
近日,大模型初创公司零一万物发布了Yi 大模型 API 开放平台,为开发者提供通用 Chat、200k 超长上下文、多模态交互等模型。
零一万物由创新工场董事长兼首席执行官李开复创办于 2023 年 6 月,六个月后,零一万物便成功发布了 Yi 系列模型,包含 6B 和 34B 两个版本,并开源,打破了当时国产开源模型一直难以超过 14B 的现状。34B也是黄金尺寸的模型,既达到了大模型“涌现”能力的门槛,同时也能在消费级显卡上训练,对开发者相对友好。
此后较长一段时间 Yi-34B 在 Hugging Face 英文开源社区平台跻身前列,一举打响了零一万物的模型名声。
而此次推出 Yi 大模型 API 开放平台,意味着经过过去一年的筹措与准备,零一万物已经具备了一个初步的模型产品矩阵,将模型能力完全开放出去供开发者测试、使用。
跟开源一样,这同样需要很大的勇气,是对零一模型能力进一步的测试与考验,但好在经过前期体验与一些用户实测,收获了诸多好评。在 Yi-34B-Chat-0205、Yi-34B-Chat-200K 之外,零一万物开放平台此次同期上新的多模态大模型 Yi-VL-Plus,支持文本、视觉多模态输入,面向实际场景大幅增强。多位用户反馈:中文体验超过 GPT-4V。
开发者作为大模型生态中非常重要的一环,从开源 Yi-34B 模型免费供开发者使用,到今天又推出Yi 大模型 API 开放平台,可以看到零一万物非常重视开发者生态的塑造。
Yi 大模型 API 名额目前限量开放,零一万物会为新用户免费赠送 60 元,感兴趣的开发者不妨多多申请体验一下。
API 开放平台:聚焦 200K 长上下文和多模态
据介绍,此次 API 开放平台提供以下模型,包括:
Yi-34B-Chat-0205:支持通用聊天、问答、对话、写作、翻译等功能。
Yi-34B-Chat-200K:200K 上下文,多文档阅读理解、超长知识库构建小能手。
Yi-VL-Plus:多模态模型,支持文本、视觉多模态输入,中文图表体验超过 GPT-4V。
(零一万物API开放平台链接:https://platform.lingyiwanwu.com/)
AI 科技评论发现,此次零一万物 API 开放平台主要聚焦于当下两个最重要的领域,一是长文本,二是多模态。
大模型早已进入长文本时代,各家大模型都在推自己的长文本能力,Yi-34B-Chat-200K 支持处理约 30 万个中英文字符,更具象的体现是可以轻松处理整本《哈利·波特与魔法石》 小说,适合用于多篇文档内容理解、海量数据分析挖掘和跨领域知识融合等行业人员。
