
4月7日消息,阿里云通义千问开源320亿参数模型Qwen1.5-32B,可最大限度兼顾性能、效率和内存占用的平衡,为企业和开发者提供更高性价比的模型选择。目前,通义千问共开源了7款大语言模型,在海内外开源社区累计下载量突破300万。
通义千问此前已开源5亿、18亿、40亿、70亿、140亿和720亿参数的6款大语言模型并均已升级至1.5版本,其中,几款小尺寸模型可便捷地在端侧部署,720亿参数模型则拥有业界领先的性能,多次登上HuggingFace等模型榜单。此次开源的320亿参数模型,将在性能、效率和内存占用之间实现更理想的平衡,例如,相比14B模型,32B在智能体场景下能力更强;相比72B,32B的推理成本更低。通义千问团队希望32B开源模型能为下游应用提供更好的解决方案。


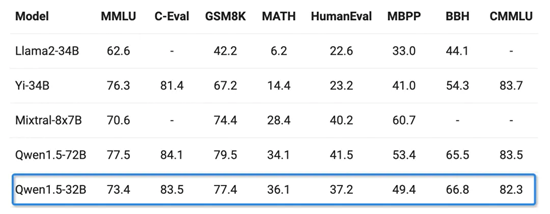
基础能力方面,通义千问320亿参数模型在MMLU、GSM8K、HumanEval、BBH等多个测评中表现优异,性能接近通义千问720亿参数模型,远超其他300亿级参数模型。
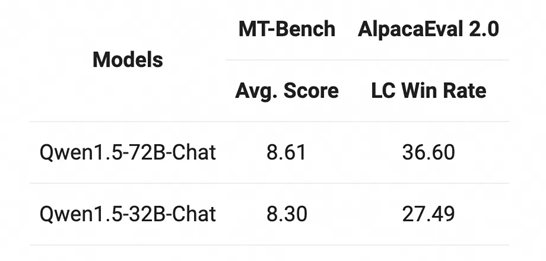
Chat模型方面,Qwen1.5-32B-Chat模型在MT-Bench评测得分超过8分,与Qwen1.5-72B-Chat之间的差距相对较小。
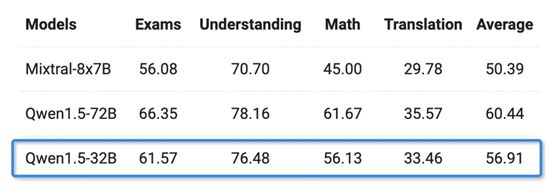
多语言能力方面,通义千问团队选取了包括阿拉伯语、西班牙语、法语、日语、韩语等在内的12种语言,在考试、理解、数学及翻译等多个领域做了测评。Qwen1.5-32B的多语言能力只略逊于通义千问720亿参数模型。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!