
大规模标注的数据集的出现是深度学习在计算机视觉领域取得巨大成功的关键因素之一。然而监督式学习过于依赖大规模标注数据集,数据集的收集和人工标注需耗费大量的人力成本。自监督模型解决了这一难题,从大规模未标记数据中学习图像特征,无需使用任何人工标注数据。
每个深度学习实践者都认同的一件事是:深度学习模型数据低效。
数据低效的深度学习模型
让我们首先考虑计算机视觉中的主流分类任务。以 ImageNet 数据库为例,它包含 1000 个不同类别的130 万张图像,对于每一个图像中都有一个人工标注的标签。
ImageNet 无疑是现在深度学习复兴的基石之一。 ImageNet 起源于 2012 年 Krizhevsky 等人所著的论文《Imagenet Classification with Deep Convolutional Neural Networks》。
在这篇文章中, 卷积网络模型首次大幅度超越了当时最先进的模型。它是在所有的对比模型中唯一一个基于卷积神经网络的解决方案。此后,卷积神经网络变得无处不在。
在深度学习之前,研究人员一直认为 ImageNet 挑战非常困难,其根本原因是 ImageNet 数据集突出的变化性。即便只是找到能覆盖 ImageNet 中各种犬类的手工特征就已经很不容易。
然而,通过深度学习,我们很快意识到大量的数据导致了 ImageNet 如此困难,同时实际上也是使深度学习如此有效的秘诀。
虽然如此,通过多年的深度学习研究,我们大家都知道了大型数据库用于训练精确模型的必要性已成为一个很重要的问题。并且需要低效的人工标注数据成为一个更大的问题。
而且在当前的深度学习应用中,数据的问题无处不在。以 DeepMind 的 AlphaStar 模型为例。
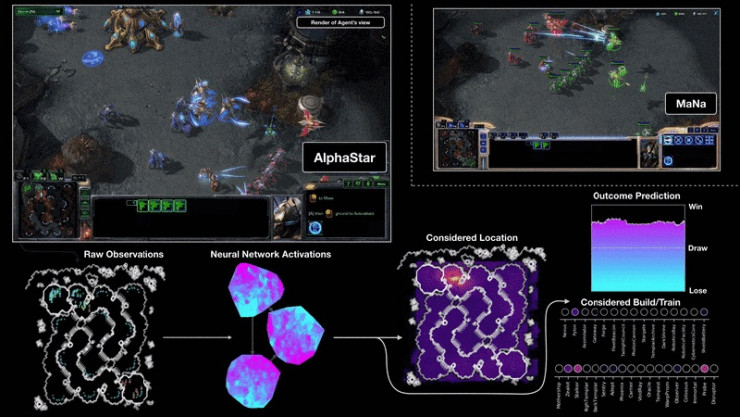

图1 图片来自:《AlphaStar : Mastering the Real-Time Strategy Game StarCraft II》
AlphaStar 深度学习系统使用监督学习和强化学习来操作《星际争霸2》。在训练期间,AlphaStar 仅从游戏终端上观看游戏画面。DeepMind 研究人员使用可并行训练大量智能体的分布式策略训练模型。每个智能体都至少观看过 200 年的实时《星际争霸》录像(不间断)。 通过像职业选手一样的训练,AlphaStar 取得了在官方游戏服务器中的排名超过了99.8%的活跃玩家的这一巨大成功。
虽然其中使用了各种通用性的技术来训练系统,但成功构建 AlphaStar(或任何其他 RL 智能体)的真正关键是使用了大量数据。实际上最佳的强化学习算法有必要进行大量试验才能达到人类水平,这与我们人类的学习方式正好相反。
结果,强化学习在具有大量可用数据的受限且定义明确的场景上取得了巨大成功。相关阅读可以查看 DeepMind 《Rainbow: Combining Improvements in Deep Reinforcement Learning》这篇论文:
如果让最好的 RL 方法玩某个 Atari 游戏,它需要一共玩近100个小时(1080万帧),才能达到和专业人类玩家相同的表现水平。尽管时长最近有所改进,但100小时似乎仍然太多。
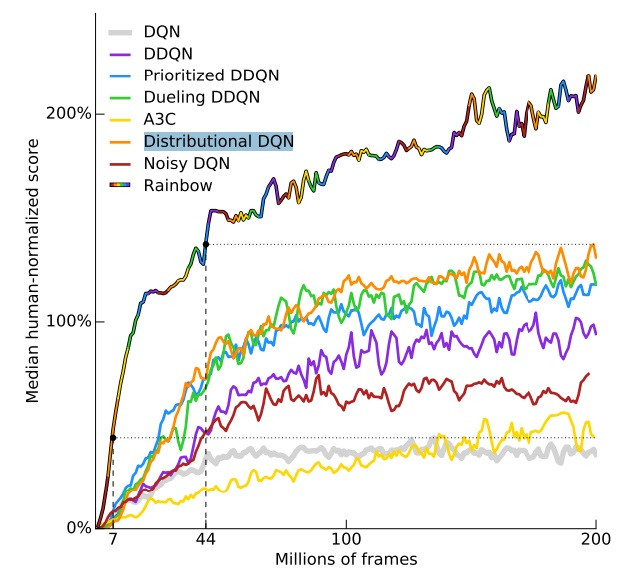
