage 我们做的一些工作。最后一个是research,15 年前我开始做research,其实它最重要的一点是能够快速地实验,快速地分享demo, share 我的 demo 或者是 user 的demo,然后能够快速 get feedback,也就是从数据上知道你的模型怎样和现有的东西去审核,效果是什么样的。
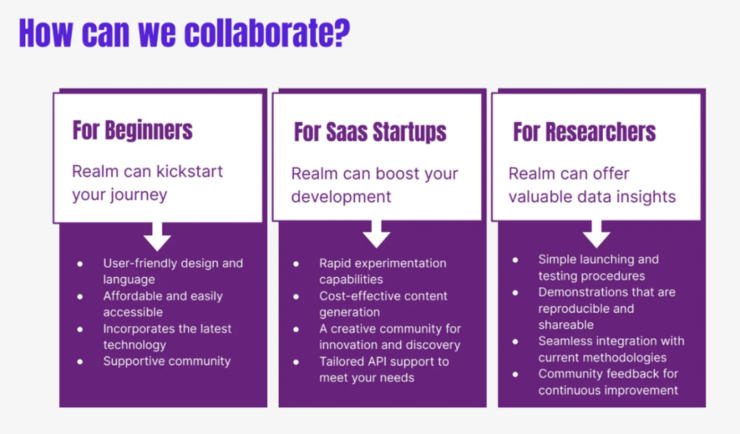
这是我大概 brainstorm 了一下,希望可以和在座的各位有一些交流和合作,以上就是我今天的主要内容,谢谢各位。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!