
生命科学的爆发可能像GPT一样很快到来。
在如今的大模型浪潮中,来自全球学术、工业、投资界的一群人,正俯瞰着创新乏善可陈的 AI 谷地,他们眉头紧皱,一筹莫展:可研究、能落地的方式,应用尽用,瓶颈触手可及。
然而有那么一批开拓者,把科学和应用之手,伸向了饱受争议、遥遥无期的人迹罕至之地:通用人工智能。在他们的勘探下,人工智能终于被掀开守护了60年的真实容颜,让GPT和大模型,展露在众目睽睽之下。
当生命科学的人聊起AI新浪潮,焦虑、渴望与机遇,成为这群人的共同写照。
生命科学领域的很多问题还有待于解答和观察,大模型能否刺破笼罩在科学上空的漫漫长夜,带领一群人破译生命密码?
由GAIR研究院、世界科技出版社、科特勒咨询集团、小编联合合办的GAIR大会8月14-15日在新加坡成功举办。而针对当下科技圈的最新趋势,15日上午「破解生命密码的三种范式」分论坛,请到了三位生命科学领域的实干家,请他们来分享自己的真知灼见。
三位来会发言的嘉宾分别是:
密苏里大学教授,AAAS / AIMBE Fellow,许东
微软云与人工智能事业部首席科学家,陈梅
纽约市立大学教授,IEEE / IAPR Fellow,田英利
核心观点:
许东认为,基于图像和自然语言的大规模数据训练的基础模型,为广泛的应用提供了前所未有的机会。
当与基于提示的学习相结合时,这些模型的潜力被进一步放大,即使使用少量标记数据也可以实现最先进(SOTA)的性能。
本次论坛许东重点介绍了两个基础模型在生物医学领域的应用:ChatGPT和Segment Anything Model (SAM)。
他指出,随着文献量呈指数级增长,人工检索方法无法有效提取嵌入式知识。作为回应,许东和团队开发了一个途径管理管道,协同图像理解和文本挖掘技术来破译生物知识。
该管道采用SAM、对比学习和暹罗网络来识别路径实体的关键属性及其关系。整合ChatGPT对基因相互作用的预测能力已被证明有助于增强途径信息的提取。
为了优化ChatGPT的响应,应用了一种新颖的迭代提示改进策略,其中使用F1分数、精度和召回率等指标评估这些提示的有效性,然后将评估结果馈送到ChatGPT中以提出更好的提示。更进一步的,许东使用思想树迭代进一步改进了提示。
此外,基于提示学习的方法,许东也从冷冻电子显微镜(cryo-EM)图像中进行基于SAM的蛋白质鉴定。研究结果强调了基于提示的学习,在有效的生物医学数据分析和预测方面的潜在效用。
陈梅分享了一种在医学影像分析中,可以减轻标记数据收集负担的方法——无监督域自适应(UDA)。
据陈梅介绍,自动化医学图像分析的成功取决于大规模和专家注释的训练集,而医学图像高质量标记数据的获取成本十分高昂,经过长期的研究,陈梅及其合作者发现无监督域自适应能够解决这一问题。
设计了一种双流蒸馏算法,利用从可靠来源获得的外部指导来正则化注释不足的域和类的学习动态。这一方法解决了分类自适应跨域自适应场景中的主要障碍——沿网络优化导航不足的问题。
田英利分享了其团队在AI驱动的虚拟对比度增强与AI驱动的自动癌症诊断两个方向上的研究。
田英利团队提出的细节感知双路径对比度增强框架,能够将图像分为四个等级,提取更详细的特征,获得更精确的虚拟对比增强CT,以解决肾脏病人对造影剂过敏的问题。
此外,她还指出了当前肺癌检测方法中存在的缺陷,如小结节难以检出、特异性低、鲁棒性低等,并提出了基于三维特征金字塔网络(3DFPN)的AI驱动的自动肺结节检测方法。
这些观点并非都是共识,也只揭开了大浪潮的冰山一角,但仍体现了变革浪潮里生命科学人的思考与探索。
受限于篇幅,我们选取部分内容进行梳理,分享给更多对AI领域感兴趣的人士。期待更多人参与到生命科学的大模型实践中,共同汇入社会创新的时代洪流。
密苏里大学许东:基础模型本身就可视为黑盒,ChatGPT也有可能进化为具有超强推理能力的「知识图谱」


这一年NLP学术领域飞速发展。其中最火的两个概念就是contrastive Learning(对比学习)和 prompt-based learning(提示学习)。