图2 图片来自:《 Rainbow: Combining Improvements in Deep Reinforcement Learning》
有关 AlphaStar 的更多信息,可以查看这篇文章:
虽然我可以给大家再举几个例子,但我想这2句话足以说明我的意思:
目前深度学习基于大规模数据,当满足所需环境和约束条件时,这些系统就会产出给人惊喜的结果。但在一些特殊情况下,它们也会完全失效。
让我们回到 ImageNet 分类问题: ImageNet 数据库的人类识别错误率约为5.1%,而目前最先进的深度学习 top-5 准确性约为1.8%。
因此我们大家可以完美地证明:深度学习在 ImageNet 这项任务上已经比人类做的更好。但是真的是这样吗?
如果是这样的话,我们怎么解释这样一些问题呢?
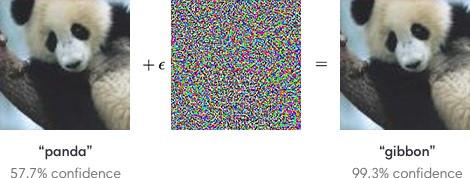
图3 图片来自:《 Attacking Machine Learning with Adversarial Examples》
我们大家可以将这些在互联网上非常流行的对抗样本(adversarial examples)看作是设计用于误导机器学习模型的优化任务。相关阅读可以查看下面这篇文章:
文章地址:https://openai.com/blog/adversarial-example-research/
这个想法很简单:
我们如何让分类器将以前归类为“熊猫”的图像归类为“长臂猿”?
我们大家可以简单地认为被精心设计的输入样本导致了 ML 模型分类错误。

图4:图片来自:《One Pixel Attack for Fooling Deep Neural Networks》
正如我们所见,优化效果好到我们(用肉眼)无法察觉到真实图像(左)和对抗图像(右)之间的差异。实际上,造成分类错误的噪声不是任何类型的已知信号。相反它是经过精心设计用于发现模型中的隐藏误差。并且最近的研究表明:在某些情况我们只需要改变1个像素,就可以 成功误导最好的深度学习分类器,详细讨论可以查看这篇论文:
在这一点上,我们大家可以看到问题开始相互叠加。 我们不仅需要大量样本来学习新任务,还需要确保我们的模型学习正确的表征。
油管视频:https://www.youtube.com/watch?v=piYnd_wYlT8
我们看到深度学习系统失败时产生了一个有趣的讨论:为什么 我们人类不会轻易被对抗样本误导呢?
建立和利用先验知识
有的人说当我们需要掌握一项新任务时,我们实际上并没有从头开始学习它。 相反,我们使用了我们一生中积累的许多先验知识。

图6 牛顿发现万有引力定律
我们了解重力及其含义,知道如果让炮弹和羽毛从同一起点落下,由于两个物体的空气阻力不同,炮弹将先到达地面;知道物体不能漂浮在空中;了解有关世界运作方式的常识。 我们知道如果我们自己的父亲有孩子,他或她将是自己的兄弟姐妹;知道如果我们读了一篇文章说某人出生于 1900 年代,那么他/她可能不再活着,因为我们(通过观察世界)知道人们的寿命通常不会超过 120 岁。
我们了解事件之间的因果关系。最神奇的是我们实际上很早就学会了许多高级概念。实际上,我们仅用6~7个月就学会了重力和惯性等概念,而在这个时期我们与世界的互动几乎为0!
