

“未来可能不是百模大战,而是万模群舞。”自ChatGPT掀起大模型的发展热潮之后,层出不穷的大模型已然蜂拥而入,风雷激荡。但在经历了最初的惊艳之后,行业已转移到对商业化落地的冷静观察,一方面业界认可垂直类应用模型有望率先实现落地应用,另一方面AI大模型的压缩和优化发展,使得向边缘端渗透的步伐也在加快,边缘算力的重要性正加速凸显。
以更直观的数据来看,有预测到2030年,边缘计算潜在市场将在10年内以48%的复合年增长率从2020年的90亿美元增长到2030年的4450亿美元。而且,中国是边缘算力的主战场,预估到2026年全球26%的网络边缘站点将位于中国。
通用GPU这一算力主流芯片在经过AI的淬炼之后,如何更进一步,承接AI大模型下沉至边缘端的新机遇?无疑,这将更是一场实打实的硬仗。
可重构架构打造算力第三极
在日前举办的第六届世界人工智能大会(WAIC)上,珠海芯动力、天数智芯、燧原科技、登临科技、爱芯元智、沐曦等企业展出的芯片、加速卡、软硬件解决方案和广泛的行业应用,成为WAIC不容错过的“风景”。


在WAIC舞台同场竞技的背后,暗藏的逻辑是通用GPU厂商比拼的赛点,已经从单纯的性能指标转向进入真实应用场景落地的较量,边缘侧的竞夺也走向白热化。
“随着AIGC兴起,算力将成为重要的生产力。相比云端,边缘侧应用场景更广泛,也更能促进生产力的提升创造价值,将对通用GPU产生巨大的市场机会。”芯动力CEO李原乐观表示。
显然这涉及通用GPU的算力、扩展性和编程性、生态等多维度的比拼。在这一市场,英伟达、AMD、英特尔等占据强势地位,且在当下国内半导体制造面临全面打压的情形下,我国通用GPU企业想要撕开一道口子,有专家建议不能按“常理”出牌,需要从架构、材料、封装等层面进行创新。
不走寻常路,发布首款基于可重构架构的GPGPU芯片RPP-R8的珠海芯动力可谓独辟蹊径。该公司在2017年成功研发出可重构并行处理器(RPP)架构,借助于独有的底层硬件架构,自带高性能、原生支持CUDA语言和低功耗等“光芒”,可对AI推理的性能进行深度优化。
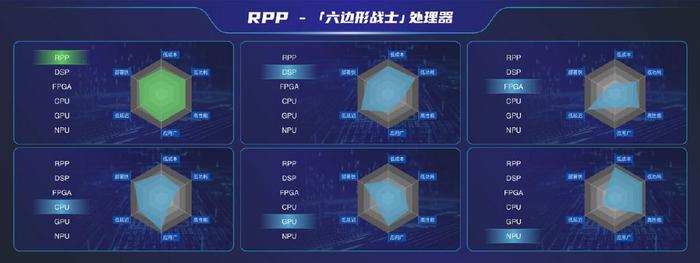
(RPP-六边形战士)
芯动力创始人李原分析,在可重构芯片面世之前,AI算力芯片主要有专用和通用GPU两大类,专用芯片性能虽强但编程能力差,有的通用GPU可编程性高但算力不强,要从激烈的竞争中脱颖而出,必须建立强大的优势,而第三类可重构芯片则将两类产品的优势“合二为一”,将跻身成为通用GPU的新一极。
据悉,RPP-R8作为一款通用GPU,每颗芯片内含有1024个计算核,相比传统GPU架构在同样的算力占用更小的芯片面积,实现了低功耗和高能效的有效平衡。此外,面积效率比可达到同类产品的7~10倍,能效比也超过3倍。而且,除原生支持CUDA之外,芯动力还拥有自主开发的工具链,使得其能够在cuDNN和TensorRT上实现API的兼容,同时也支持广泛的人工智能框架,如TensorFlow和Pytorch等,可全面满足高效并行计算及AI算力应用。
凭借高能效、高算力、低功耗、编程灵活等功力的“加持”,芯动力的RPP-R8在边缘侧的落地也在快马加鞭。
解决客户痛点 打开落地之旅
触及落地,尽管RPP-R8的性能和生态独树一帜,但作为一个新生“物种”,仍要面临逐级解锁的过程。
对此李原认为,边缘侧的市场巨大,传统市场的AI加速是刚需,通用GPU可替代专用芯片打入供应链;而新兴市场的需求如智能安防、机器视觉等市场也在持续扩容。但落地最重要的是要解决客户的痛点,要厘清市场的规律。
李原进一步剖析,芯片公司容易陷入提倡软硬件一体化的“怪圈”,但边缘侧终端客户对成本并非那么敏感,从产业链来看,芯片公司的客户大都为设备厂商,处于终端客户的下游,一方面芯片公司要学会将更多利润留给设备厂商,让他们有动力合作切入市场,另一方面芯片公司的客户大都有实力进行软件自主开发,因而要顺应软硬件分离的需求。