众所周知,AI领域除了算力贵,有价值的标注数据也非常昂贵。而无论是对比学习还是模板学习,都开始解决少量标注样本,甚至没有标注样本时,让模型也能有不错的效果。
而prompt-based learning算是目前学术界向少监督,无监督,高精度的方向发展最新的研究成果。
作为今天「破解生命科学范式」的首位嘉宾,密苏里大学的许东教授的分享题目是《Prompt-based learning for analyses of biomedical images and text》(基于提示学习的生物医学图像和文本分析),引起了现场的重点关注。
许东将机器学习分成四个阶段:
第一阶段,特征工程,即手动特征提取,以SVM或简单的神经网络为代表。
第二阶段,构架工程,即用原生特征,在深度学习网络上做各种调整。
第三阶段,目标工程,即采用预训练大型模型并对其进行微调,以Bert为典型代表。
第四阶段,提示工程,即在基础大模型上做各种各样的应用,比如zero/few shots 。
许东认为,提示学习使得机器学习有了一个根本性改变:从过去比拼的大数据、大模型、大算力,转向用小数据、小模型、小算力解决实际问题。
也就是说,只需要将较小规模的模型接入到大模型上,即混合模型,那么训练要求也随之降低,可以用很小的算力做很多事情,尤其是是对没有太多计算资源的学术实验室和医院非常友好。
对于基础模型的定义,许东认为一个基础模型至少要符合三点:可被提示、适用广谱的下游应用、有超大的训练数据并达到智能涌现(可理解为:具备一定推理能力)。只有满足这三点,“基础模型本身就可以当作黑盒,且聚焦应用本身”,最终推动“人工智能的工业时代”的到来。
他近一步解释,过去很多人批评机器学习,说它是黑箱。但在提示工程时代黑箱可能是一件好事。因为你不需要关心里面的复杂度。就像你用手机一样,关注点只是界面交互,而非手机的制造工艺。

在当前的基础大模型竞赛中是,许东从图像和自然语言两方面入手,在本次论坛上重点介绍了两个基础模型在生物医学领域的应用:ChatGPT和Segment Anything Model (SAM)。
值得注意的是,许东教授此次尝试,也代表了国际上最早进行大模型生物医学实践的团队。
他通过大量实践得出结论:如今大规模数据训练的基础模型,为广泛的应用提供了前所未有的机会。尤其是当与基于提示的学习相结合时,这些模型的潜力被进一步放大,即使使用少量标记数据也可以实现最先进(SOTA)的性能。
首先,一般人研究ChatGPT ,主要将其作为一个对话工具或者知识查询工具,许东开创性提出:ChatGPT对广谱的文本进行加缩,本身就成了一个具有超强推理能力的“知识图谱”。
从科学角度来说,很多人会质疑“如何规避ChatGPT中的‘幻觉‘问题”,但许东指出,“幻觉做计算的时候不算什么,可以视为一种false positive(假阳性),即预测过程中的正常情况。只是我们要用科学的方法来研究它、量化它、控制它。”

与此同时,许东也指出,ChatGPT(更明确说是GPT-3.5)并不能直接用于生物医学研究,它更像个话唠,不加控制将时更易产生滔滔不绝的回答。
因此首要工作是将其结果和“ground truth”(真实数据)做严格比较。作为计算生物学家,许东更想让ChatGPT回答:“基因A和基因B到底有什么关系?”“人类应该怎么设计好的提示来做这个问题?”,使得结果更符合生物学的知识。
其次,还要严格按照机器学习的方法来做提示(prompt),设置Ground Truth、搭建训练集、检验集和测试集等。
作为测试,许东和团队将ChatGPT进行了角色定义–一个计算生物学家,并要求ChatGPT回答“基因A和基因B之间的关系”,并明确要求只限于4种回答:“激活”,“抑制”,“磷酸化”或“无信息”。

在实验过程中,许东发现,“Few-Shot Prompting对训练模型只有很小的作用,但它更大的作用是示范–告诉ChatGPT我们要解决的问题是什么?”
