
在感受了ChatGPT和文生视频模型Sora接连带来震撼之后,所有人都会好奇,生成式AI与普通人的生活有什么关系?
手机厂商已经展示了生成式AI带来的全新体验,比如小米14系列的图像扩充,OPPO Find X7 Ultra的一键AI路人消除,荣耀Magic6的智慧成片和智慧创建日程。
如果说云端的生成式AI展示了AI的强大,那端侧AI的普及就是激发生成式AI创新的动力。
想要在端侧普及生成式AI,需要先解决算力、内存和生态三大难题。
异构计算和NPU解决算力瓶颈
生成式AI模型参数量大,算力是一个核心限制因素。
但大算力往往意味着高能耗,对于使用电池供电的AI手机和AI PC,想要兼顾高性能和低功耗,异构架构的价值十分明显。
异构架构,就是一个处理器当中包含多种不同类型的处理单元。
手机SoC就是典型的异构架构,包含擅长顺序控制,适用于需要低时延的应用场景的CPU;擅长高精度格式图像和视频并行处理的GPU;还有擅长标量、向量和张量数学运算,可用于核心AI工作负载的NPU。
异构计算的优势在于,可以根据应用的类型调用合适的处理器以达到最佳的能耗比,比如用GPU来完成重负荷游戏,用CPU执行多网页浏览,用NPU提升AI体验。


对于生成式AI,异构计算的优势更加明显,因为生成式AI有多种用例,比如只需要短暂运行的按需型用例;需要长时间运行的持续型用例,如AI视频处理;以及始终开启的泛在型用例,如PC需要持续监测用户的设备使用情况,不同的用例对处理器的需求不同。
以在高通骁龙平台上实现虚拟AI助手与用户语音互动交流来解释异构计算的重要性。
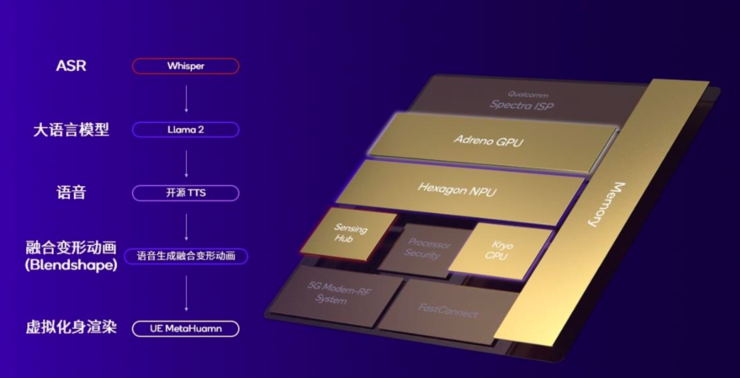
- 用于给虚拟AI助手下达指令,需要通过自动语音识别(ASR)模型转化为文本,这一步主要在高通传感器中枢运行。
- 然后需要通过Llama 2或百川大语言模型生成文本回复,这一模型在Hexagon NPU上运行
- 接下来要通过开源TTS(Text to Speech)模型将文本转为语音,这一过程需要CPU。
- 输出语音的同时,需要使用融合变形动画(Blendshape)技术让语音与虚拟化身的嘴型匹配,实现音话同步。此后,通过虚幻引擎MetaHuman进行虚拟化身渲染,渲染工作在Adreno GPU上完成。
- 最终通过协同使用高通AI引擎上所有的多样化处理模块,实现出色的交互体验。
高通自2015年推出第一代AI引擎,就采用的异构计算的架构,包含Kryo CPU、Adreno GPU、Hexagon DSP,这是高通保持在端侧AI领域领先的关键。
异构计算对于生成式AI的普及非常重要,其中的NPU又是关键。
比如在持续型用例中,需要以低功耗实现持续稳定的高峰值性能,NPU可以发挥其最大优势。在基于LLM和大视觉模型(LVM)的不同用例,例如Stable Diffusion或其他扩散模型中,NPU的每瓦特性能表现十分出色。
“高通NPU的差异化优势在于系统级解决方案、定制设计和快速创新。通过定制设计NPU并控制指令集架构(ISA),高通能够快速进行设计演进和扩展,以解决瓶颈问题并优化性能。”高通技术公司产品管理高级副总裁 Ziad Asghar表示。
小编了解到,高通对NPU的研究也是跟随需求的变化而演进,以Hexagon DSP为基础,进化为Hexagon NPU。
“从DSP架构入手打造NPU是正确的选择,可以改善可编程性,并能够紧密控制用于AI处理的标量、向量和张量运算。高通优化标量、向量和张量加速的的设计方案结合本地共享大内存、专用供电系统和其他硬件加速,让我们的方案独树一帜。”Ziad Asgha说。

