
有很多童鞋可能不知道忆阻器是什么?在开始今天的话题之前,先为大家普及下忆阻器是什么。
所谓忆阻器,全称记忆电阻器(Memristor),是继电阻、电容、电感之后的第四种电路基本元件,表示磁通与电荷之间的关系,这种组件的的电阻会随着通过的电流量而改变,而且就算电流停止了,它的电阻仍然会停留在之前的值,直到接受到反向的电流它才会被推回去,等于说能“记住”之前的电流量。
简言之,忆阻器(memristor)可以在断电之后,仍能“记忆”通过的电荷,其所具备的这种特性与神经突触之间的相似性,使其具备获得自主学习功能的潜力。因此,基于忆阻器的神经形态计算系统能为神经网络训练提供快速节能的方法,但是,图像识别模型之一 的卷积神经网络还没有利用忆阻器交叉阵列的完全硬件实现。
不过,清华大学微电子所、未来芯片技术高精尖创新中心钱鹤、吴华强教授团队与合作者在《自然》在线发表了题为“ Fully hardware-implemented memristor convolutional neural network ”的研究论文,报道了基于忆阻器阵列芯片卷积网络的完整硬件实现。
他们提出用高能效比、高性能的均匀忆阻器交叉阵列实现 CNN,该实现共集成了 8个 PE ,每个 PE 包含2048 个单元的忆阻器阵列,以提升并行计算效率。此外,研究者还提出了一种高效的混合训练方法,以适应设备缺陷,改进整个系统的性能。研究者构建了基于忆阻器的五层 CNN 来执行 MNIST 图像识别任务,识别准确率超过 96%。


除了使用不同卷积核对共享输入执行并行卷积外,忆阻器阵列还复制了多个相同卷积核,以并行处理不同的输入。相较于当前最优的图形处理器(GPU),基于忆阻器的 CNN 神经形态系统的能效要高出一个数量级,且实验证明该系统可扩展至大型网络,如残差神经网络。该结果或可促进针对深度神经网络和边缘计算提供基于忆阻器的非冯诺伊曼(non-von Neumann)硬件解决方案,在处理卷积神经网络(CNN)时的能效比图形处理器芯片(GPU)高两个数量级,大幅提升了计算设备的算力,成功实现了以更小的功耗和更低的硬件成本完成复杂的计算。
首个完全基于忆阻器的 CNN 硬件实现
据介绍,当前国际上的忆阻器研究还停留在简单网络结构的验证,或者基于少量器件数据进行的仿真。基于忆阻器阵列的完整硬件实现仍然有很多挑战。
比如,器件方面,需要制备高一致、可靠的阵列;系统方面,忆阻器因工作原理而存在固有缺陷(如器件间波动、器件电导卡滞、电导状态漂移等),会导致计算准确率降低;架构方面,忆阻器阵列实现卷积功能需要以串行滑动的方式连续采样、计算多个输入块,无法匹配全连接结构的计算效率。
在这些研究成果的基础之上,钱鹤、吴华强团队逐渐优化材料和器件结构,制备出了高性能的忆阻器阵列。
在器件方面,该研究成功实现了一个完整的五层 mCNN,用于执行 MNIST 手写数字图像识别任务。优化后的材料堆栈(material stack)能够在 2048 个单晶体管单忆阻器(one-transistor–one-memristor,1T1R)阵列中实现可靠且均匀的模拟开关行为。使用该研究提出的混合训练机制后,实验在整个测试集上的识别准确率达到了 96.19%。