这是实验中的关键一步,随后你可以再告诉ChatGPT一些知识,即chain of thoughts(思维链)。
为了优化ChatGPT的响应,许东应用了一种新颖的迭代提示改进策略,其中使用F1分数、精度和召回率等指标评估这些提示的有效性,然后将评估结果馈送到ChatGPT中以提出更好的提示。
通过这种做法,可以是把所谓“硬提示”变成可以调整的“软提示”来优化,但不同于常规的软提示。

结果显示,这种方法能够明显体现出ChatGPT的智能涌现。也就是说,“它达到了反思能力–开始思考自己是否达到最好。并且后续的改动非常少。”
举个例子,它最初的身份是“一名计算生物学家”,但经过数次自我提示和迭代后,它变成了“一名专门研究基因相互作用的分子生物学家”。再比如,ChatGPT在activation incubation这一回答后加了一个括弧– gene one activates gene two。
许东表示,这些东西好像没有什么意义,但是它确实把格式定义得更清楚了,所以这些细小的这种调整使得它的这个整体表现大大提高。
此外,许东指出,ChatGPT不光能做两个基因的关系,还可以做基因链的关系–一个基因链的作用,最终是从基因A到基因B,但中间经过了C、 D再到B。这一研究也可以让ChatGPT通过思维链的方式把整体网络搭建出来。这就便意味着,ChatGPT可以构建更大的知识图谱。
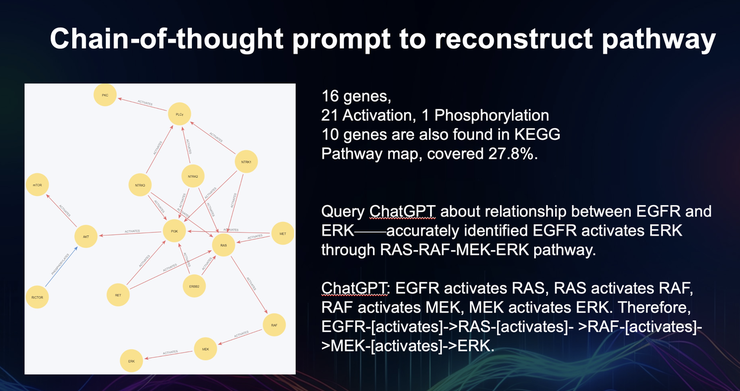
此外,基于提示学习的方法,许东也从冷冻电子显微镜(cryo-EM)图像中进行基于SAM的蛋白质鉴定。研究结果强调了基于提示的学习,在有效的生物医学数据分析和预测方面的潜在效用。
