
近日谷歌宣布,向非盈利性 LLVM 基金会提供今年 4 月开源的 Multi-Level Intermediate Representation(MLIR)架构,一个与 TensorFlow 紧密结合的表示格式和编译器实用工具库,该架构介于模型表示和低级编译器/执行器(二者皆可生成硬件特定代码)之间。谷歌希望通过向社会提供该架构来激励更多的创新,从而进一步加速 AI 领域发展。


MLIR 与 TensorFlow 的渊源
在过去,若想解决多级别堆栈问题,则需要我们构建新的软硬件堆栈生成器,这也意味着必须为每个新路径重新构建优化与转换传递。
TensorFlow 生态系统包含许多编译器和优化器,可在多个级别的软硬件堆栈上运行。作为 TensorFlow 的日常用户,在使用不同种类的硬件(GPU、TPU、移动设备)时,这种多级别堆栈可能会表现出令人费解的编译器和运行时错误。
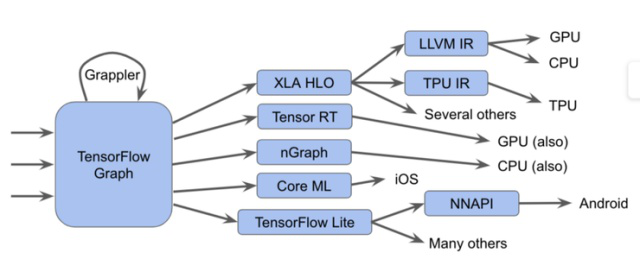
图 1 TensorFlow 组件概述
TensorFlow 能够以多种不同的方式运行,如:
- 将其发送至调用手写运算内核的 TensorFlow 执行器
- 将图转化为 XLA 高级优化器(XLA HLO)表示,反之,这种表示亦可调用适合 CPU 或 GPU 的 LLVM 编辑器,或者继续使用适合 TPU 的 XLA。(或者将二者结合)
- 将图转化为 TensorRT、nGraph 或另一种适合特定硬件指令集的编译器格式
- 将图转化为 TensorFlow Lite 格式,然后在 TensorFlow Lite 运行时内部执行此图,或者通过 Android 神经网络 API(NNAPI)或相关技术将其进一步转化,以在 GPU 或 DSP 上运行
但事实上,多级别堆栈的复杂性远远超过图 1 所示。为了更好解决 TensorFlow 用户在使用不同种类的硬件(GPU、TPU、移动设备)时,由于多级别堆栈而导致的编译器与运行时错误,我们开源了一个全新的中介码与编译器框架 MLIR。
什么是 MLIR
MLIR(或称为多级别中介码)是一种表示格式和编译器实用工具库,介于模型表示和低级编译器/执行器(二者皆可生成硬件特定代码)之间,在生产质量组件的支持下,能够对优化编译器设计与实现进行全新探索。

图 2 谷歌 MLIR(相关 ppt 见文末)
MLIR 深受 LLVM 的影响,并不折不扣地重用其许多优秀理念,比如拥有灵活的类型系统,可在同一编译单元中表示、分析和转换结合多层抽象的图等。这些抽象包括 TensorFlow 运算、嵌套的多面循环区域乃至 LLVM 指令和固定的硬件操作及类型。
为区分不同的硬件与软件受众,MLIR 提供「方言」,其中包括:
- TensorFlow IR,代表 TensorFlow 图中可能存在的一切
- XLA HLO IR,旨在利用 XLA 的编译功能(输出到 TPU 等)
- 实验性仿射方言,侧重于多面表示与优化
- LLVM IR,与 LLVM 自我表示之间存在 1:1 映射,可使 MLIR 通过 LLVM 发出 GPU 与 CPU 代码
- TensorFlow Lite,将会转换以在移动平台上运行代码
每种方言均由一组存在不变性的已定义操作组成,如:「这是一个二进制运算符,输入与输出拥有相同类型。」
MLIR 没有众所周知的固定或内置的操作列表(无「内联函数」),方言可完全定义自定义类型,即 MLIR 如何对 LLVM IR 类型系统(拥有一流汇总)、域抽象(对量化类型等经机器学习 (ML) 优化的加速器有着重要意义),乃至未来的 Swift 或 Clang 类型系统(围绕 Swift 或 Clang 声明节点而构建)进行建模。
另外值得一提的是,虽然 MLIR 充当 ML 的编译器,但它同样支持在编译器内部使用机器学习技术。MLIR 的扩展性有助于探索代码降阶策略,并在抽象之间执行逐步降阶。
MLIR 开放的意义
机器学习现在的使用范围非常广泛,它可以在从包含 GPU 和 TPU 的云基础设施到移动电话,甚至是最小的硬件(例如为智能设备供电的微控制器)上运行。正是因为将硬件和开源软件框架(如:TensorFlow)的优势相结合,今天我们才能看到所有令人难以置信的 AI 应用成为可能。无论是预测极端天气(https://www.youtube.com/watch?v=p45kQklIsd4);帮助有语言障碍的人更好地沟通;还是协助农民检测农作物疾病。

图 3 AI 协助农民进行检测(https://www.blog.google/technology/ai/ai-takes-root-helping-farmers-identity-diseased-plants/)
但随着所有这些进展如此迅速,企业工厂方正在努力跟上不同的机器学习软件框架与各种不断增长的硬件组合。机器学习生态系统依赖于许多不同的技术,而这些技术通常具有不同的复杂程度,因而无法很好地协同工作。
管理这种复杂性的负担最终落在了研究人员、企业和开发人员身上。通过减缓新的机器学习驱动产品从研究到实现的速度,这种复杂性将会影响我们解决具有挑战性现实问题的能力。
今年早些时候,我们发布了 MLIR,这是一种开源机器学习编译器基础架构,可以解决因软件和硬件碎片不断增加而导致的复杂性,并且可以更轻松地构建 AI 应用程序。它提供了新的基础设施和设计理念,使得机器学习模型能够在任何类型的硬件上一致地表示和执行。现在,我们宣布我们会向非营利性 LLVM 基金会(http://llvm.org/foundation/)提供 MLIR ,这也将使整个行业更快地采用 MLIR。

图 4 MLIR 生态联盟
MLIR 旨在成为 ML 基础架构的新标准,并得到全球硬件和软件合作伙伴的大力支持,包括 AMD,ARM,Cerebras,Graphcore,Habana,IBM,Intel,Mediatek,NVIDIA,Qualcomm Technologies,Inc,SambaNova Systems,Samsung,Xilinx 的小米——占全球数据中心加速器硬件的 95%以上,超过 40 亿部手机和无数的物联网设备。在谷歌,MLIR 正在整合并用于我们所有的服务器和移动硬件工作。
机器学习已经走过了漫长的道路,但之后的路仍然很长。通过 MLIR,人工智能将通过赋予研究人员更大规模地训练和部署模型的能力,以及在不同硬件上具有更高的一致性、速度和简单性,从而更快地推进该领域的发展。这些创新也可以迅速进入你每天使用的产品中,并在你的所有设备上顺利运行。我们也希望通过 MLIR 能够最终实现 AI 对地球上的每个人都更有帮助、更有用的愿望。
关于 MLIR 的 ppt:
http://llvm.org/devmtg/2019-04/slides/Keynote-ShpeismanLattner-MLIR.pdf
文章相关链接:
https://www.blog.google/technology/ai/mlir-accelerating-ai-open-source-infrastructure/
MLIR 开源地址:
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!