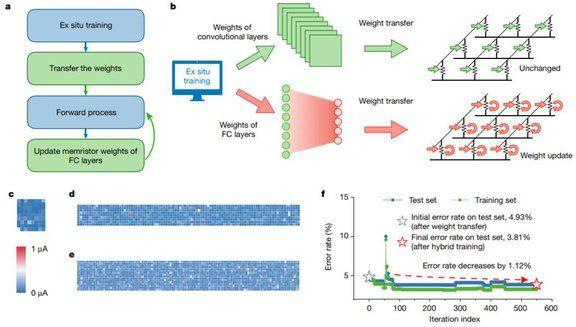
此外,该研究在三个并行忆阻器卷积器中复制了卷积核,从而将 mCNN 的延迟降低约 2/3。该研究得到的高度集成神经形态系统弥补了基于忆阻器的卷积运算和全连接 VMM 之间的吞吐量差距,从而为大幅提升 CNN 效率提供了可行的解决方案。
架构方面,之前基于忆阻器的 demo 依赖于单一阵列,其主要原因是生成高度可重复的阵列面临巨大挑战。忆阻器设备的易变性和不完美特性被认为是神经形态计算应用的主要瓶颈。该研究提出了一种基于忆阻器的灵活计算架构,适用于神经网络。
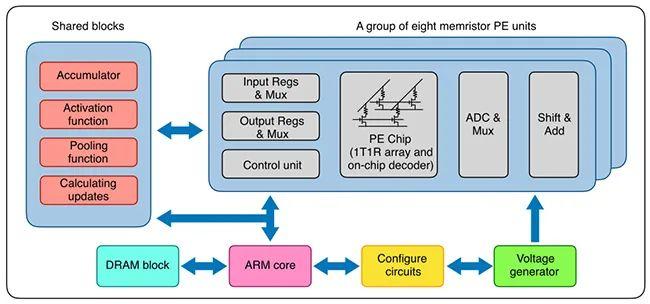
忆阻器单元使用 TiN/TaO_x/HfO_x/TiN 的材料堆叠,通过调节电场和热,在增强(SET)和抑制(RESET)这两种情况下均展现出连续电导率调节能力。材料和制造流程与传统的 CMOS 流程兼容,从而使忆阻器阵列可以方便地内置在晶圆的后段制程中,以减少流程变动,实现高复现性。得到的交叉阵列在同等的编程条件下具备均匀的模拟开关行为。因此,多忆阻器阵列硬件系统基于自定义印刷电路板(PCB)和 FPGA 评估板(ZC706, Xilinx)构建。
系统方面,该系统主要包含八个基于忆阻器的处理元件(PE)。每个 PE 集成了 2048 个单元的忆阻器阵列。每个忆阻器与晶体管的漏级端相连,即 1T1R 配置。核心 PCB 子系统具备八个忆阻器阵列芯片,每个忆阻器阵列具备 128 × 16 个 1T1R 单元。在水平方向上共有 128 条并行字线和 128 条源线,在垂直方向上共有 16 条位线。
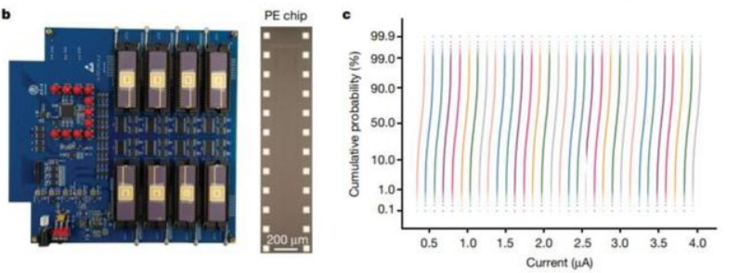
该阵列展示了极具可重复性的多级电导率状态,成功证明了存算一体架构全硬件实现的可行性。
有何优势?
众所周知,CNN 是最重要的深度神经网络之一,在图像处理相关任务中发挥关键作用,如图像识别、图像分割和目标检测。
CNN 的典型计算步骤需要大量滑动卷积操作。从这个方面来看,CNN 需要支持并行乘积累加运算(MAC)的计算单元。而这需要重新设计传统的计算系统,以便以更高的性能、更低的能耗来运行 CNN,这些计算系统包括通用应用平台(如 GPU)、应用特定的加速器等。
但是,计算效率的进一步提升最终受限于系统的冯诺伊曼架构,该架构中的内存和处理单元是物理分离的,从而导致大量能耗,以及不同单元之间数据搬运的高延迟。
与之相反,基于忆阻器的神经形态计算可以提供非冯诺伊曼计算范式,即存储数据,从而消除数据迁移的消耗。忆阻器阵列直接使用欧姆定律进行加法运算,使用基尔霍夫定律(Kirchhoffs law)进行乘法运算,因而能够实现并行存内(in-memory)MAC 运算,从而模拟存内计算(in-memory computing),并实现速度和能效的大幅提升,减小误差。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!