最后,许东表示,ChatGPT的整体表现一骑绝尘,但是产品本身不太稳定,有人评估发现今年6月ChatGPT的推理能力要弱于3月,正如昨天GAIR大会黄学东院士提到,AI要在工业界的落地应用应考虑「集成式 AI」的实践与可能,即三个臭皮匠顶个诸葛亮。
许东强调,“在学术上也要有三个臭皮匠的故事。”
针对他当前所做的提示工程,许东也表示,虽然提供工程量小,但要求很高,不能随便拿几个小数据来做,而且选的数据必须有代表性,不能是特别极端的数据;此外提示工程的泛化能力可能不如一些普通的机器学习。比如当两个任务很接近时,提示工程可能无法进行。
最后许东再次感触,“机器学习一个非常著名的定理–No Free Lunch定理。没有一种通用的学习算法可以在各种任务中都有很好的表现,需要对具体问题进行具体的分析。”
微软陈梅:无监督域自适应,将降低医学影像高质量标记数据的获取难度

陈梅指出,AI技术发展之快、规模之大前所未有,不论任何领域都应当努力适应AI技术的进步,以确保自己走在行业的最前沿。
多年来,陈梅花费了大量的精力研究显微图像,并在2016年与合作伙伴共同创办了CVMI(Workshop on Computer Vision for Microscopy Image Analysis)会议,此次她的分享题目是《AI for microscopy image analysis 3.0》。
显微图像的研究一直随AI技术的迭代而发展,比如此前人们对分割、对神经网络的探索等等,在这一过程中,越来越多的人开始关注病理学。
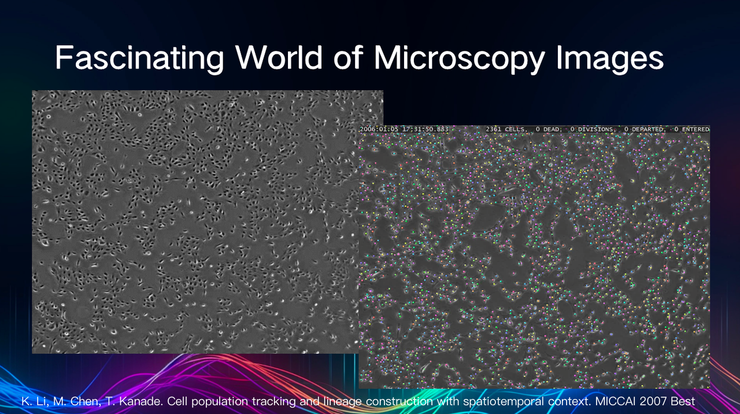
今年以来,显微技术有了很大的发展,图像分辨率也不断提高,让研究者们得以对每个单细胞进行深入的了解。
大规模和专家注释的训练集对医学图像分析至关重要,然而,对医学图像来说,想要获得高质量的标记数据,必须具备一定的专业知识,因此往往比其他领域数据集的创建更加昂贵。