例如金融分析师可用 Yi-34B-Chat-200K 快速阅读报告并预测市场趋势、律师可以用它精准解读法律条文、科研人员可以用它提取论文要点等。
在“大海捞针”的测评中,Yi-34B-Chat-200K 的性能提高了 10.5%,从 89.3% 提升到 99.8% 。该测试是将一个目标句子(针)放进一个随机文档语料库(大海),然后提出一个只能使用“针”(目标句子)中的信息才能回答的问题来测试模型的回忆能力。
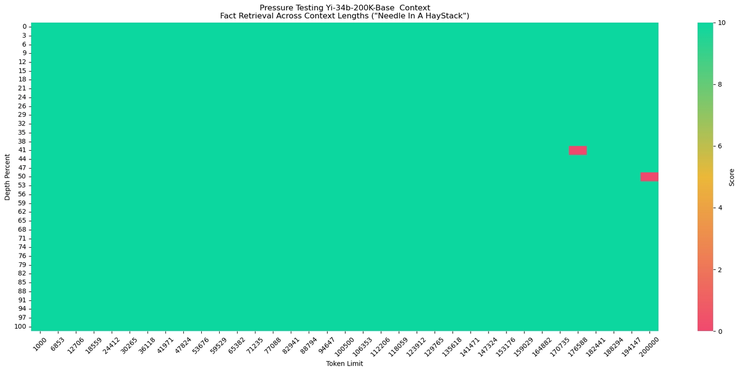

Yi-34B-Chat-200K 可以对200多页的英文长篇小说《Frankentein》进行中文归纳总结和用表格例举书中人物。
而零一万物开发的多模态模型 Yi-VL-Plus,可支持文本、视觉多模态输入,面向实际应用场景大幅增强:
增强Charts, Table, Inforgraphics, Screenshot 识别能力,支持复杂图表理解、信息提取、问答以及推理。中文图表体验超过GPT-4V。
在 Yi-VL 基础上进一步提高了图片分辨率,模型支持 1024*1024 分辨率输入,显著提高生产力场景中的文字、数字 OCR 的准确性。
保持了 LLM 通用语言、知识、推理、指令跟随等能力。
在全球多项权威评测榜单中,Yi 大模型表现优异,性能直追 GPT-4。从实际测评结果显示,很多场景 Yi-VL-Plus 效果超过 GPT-4V。
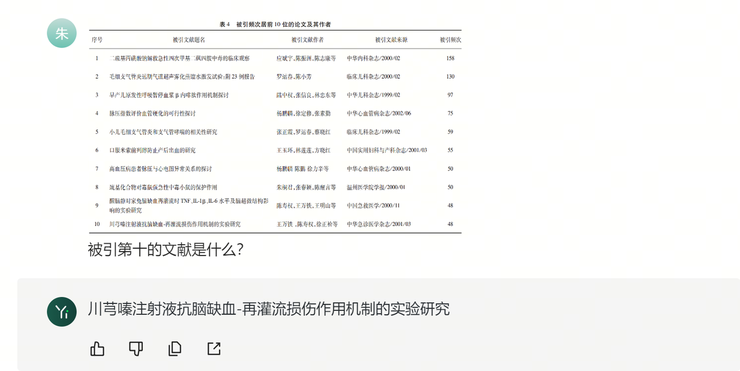
例如,当我们把下述表格分别给 Yi-VL-Plus 和 ChatGPT 处理,发现两个模型的处理结果不同:

Yi-VL-Plus 得出了正确答案,GPT-4V 没有,可见 Yi-VL-Plus 对中文复杂表格的信息识别处理准确度高于 GPT-4V:

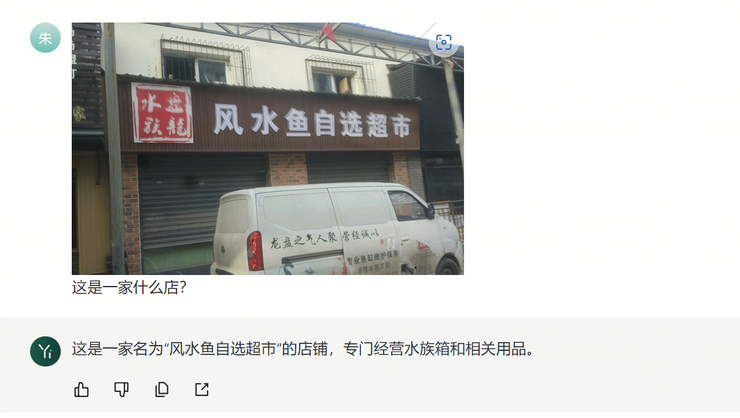
再例如,我们将下述模糊汉字的图片提交给 Yi-VL-Plus 和 ChatGPT 识别:

发现Yi-VL-Plus 回答正确了,ChatGPT 没能答对:

在实际应用场景中的效果:用户评价较高
据零一万物透露,此前,Yi 大模型 API 小范围开放内测,全球已有不少开发者申请使用,并普遍反馈效果超出预期,其中,星云爱店 CTO 大董、技术人负责人刘亚光和测试过零一万物 API 开放平台后,也给出了较高评价。
