
大模型的诞生,让科技巨头与创业公司们在新一轮的竞赛中再次鸣枪出发,OpenAI、Anthropic、Mistral等创业之星的升起更是证明了在新技术的影响下,大厂并不存在绝对的优势。
不久前,苹果叫停了启动十多年且投入数十亿美元的自动驾驶电动汽车项目,美国总部裁员了600多人,另有近2000名员工转到AI部门。
然而,在目前市场上的主流智能手机品牌中,苹果几乎是唯一一家尚未正式推出大模型的厂商。长期处在领头羊地位的苹果,似乎在大模型这一局中罕见地落后了。
4月8日,苹果发表了一个名为“Ferret-UI”的新工作,这是一个能“看懂”手机屏幕上并能执行任务的多模态模型,专为增强对移动端 UI 屏幕的理解而定制,配备了引用(referring)、定位(grounding)和推理(reasoning)功能。


论文链接:https://arxiv.org/pdf/2404.05719.pdf
半年前,苹果和哥伦比亚大学研究团队联合发布的多模态大模型“Ferret”就已具有较高的图文关联能力,而“Ferret-UI”则是更聚焦移动端、关注用户交互。
研究团队认为,Ferret-UI 具备了解决现有大部分通用多模态大模型所缺乏的理解用户界面 (UI) 屏幕并与其有效交互的能力。
UI 任务表现超越GPT-4V
将重点放在 UI 后,Ferret-UI 有何亮点呢?
苹果的团队比较了 Ferret-UI-base、Ferret-UI-anyres、Ferret 和 GPT-4V 在所有 UI 任务上的性能,并在高级任务上将开源的 UI 多模态模型 Fuyu 和 CogAgent 也纳入对比之中。
首先是基础的 UI 任务性能测试。
Ferret-UI 在大多数基础 UI 任务上都展现出了优越的性能,尤其是在与iPhone相关的任务上,除了“查找文本”任务外,它在所有任务上都超过了Ferret和GPT-4V。

在OCR(光学字符识别)、图标识别和控件分类等基础 UI 任务上,Ferret-UI 的平均准确率分别为72.9%、82.4%和81.4%,远超 GPT-4V 的平均准确率,后者分别为47.6%、61.3%和37.7%。
在安卓任务上,GPT-4V 的性能显著下降,特别是在定位任务上,这可能是因为安卓屏幕上的小部件更多且更小,使得定位任务更具挑战性。
值得一提的是,在OCR任务中,模型预测的是目标区域旁边的文本,而不是目标区域内的文本。这对于较小的文本和非常靠近其他内容的文本来说很常见。
而 Ferret-UI 却能够准确预测部分被切断的文本,即使在OCR模型返回错误文本的情况下也是如此。
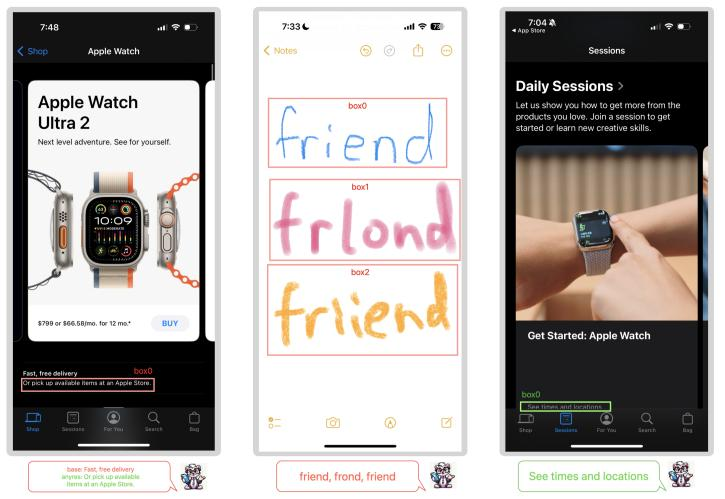
在查找文本、查找图标和查找控件等定位任务上,Ferret-UI也展现出了优越的性能。
而在高级 UI 任务性能的比拼中,Ferret-UI 同样表现优秀。在详细描述(DetDes)、感知对话(ConvP)、交互对话(ConvI)和功能推断(FuncIn)等高级任务上,Ferret-UI 展现了与 GPT-4V 相当的性能,并且在某些任务上超过了GPT-4V。
而与开源UI多模态模型 Fuyu 和 CogAgent 相比,Ferret-UI 在大多数任务上均实现超过。特别是在 iPhone 平台上,Ferret-UI 的性能得分显著高于 Fuyu 和 CogAgent。
而且,尽管 Ferret-UI 的训练数据集没有包含特定的安卓数据,但它在安卓平台的高级任务上仍表现出了可观的性能,表明了模型具有在不同操作系统间的 UI 知识迁移能力。
Anyres 技术解决屏幕长宽比各异难题
那么,Ferret-UI 是如何做到在多项 UI 任务中表现出色的呢?