为了减轻标记数据收集的负担,陈梅及其合作者多年来专注无监督学习适应的研究。研究发现,无监督域自适应在这一领域大有可为。
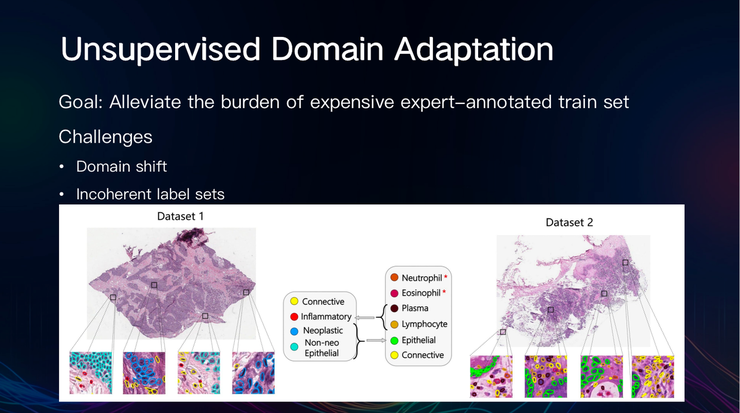
当然,无监督域自适应的应用仍存在挑战:
1、基于梯度的优化需要足够的标记数据来指导大量的更新步骤
2、域偏移/小数据制度导致更新信号嘈杂或过拟合

据此,陈梅及其合作者提出利用梯度空间的低秩性,优化轨迹蒸馏以及为学习目标领域和新类提供外部导航。
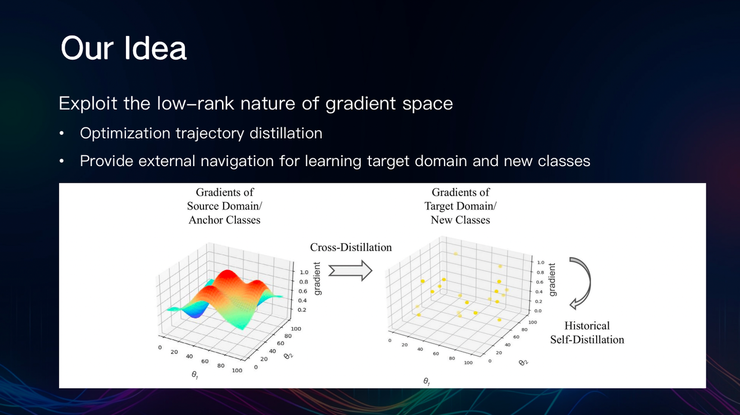
陈梅及其合作者设计了一种双流蒸馏算法,利用从可靠来源获得的外部指导来正则化注释不足的域和类的学习动态。
这一方法解决了分类自适应跨域自适应场景中的主要障碍——沿网络优化导航不足的问题。
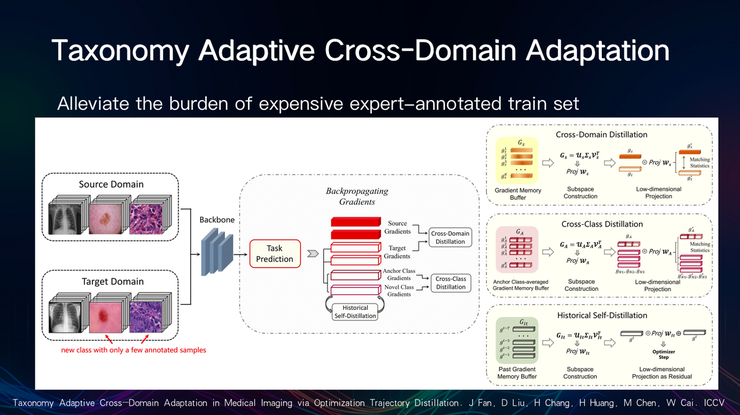
具体来看,双流蒸馏算法可以分为跨域和跨类蒸馏,将学习动态从源域和锚类提取到目标域和新类:
- 对源域和锚类的聚合梯度进行SVD,以识别主特征空间
- 选择最高有效向量的低秩矩阵近似
- 构造主子空间及其投影矩阵
- 将所有渐变投影到子空间上
- 最大限度地减少投影梯度统计数据之间的差异

陈梅及其合作者曾讨论,是否放弃历史自蒸馏的方法,即以前使用的方法。如果目标领域与源领域有诸多共同点,无监督适应就有比较好的普适性;否则普适性比较差。
历史自蒸馏可以利用扁平最小值区域和模型普适性之间的相关性;其次,校准梯度下降步骤以平滑优化,从而提升普适性。
优化过程中,我们的具体步骤如下:
- 利用历史,即过去的梯度,来识别指示局部极小值的主梯度分布的低维子空间
- 在构建的子空间上投影当前梯度以排除尖锐和噪声信号