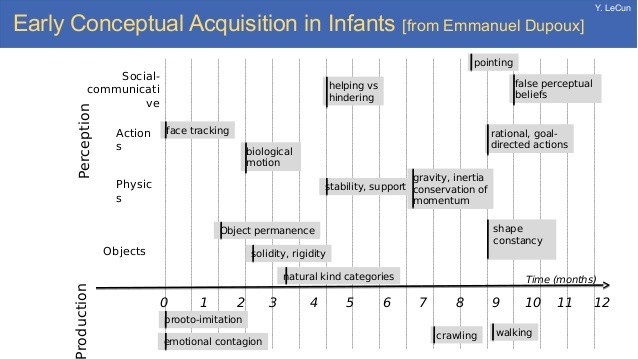
图7 图片来源:《Early Conceptual Acquisition in Infants [from Emmanuel Dupoux].》, Yann LeCun讲义
从这种意义上讲,有人可能会说将算法性能与人类能力进行比较是“不公平的”-。
Yann LeCun 在关于自监督学习的研究中,认为至少有3种获取知识的方法。
(1)通过观察
(2)通过监督(大部分来自家长和老师)
(3)通过强化反馈

图8 :人类通过生活获得不同知识的来源。通过观察/互动、监督和反馈来学习
但是如果以婴儿为例,那么这个年龄与外界的互动几乎没有。 尽管如此,婴儿还是成功建立了物理世界的直觉模型。 因此像重力这样的高级知识只能通过纯粹的观察来学习——至少,我还没有看到任何父母教一个6个月大的婴儿物理。
直到我们长大一些掌握语言并开始上学时,监督和互动(带有反馈)才变得更加重要。 但更重要的是,当我们处于生命的这些阶段时,我们已经建立了一个鲁棒性的模型世界。 这可能是人类比当前机器更高效处理数据的主要原因之一。
正如 LeCun 所说,强化学习就像蛋糕上的樱桃。 监督学习是锦上添花,而自监督学习才是蛋糕!
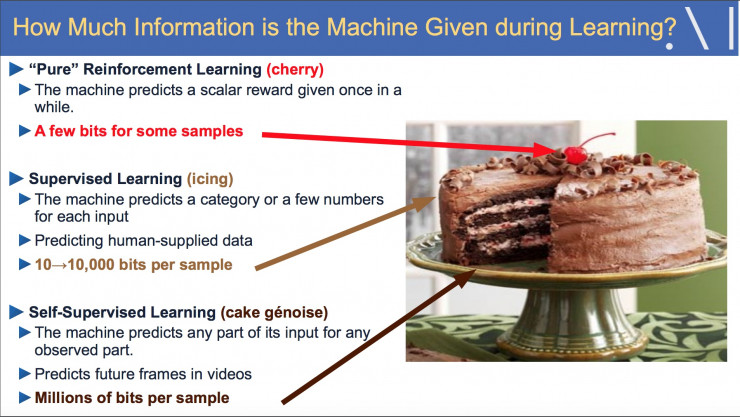
图9 图片来源:Yann LeCun(https://drive.google.com/drive/folders/0BxKBnD5y2M8NUXhZaXBCNXE4QlE)
自监督学习
自监督学习系统学会通过输入的其他部分预测输入的一部分。
—— LeCun
自监督学习源于无监督学习, 解决从未标记的数据中学习语义特征的问题。本文中我们最关心的是在计算机视觉领域的自我监督。
通常的方法是通过设计一个“名义任务”将无监督的问题转换为有监督的任务。 通常,名义任务不会有什么新的产出,它的目的是使网络学习如何从数据中捕获有用的特征。
名义任务与常见的监督问题有相似之处。
我们知道监督训练需要标注。转而变成通常需要人工标注者的不断努力。 但在许多情况下,标注非常昂贵或无法获得。 我们也知道学习模型天生需要数据,这导致大规模的标注数据集已成为学习模型进一步发展的主要壁垒之一。