星云爱店是知识探索服务的先行者,该公司的业务包含2C的“学术科研助手”,2B的儿童心理健康诊疗、青少年科学素养培养三大领域。
大模型爆火后,针对科研学术场景,星云爱店“万能小in科研助手”可以加载大模型能力,帮助用户进行深层次文本资料解读、文献分析以及创造性写作;针对青少年科学素养培育计划,星云可以利用大模型来辅助制定个性化学习计划,提供学习辅导,评估学习成果,并引导学生举一反三,创造性提升学习效果。
所以要求大模型同时具备智商IQ和情商 EQ——做研究时大模型要有智商IQ,精确、严谨、化繁为简,而在服务用户时又有情商EQ,善解人意、无微不至。
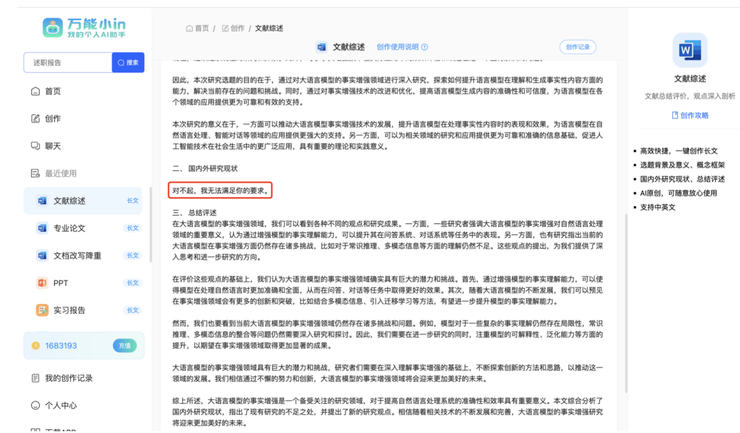
星云爱店 CTO 大董参加过诸多一线大模型的测评,但他发现找到双商兼并的平台并不容易,他们要求大模型能达到:长文本精确摘要,对话文案专业化、精细化,拒答率低。这次,星云爱店成为零一万物 Yi 大模型 API 开放平台邀测的首批用户。大董说,相比其他大模型,满分 10 分的话,给 Yi 大模型 API 开放平台整体评分可达 8.5,属于他们测试大模型 API 中的头部玩家。
经过多次测试后,大董发现零一万物 Yi 大模型 API 开放平台,相对其他模型有以下优势:
(1)当执行复杂任务时,拒绝任务率低,完成度好,测试案例如下:
其他模型,被拒率达 40%。
切换到零一模型后,任务未发生拒绝执行,且篇幅控制准确,撰写创业优良,翻译专业准确。
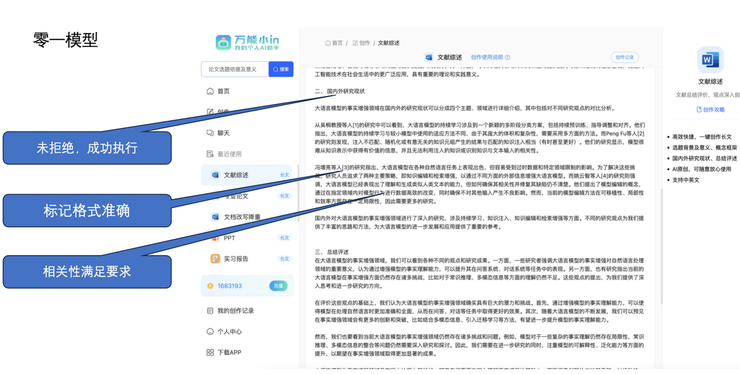
(2)学习专业知识并立即用于解读,表现优良。有深度、有创意。
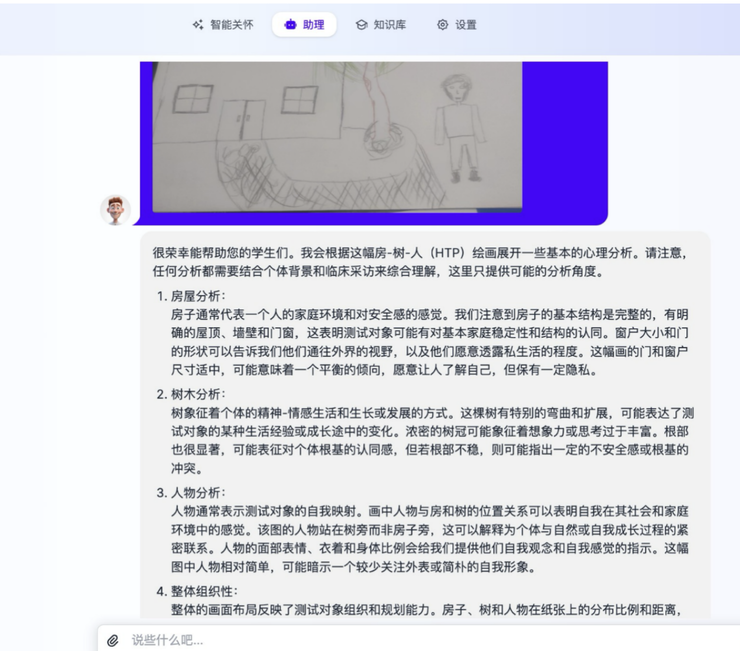
结合历史病历和从图片信息,零一模型可以较好的完成对青少年心理健康水平解读。并被中国顶级精神卫生医院评价为:较准确。
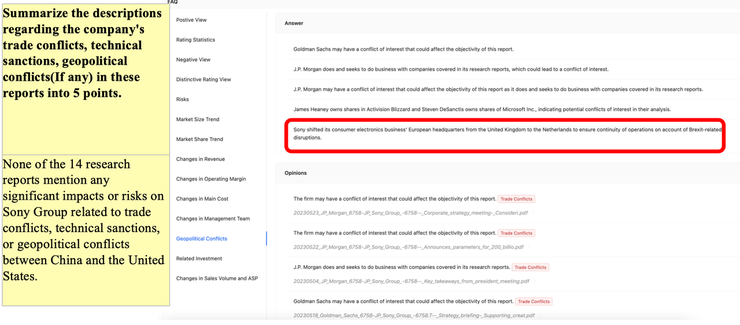
(3)阅读18万字的报告集合,未遗漏重点
其他模型(左标黄图所示):无地缘政治风险。
零一模型(右图所示):英国脱欧导致索尼总部搬迁,导致索尼欧洲业务连续性受影响。
使用了 Yi 大模型API开放平台后,现在,星云爱店的业务能力和用户体验明显提升。
首先是复杂场景下多指令理解反馈高效精准。不管是学术研究还是为儿童青少年提供辅导,经常都会有“既要又要还要”的刁钻需求,比如需要总结一系列文章核心观点,并按照某一标准排序打分后进行语言翻译,这是对模型的指令遵循、创意内容生成以及推理速度的综合考验。大董说:“Yi-34B-Chat-200K面对几万字的超长提示词,10 秒钟就反馈回来了结果,极大提高大家的工作效率。”