- 使用原始梯度和校正梯度之和进行的后续优化器步骤
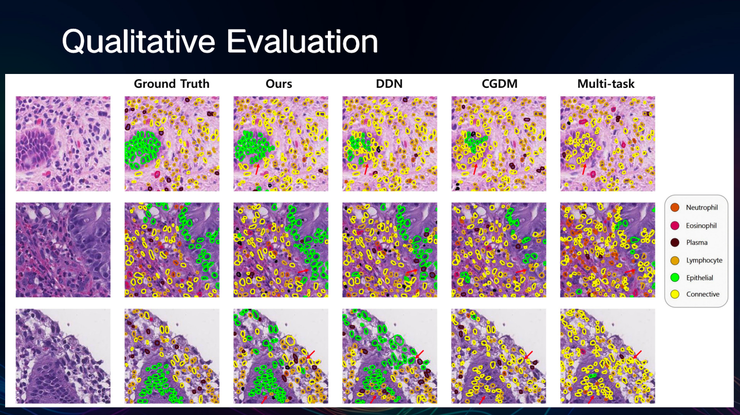
 陈梅及其合作者做了很多实验来验证,双流蒸馏算法能够适用于常见的许多数据集,如癌症组织表型、部件消融研究等等。
陈梅及其合作者做了很多实验来验证,双流蒸馏算法能够适用于常见的许多数据集,如癌症组织表型、部件消融研究等等。
对其他类型的数据,双流蒸馏算法也能够发挥作用,针对放射学中的肺炎筛查,糖尿病视网膜病变眼底影像分级,以及在艺术与真实世界领域的价值这三个任务,陈梅及其合作者也已经进行过评估,相比其他方法,整体水平均有提升。
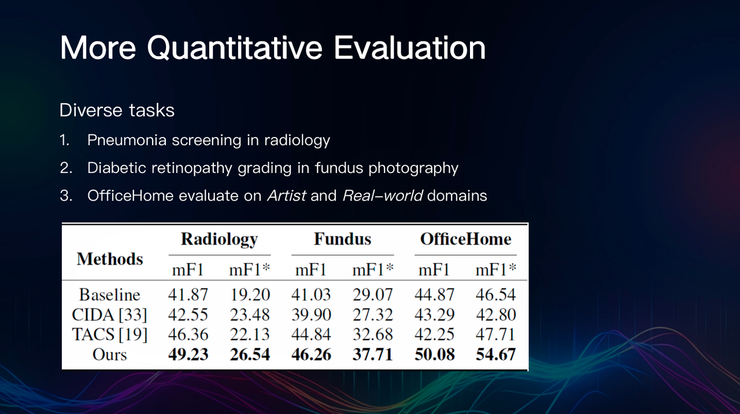
从我们的研究成果来看,跨域跨类优化轨迹蒸馏,能够校准未充分注释的域和类的学习动态;历史自蒸馏通过调节梯度分布,能够获得可推广的解。

纽约市立大学田英利:虚拟对比增强CT,可有效提升不使用造影剂的医学图像质量

田英利专注利用计算机视觉和机器学习等技术帮助老年人、视障、听障等特殊人群,在《AI-driven Automated Medical Image Analysis 》演讲中,她介绍了如何应用AI驱动的技术帮助医生分析医学图像。
田英利团队的研究围绕两个主题进行:
人工智能驱动的虚拟对比度增强——突出血管和器官的内部结构。
人工智能驱动的自动癌症诊断——病灶检测、分割和亚型识别。

田英利团队专注肺癌和肾癌两种疾病的研究。
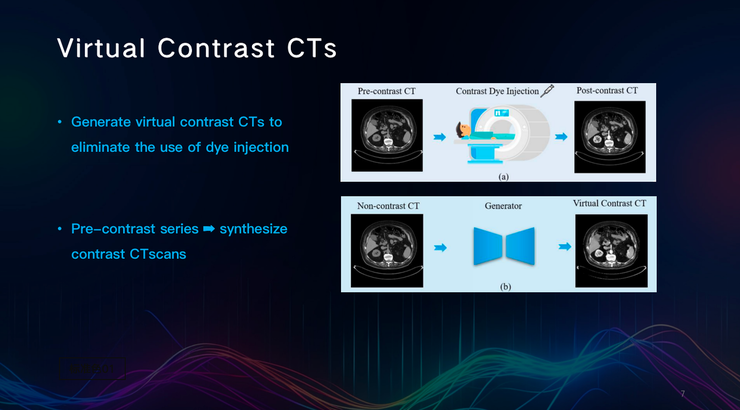
在测定肾功能时,医生需要向患者体内注射造影剂,以增强造影效果。但是,部分肾病患者对造影剂过敏,因此医生只能减少注射量,这可能会影响患者器官的成像效果,使医生不得不重复注射,以得到更清晰的图像,反而得不偿失。
