


上世纪80年代初,数据库系统逐步走上信息技术舞台的中央;2000年开始,大数据技术兴起;再到2010年后,云计算热度持续升温;技术的进程走到了今天这个奇妙的节点,看向未来有几个趋势可能会发生。
仅以此文,分享一些浅见和实践。
三段交叉的技术史
过去40年,数据库系统、大数据和云计算三项技术交替兴起。
首先是数据库系统,成型于上个世纪80年代,是计算机领域三大基础软件系统之一。早期的关系型数据库以甲骨文数据库为代表,取得了巨大的商业成功。后来出现了MySQL、PostgreSQL等开源的关系型数据库。
90年代,随着关系型数据库的广泛应用,产生了大量的数据,分析这些结构化的数据对分析型的数据库系统提出了很高的要求,因而在90年代涌现出了一批分析型数据库系统。
世纪更迭,2000年到2010年,大数据技术走上历史舞台的时代。大数据技术诞生的原因有以下两方面:
一是大数据的产生。随着以谷歌为代表的互联网公司的发展,产生了大量数据。
二是获取、处理、分析数据的方式不一样。比如说银行最简单的交易、转账,对隔离、一致性、持久性有非常严格的要求,大数据不一样,单一数据对最终结果没有特别影响,这种应用场景和传统的联机交易关系型数据库完全不同。
于是,大数据系统应运而生。谷歌发表了耳熟能详的分布式文件系统、分布式表格存储、MapReduce三大论文,奠定了今天大数据的整个技术生态圈的基石。
2010年后,另一个趋势是云计算的热度逐渐升温。云计算的本质就是利用分布式技术将资源高效池化,而对应用做到透明的集中式部署。
把云计算、数据库以及大数据发展结合起来看,数据系统本质上就是对数据从生产到处理、消费、存储的一个全链路的过程。
云计算对数据处理系统产生了非常大的影响:
第一, 云原生技术在数据处理系统深入的应用;
第二, 传统的关系型数据库和传统大数据生态正在快速发生融合。
业界发展的趋势,是资源的池化、资源解耦,以云原生、分布式的技术为基础,打造下一代的数据处理系统。举例来说,阿里云数据库之所以能够支撑双11,也是在不断实践基于这些理念的思考。
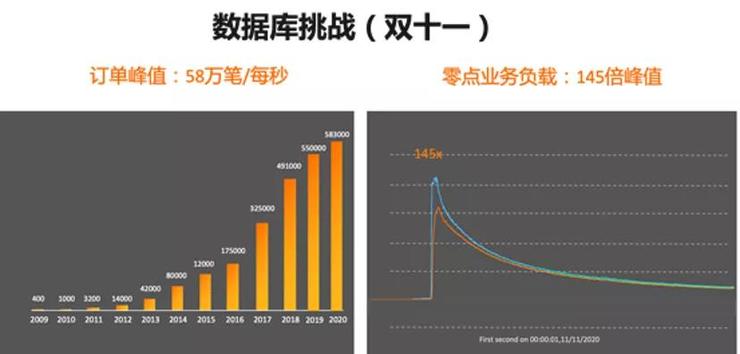
以双11为例,第一张图是历年双11的零点交易峰值的曲线,最新的2020年双11的零点峰值是58万笔/秒。每一笔交易还会有一个拆单的动作,到数据库系统就是每秒几百万TPS。
第二张图是系统零点负载的瞬间变化曲线,一秒钟时间内系统负载瞬间爆发了145倍。如果不是利用云原生的技术,简单依赖传统技术根本无法满足这种高并发、弹性、高可用的要求。
几个重要趋势
从架构的角度来看,数据库系统的变化如下图所示:
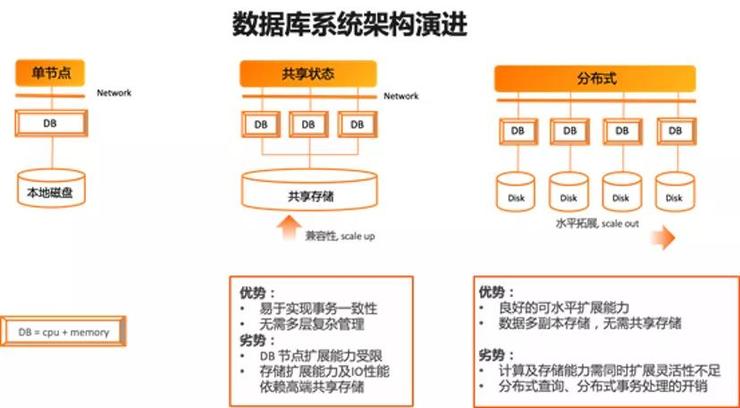
左边是传统的冯诺依曼架构,右边是分布式架构,中间是云原生的架构,背后大量利用了分布式技术。这种资源池化带来的弹性、高可用的能力显而易见。
这是今天三种不同的架构,有以下几个趋势:
大数据和数据库一体化
云原生和分布式技术结合
智能化
多模数据处理
软硬件一体化:例如,利用高速网络等来提升数据处理系统的性能和效率
安全可信:例如,如何确保数据不可更改
结合阿里云数据库的核心技术,把以上背景、趋势实例化:
1 云原生关系型数据库PolarDB
每个数据块分成三个物理节点,不用关心分布式带来的挑战。比如分库分表、分布式的查询,对应用完全透明,读写一份数据,做到了分布式技术透明化、集中式部署。