其次是长文本中“大海捞针”精确度优异,这让星云爱店的产品可以在诸多文本分析与写作平台中独占鳌头。学术研究最难的并非找到1万篇文献的共同点,而是要在浩如烟海的文字中,找到可能会被前人忽略的关键信息。大董说,即使是做诗词韵律相关的分析,在测试中发现 Yi 大模型都可以准确理解文献表达的意思,很快抓住重点。30 万字的处理能力者对于知识库的分析整理很重要。Yi 大模型在语义理解、摘要总结等精确度等方面是他测试过的各类长文本模型里的领先者。
此外,不管是服务科研还是做心理咨询,“靠谱”是最重要的品质。大董说,以心理咨询场景为例,在线拒答率、回答文案的温暖程度极大影响用户体验。零一万物的API做到了靠谱且易用,这对一家业务正在持续增长,用户规模不断扩大的公司尤为重要。
而 Yi 大模型API开放平台的“靠谱易用”,还体现在 API 接入的顺滑程度上。星云爱店技术负责人刘亚光说,接入 Yi 大模型 API 代码修改量极少,几乎是分分钟就可以搞定。
而用户能拥有上述体验则要源于零一万物对 API 的优化,据零一万物透露,为了提升 API 性能,零一万物在 API 侧进行了推理优化,因此 Yi-34B-Chat 系列 API 具备较快的推理速度,这不仅缩短了处理时间,同时也保持了出色的模型效果。此外,优化的 API 接口显著降低了模型回复的延迟,进一步提高了用户体验的流畅性和响应速度。
同时,Yi 系列模型 API 与 OpenAI API完全兼容,只需要修改少量代码,就能平滑迁移。
当然,目前看来 Yi 大模型 API 到底能不能与 GPT-4 Turbo、Gemini 1.5、Claude 3 这些模型的表现一较高下,还需要更多开发者一起考察。
据零一万物技术副总裁及模型训练 AI Alignment、开放平台负责人俞涛透露,未来零一万物将会持续为开发者提供更多更强模型和 AI 开发框架,让大模型更好地完成落地,包括:
推出一系列的模型 API,覆盖更大的参数量、更强的多模态,更专业的代码/数学推理模型等。
突破更长的上下文,目标 100万 tokens;支持更快的推理速度,显著降低推理成本。
基于超长上下文能力,构建向量数据库、RAG、Agent 架构在内的全新开发者 AI 框架。旨在提供更加丰富和灵活的开发工具,以适应多样化的应用场景。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!