那么,AI技术能否帮助医生在获得医学影像时,减少或避免使用造影剂?
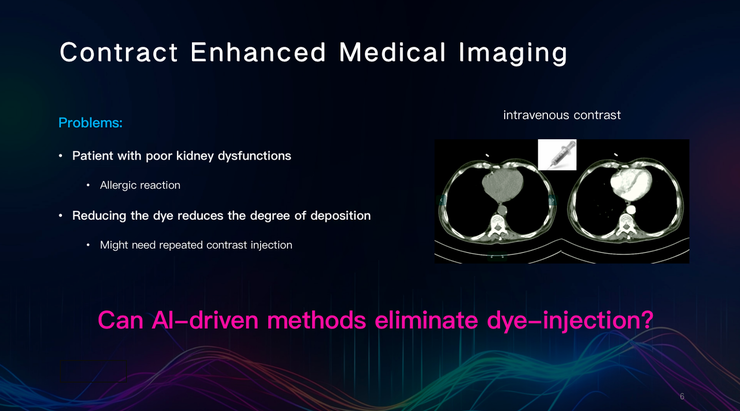
田英利团队尝试从没有使用造影剂的CT中,生成了虚拟对比增强CT,并与真实的使用造影剂的CT进行比较,得到了相似的效果。
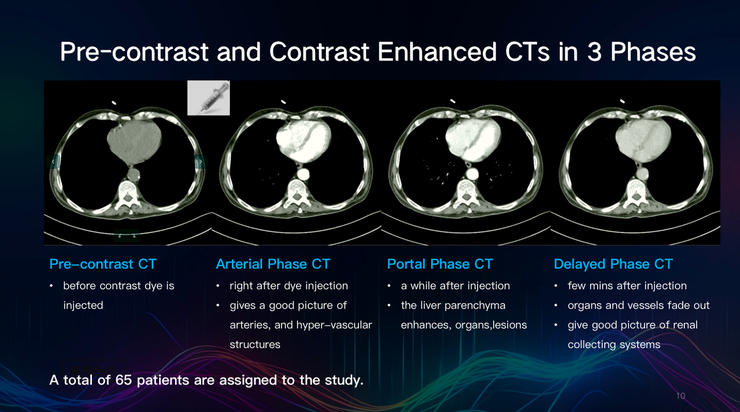
该技术应用于腹部器官成像时,面临的问题更为严峻,如造影前后器官的位置、方向会发生改变,腹部和骨盆处的CT扫描,只能从有限的数据中提取特征,同时还存在着模型过拟合等问题。

为此,田英利团队提出了细节感知双路径对比度增强框架,尝试将图像分为四个等级,并提取更详细的特征,填充到一起获得虚拟对比增强CT。以下使用65名患者的医学影像形成的数据集。
田英利指出,这是医学影像处理的一大挑战,相比大语言模型技术,这一方法的计算量需求也非常大,但考虑到患者的隐私,实际上并没有太大的数据集可供使用。
当未来拥有足够大的数据集后,就可以为每种不同的特定应用选择通用的医疗模型。
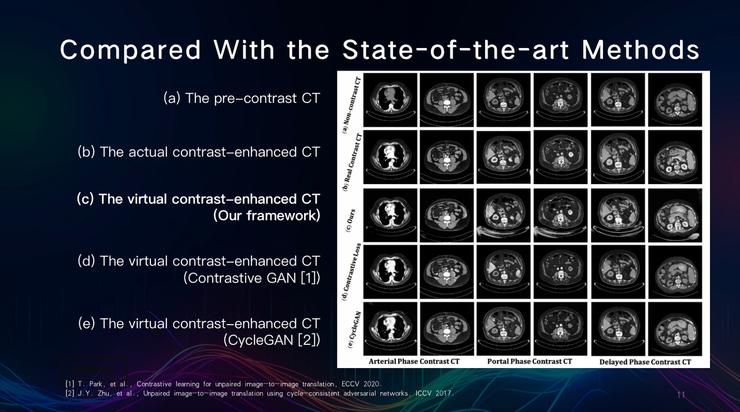
根据田英利所展示的对比图,第三行的虚拟对比增强CT效果最接近于真实的对比增强CT。
除上述研究外,田英利团队在AI驱动的肺结节自动诊断检测领域也有深入研究。
目前主要的肺癌检测方法可分为2D检测网络与3D检测网络两类,2D检测网络存在缺少时间特征、检测精度低、假阳性率高等缺陷,3D监测网络同样存在假阳性率高的问题。
这些技术缺陷导致在肺结节检测中,存在着许多遗留问题,如小结节难以检出、特异性低、鲁棒性低等。
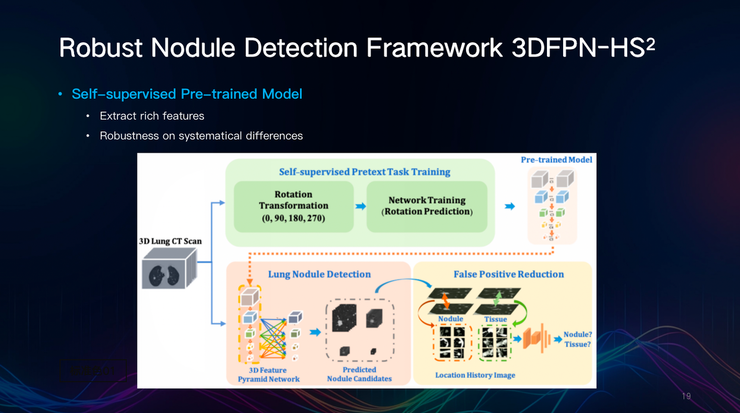