Ferret-UI 的一个关键创新是在 Ferret 的基础上引入了“任何分辨率”(any resolution,简称anyres)技术。这项技术是为了解决移动设备 UI 屏幕长宽比多样化的问题而提出的。
虽然 Ferret-UI-base 紧密遵循 Ferret 的架构,但 Ferret-UI-anyres 加入了额外的细粒度图像特征,尤其是一个预训练的图像编码器和投影层为整个屏幕生成图像特征。
对于根据原始图像长宽比获得的每个子图像,都会生成额外的图像特征;对于具有区域引用的文本,一个视觉采样器会生成相应的区域连续特征。
大型语言模型(LLM)则使用全图表示、子图表示、区域特征和文本嵌入来生成响应。
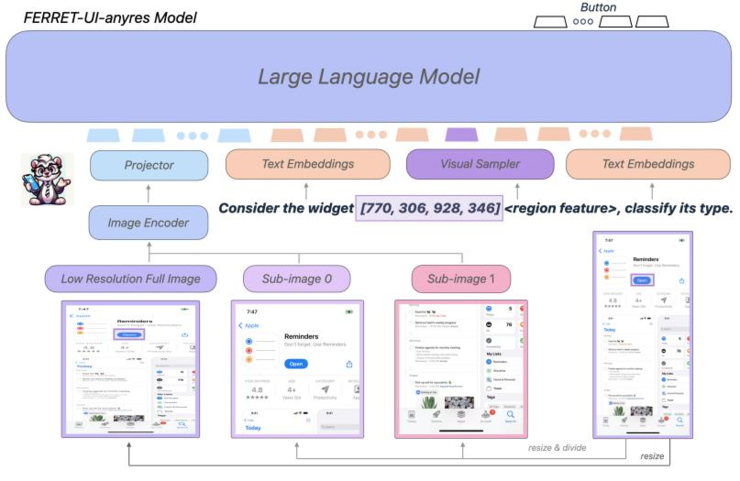
Ferret-UI-anyres架构
不过,Anyres 技术有何特别之处?
传统的模型可能需要固定大小的输入,但手机等移动设备的屏幕大小和长宽比各异,显然给模型的输入带来了挑战。
为了适应这一点,Ferret-UI 将屏幕分割成多个子图像,这样可以对每个子图像进行放大,从而捕捉到更多的细节。
具体来说,对于每个基于原始图像长宽比获得的子图像,都会生成额外的图像特征。对于具有区域引用的文本,视觉采样器会生成相应的区域连续特征。
这种方法不仅适用于不同长宽比的屏幕,还提高了模型对UI元素的细节识别能力,能够突出显示屏幕上的小型对象,如图标和文本,对于提高模型的识别和定位精度至关重要。
另外,苹果研究团队还设计了一个分层次的实验方法,从简单到复杂,以逐步提升 Ferret-UI 模型的能力。
从基础的识别和分类任务开始,Ferret-UI 模型建立了对 UI 元素的基本理解,学会了识别和分类 UI 元素,为处理更复杂的任务打下基础。
接着逐步过渡到需要更高层次理解的对话和推断任务。随着模型能力的提高,任务变得更加复杂,要求模型不仅要识别 UI 元素,还要理解它们的功能和上下文。高级任务的设计为模型提供了必要的背景知识和理解能力,使其能够处理复杂的UI交互。
分层次的任务设计不仅有助于模型逐步学习,还能够确保模型在面对更复杂的 UI 交互时具有足够的背景知识和理解能力。通过这种方式,Ferret-UI 能够更好地理解和响应用户的指令,提供更加准确和有用的交互。
从基础的识别和分类到高级的描述和推断,Ferret-UI 在面对真实世界中的UI交互时,能够提供准确和有用的响应。再结合 anyres 技术处理不同分辨率的屏幕,进一步增强了其在实际应用中的有效性和用户体验。
结语
面对当下激烈的大模型“厮杀”,科技巨头们亟需思考如何对市场战略和产品进行与时俱进的布局,苹果自然也不例外。
无论是Ferret-UI、Ferret-UI的前身 Ferret 还是旨在改善与语音助手交互的ReALM,苹果正一步步推进着能够读取屏幕信息的模型研究。
Ferret-UI 能够在移动设备上提供高质量的UI理解和交互,但它能否成为一个强大的工具,促使 iPhone 引入 AI,让苹果从稍显落后的境地反超呢?
让我们拭目以待。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!