PolarDB的存储与计算架构分离,能在分钟级别部署一个新的计算节点,或者扩容存储节点。同时,在性能上做了大量的优化,非常好地兼容了生态,比如100%兼容MySQL和PostgreSQL,高度兼容Oracle。
其性价比在商业数据库中有非常大的竞争优势,在实际的客户案例里,利用PolarDB Oracle兼容版替换现有的Oracle,在性能一样的前提下,整体成本不到原来的三分之一。
除了云原生的架构,也有分布式架构版的PolarDB-X。在每个分区里面做这种三节点的架构,同时,三节点利用协议做数据的一致性保障,而且三节点可以做到同城跨AZ部署。
2 一体化设计是下一代数据分析系统的核心理念
下一代的系统是将云原生技术和分布式技术合二为一:上面是分布式,而下面是云原生的方式实现。每个分区都可以享受云原生带来弹性、高可用的能力,同时,上面有分布式带来的水平拓展的能力,解决高并发可能带来的瓶颈问题。
3 云原生数据仓库AnalyticDB
云原生的数据仓库本质上也是云原生的架构,存储池化、计算池化、存储计算分离,同时实现海量存储弹性、轻量化部署。
利用这些技术实现数据处理和计算分析的离在线一体化、数据库与大数据一体化。如同现实生活中的仓库,所有物品要分门别类放好。所以,数据仓库比较适合已经范式化的数据格式、业务类型比较固定的场景,性价比非常高。
这是我们在云原生数仓方面做的一些工作,我们也利用这套架构研发了AnalyticDB(ADB),支持了淘宝天猫对实时交易数据进行在线交互式分析和计算的需求,同时支持复杂的离线ETL与在线分析的融合。
4 数据湖
数据湖,“湖底”的数据参差不齐,“湖面”却是平的。不同于数据仓库,数据湖的存储是多源异构的,只需要有一个统一的界面对这些数据进行分析、处理。
我们打造了一个云原生的Serverless数据湖解决方案DLA——基于对象存储,对多源异构的数据存储进行统一的计算和分析,利用云原生的Serverless技术,可以用非常低的成本实现弹性高可用的能力,并且满足安全性的要求。
5 多模、智能化和安全可信
在管控这一层实现异常检测、安全诊断,通过K8S这套编排技术,把多源异构的资源管理起来,打造智能化的运维管控平台。
我们做了全加密的数据库,数据进入内核以后不需要解密。利用安全硬件技术做了全加密的流程和保护,实现了不解密也能进行数据加工和处理。
数据业务的多样化带来了除了结构化数据之外的多模数据,例如文本、时序、图片、图数据等非结构化数据。针对多模数据,我们设计研发了基于云原生架构的多模数据库Lindorm以及云原生内存数据库Tair来支持多模数据处理。
最后是生态工具,从传输、备份到管理。传输采用DTS,做端到端数据的同步,用DBS数据备份做多云多端的逻辑备份、物理备份,DMS做企业级的开发建模流程,ADAM做针对基于传统数据库和数据仓库开发的应用评估和迁移。
今年疫情期间,各行各业有一个非常大的变化——传统的离线业务和在线业务在快速融合,线上线下的边界越来越模糊。这带来的挑战是,业务波峰波谷的变化越来越剧烈。这是疫情带来的必然变化,数字化的转型也是一个必然发生的事实。
这种背景下,阿里云原生数据库PolarDB、云原生数据仓库AnalyticDB,不仅支持了双11,更在疫情期间服务了各行各业,尤其是在线教育、游戏等传统的线上线下边界越来越模糊的行业。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!