田英利团队研究的AI驱动的自动肺结节检测方法,使用了三维特征金字塔网络(3DFPN),具备更高的灵敏度和特异性。
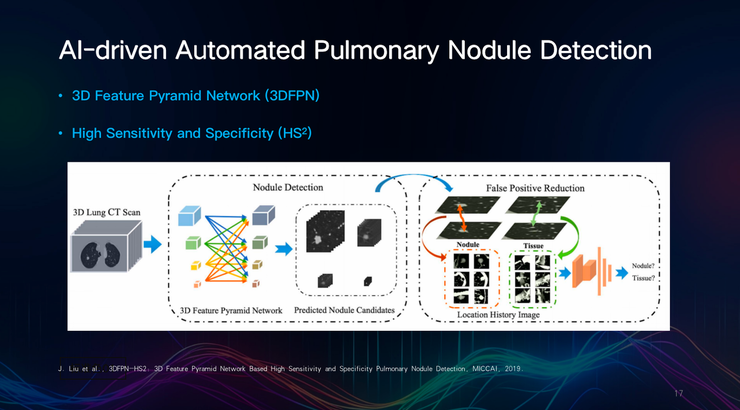
通过观察连续切片,田英利团队发现组织和结节在连续CT切片上的位置变化方向存在差异,并据此排除了许多假阳性案例。
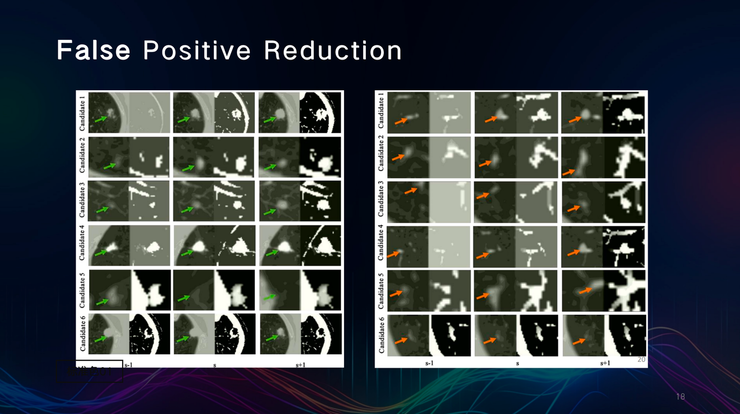
鲁棒结节检测框架3DFPN-HS2,采用了自监督预训练模型,能够从图像中提取丰富的特征,对系统差异更具稳健性。
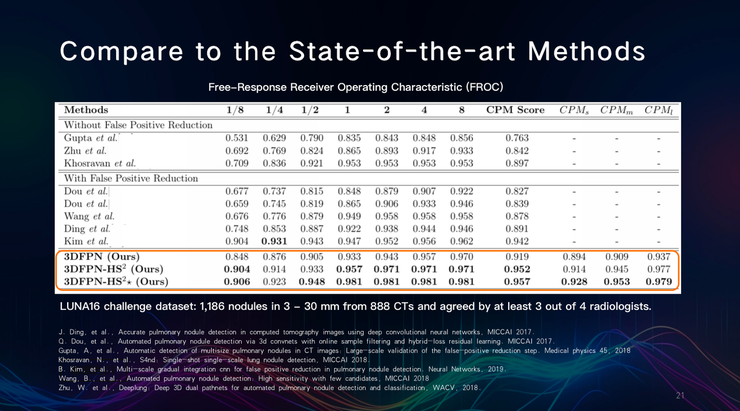
该方法在888个CT中找到了1186个3-30mm的肺结节,其中四分之三得到了放射科医生的认可。
此外,田英利还分享了AI驱动的肺结节自动诊断检测3D点云研究与AI驱动的肾脏和肾脏肿块自动诊断分割与分类。
她在演讲中指出,现有3D点云检测方法主要集中在小区域,团队的首要工作是处理肺部整体点云区域,并提出了3D电云结点检测框架。

在肾脏和肾脏肿块自动诊断分割与分类工作上,田英利团队提出了肾脏及肾脏肿块诊断框架,基于形态学表现判断肾肿块亚型。

结语
8月15日中午,GAIR大会的生命科学分论坛顺利告一段落。
当日活动延续了GAIR首日AI前沿创新的盛况,会上高朋满座,一时竟需要工作人员特殊加席,更有晚到的观众只能站立与会。生命科学的受关注程度也能由此可见一斑。
这个世界从不缺时代的注脚,GAIR存在的意义,就是让AI历史上的各种机缘与巧合,交织在一起,碰撞出新的思想与故事。
生命科学的未来一定会来,而这个未来将一定会属于实干者们!
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!