Hexagon NPU从2015年时面向音频和语音处理的的简单CNN,到2016-2022年之间面向AI影像和视频处理,以实现增强的影像能力的Transformer、LSTM、RNN、CNN。
2023年,高通在Hexagon NPU中增加了Transformer支持。能够在终端侧运行高达100亿参数的模型,无论是首个token的生成速度还是每秒生成token的速率都处在业界领先水平。
测试数据显示,第三代骁龙8和三款Android以及iOS平台竞品的对比,在MLCommon MLPerf推理的不同子项中,例如图像分类、语言理解以及超级分辨率等,第三代高通骁龙8都保持领先。
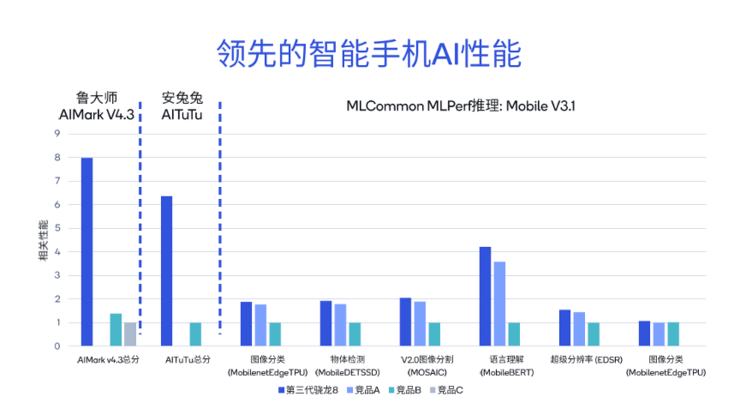
同样集成了高通AI引擎的骁龙X Elite,在面向Windows的UL Procyon AI推理基准测试中,ResNet-50、DeeplabV3等测试中,基准测试总分分别为X86架构竞品A的3.4倍和竞品B的8.6倍。

如何解决内存瓶颈?
限制生成式AI普及的不仅有计算能力的限制,内存限制也是大语言模型token生成的瓶颈,这要解决的是CPU、GPU、NPU的内存效率问题。

内存瓶颈来源于AI计算数据的读取和搬移。
例如,一个NxN矩阵和另一个NxN矩阵相乘,需要读取2N2个值并进行2N3次运算(单个乘法和加法)。在张量加速器中,每次内存访问的计算操作比率为N:1,而对于标量和向量加速器,这一比率要小得多。
解决内存瓶颈的挑战,高通有微切片和量化等关键技术。
2022年发布的第二代骁龙8,微切片推理利用HexagonNPU的标量加速能力,将神经网络分割成多个能够独立执行的微切片,消除了高达10余层的内存占用,市面上的其他AI引擎则必须要逐层进行推理。
量化技术也是解决内存挑战的关键。高通Hexagon NPU原生支持4位整数(INT4)运算,能够提升能效和内存带宽效率,同时将INT4层和神经网络的张量加速吞吐量量提高一倍。
在最新的第三代骁龙8中,Hexagon NPU微架构升级,微切片推理进一步升级,支持更高效的生成式Al处理,并降低内存带宽占用。
此外,Hexagon张量加速器增加了独立的电源传输轨道,让需要不同标量、向量和张量处理规模的AI模型能够实现最高性能和效率。共享内存的带宽也增加了一倍。
还有一个非常关键的升级,第三代骁龙8支持业界最快的内存配置之一:4.8GHzLPDDR5x,支持77GB/s带宽,能够满足生成式AI用例日益增长的内存需求。
更高性能的内存结合升级的微切片和量化技术,能最大程度消除端侧AI普及内存的瓶颈。当然,生成式AI模型也在变化。
“高通AI引擎中集成了模型压缩等更多技术,以确保模型能够在DRAM上顺利运行。”Ziad Asghar说,“在模型端,我们看到MoE(Mixture of Experts)模型兴起的趋势,这一类型的模型能够将特定部分放在内存中运行,其他的放在内存外,对模型进行优化。”
计算和内存限制的问题之后,是更具挑战性的生态问题。
如何降低AI开发门槛?
AI潜力的爆发需要生态的繁荣,生态的繁荣需要足够多的开发者,最终这就变成了一个AI开发门槛的问题。
对于硬件平台的提供者来说,可以最大化降低开发者的使用门槛,能够让开发者用高级语言开发的程序简单高效地运行在AI引擎上。

高通做了非常多的工作,高通AI软件栈(Qualcomm AI Stack),支持目前所有的主流AI框架,包括TensorFlow、PyTorch、ONNX、Keras;它还支持所有主流的AI runtime,包括DirectML、TFLite、ONNX Runtime、ExecuTorch,以及支持不同的编译器、数学库等AI工具。
“我们还推出了Qualcomm AI studio,为开发者提供开发过程中需要用到的相关工具,其中包括支持模型量化和压缩的高通AI模型增效工具包(AIMET),能够让模型运行更加高效。”Ziad Asgha进一步表示,“基于高通AI软件栈和核心硬件IP,我们能够跨高通所有不同产品线,将应用规模化扩展到不同类型的终端,从智能手机到PC、物联网终端、汽车等。”
AI生态的繁荣,还需要多方的共同努力,高通支持Transformer的Hexagon NPU,以及异构的高通AI引擎,已经提供了很好的基础。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!