“因而,芯动力提供的是一个过硬的纯硬件,加上底层兼容x86、Arm、Windows等软件系统,与其他家的软件结合在一起可快速应用,让客户可顺畅地进行开发,有效帮助企业降低开发成本和产品周期,加速产品迭代与扩展,这是共赢之道和长久之道。”李原分析说。
基于这样的深刻洞察,加上直击痛点以及秉承让利的“哲学”,让芯动力的产品在落地之旅行进在“坦途”之上。李原提到,芯动力产品在智能安防、工业自动化等一些行业因可切实解决设备厂商的痛点,具有不可替代性,起量非常快,基本已处于拐点,更大规模的出货将顺利推进。
而这只是芯动力的“一小步”,未来还有更辽阔的征程。
李原介绍,芯动力已推出了基于可重构架构RPP-R8系列三种不同封装形式的GPGPU芯片,分别是AE8100、AE7100和AE6100;每一款芯片能够满足相对的应用场景需求。

“AE8100芯片面向边缘服务器等领域,对体积、功耗要求较高;AE7100芯片着力面向低功耗、小体积的应用场景;AE6100则聚焦于更小体积上承载更大的性能,正在与客户一起定义,针对机器视觉的Camera,融合信号采集、图像处理和GPU加速等功能,以代替前端的ISP,下半年将着重在工业视觉领域实现新的突破。”李原踌躇满志表示。
不再跟随?创新当道
在AIGC热潮掀起通用GPU的算力革命之际,一个更值得业界深思的问题也浮出水面。
“业界均认为AIGC大模型是一大风口,一大史诗级机遇。但值得深思的是,中国这么多AI公司和GPU公司,为什么美国开大模型之先河?如果不深刻反省,下次再有风口出现时我们还是被动跟随的境况。”李原的表述中藏着一些深层的内省。
李原进一步提议,对国内高科技界来说,最重要的是要思考未来十年会向什么方向演变?如果只是一味地跟随或Repeating,实际上没有太大价值,也走不出这一循环。
着眼于通用GPU发展,李原高瞻远瞩地表示,下一个十年比拼的是它的效率,而不仅是性能。为持续降低时延和提高带宽,将衍生出众多新技术,业界应着力解决芯片外部互联挑战,并尝试采用光电子技术,突破原有的方式才有可能实现超越。
此外,chiplet成为未来算力芯片“扩张”的必然之路,也将产生更多Cost Effective的效果。李原提到,芯动力也将在这一方向持续耕耘,加强与FPGA厂商合作共赢,切入更多场景,为客户带来更具想象力的价值。
对于CUDA兼容的走向,李原也洞察道,客户不在意底层是用CUDA或别的语言,最重要的是能够快速迭代、快速开发。在已经选用了CUDA语言的领域里,我们会尊重客户的选择,但在新的领域里,完全可以有自由的选择。
伴随生成式AI带动下的这场新兴科技革命,边缘计算的价值将被如芯动力这批“抢滩登陆”的企业率先释放,而芯动力的未来之路,也将成为国内众多行业的数字化、智能化转型升级的动力之源。
(来源/爱集微)
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!