同样,自监督学习也需要标注来训练名义任务。然而与名义任务的关键不同在于:用于名义任务的标注(伪标注)的特征是不同的。
实际上对于自监督训练,伪标签仅来自数据特征本身。
换句话说伪数据不需要人工标注。 确实,自我学习和监督学习之间的主要区别在于标注的来源。
(1)如果标注来自标注者(像大多数数据集一样),则这是一项监督任务。
(2)如果标注是从数据中获取,那么在这种情况下我们可以自动生成它们,则这是一项自监督学习。
最近的研究提出了许多名义任务。最常见的有:
(1)图片旋转(Rotation)
(2)图像拼接(Jigsaw puzzle )
(3)图像着色(Image Colorization)
(4)图像修复(Image inpainting)
(5)用 GANs 生成图像/视频(Image/Video Generation using GANs)
如果想要了解更多关于每个 pretext 任务的介绍,可以查看《Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey》这篇论文:
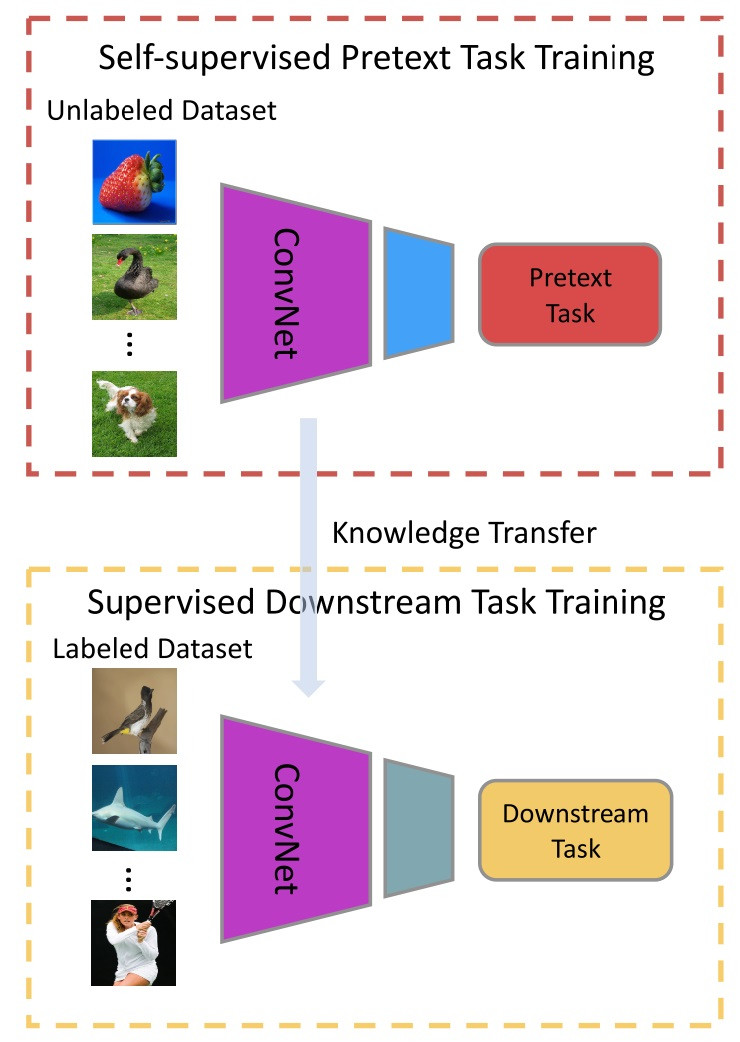
图10:图片来源:《Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey》
在自监督的训练期间,我们挑战网络以学习名义任务。同样,根据数据本身自动生成伪标签用来训练目标。 训练结束后,我们通常将学习到的视觉特征作为知识转译给下游任务(downstream task)。
通常,下游任务可以是任何监督问题。 目的是用自监督特征改善下游任务的性能。
通常下游任务的最大问题是数据有限和过度拟合。这里,我们能够正常的看到基于大型标注数据库(如 ImageNet )预训练卷积神经网络的普通迁移学习的相似性。但有一个关键的优势:通过自监督训练,我们大家可以在难以置信的大型数据库上对模型进行预训练而无需担心人为标签。
此外, 名义任务和普通分类任务之间有一个细微差别。在纯分类任务中,网络学习表征是为了分离特征空间中的类。在自监督学习中,名义任务通常会促使网络学习更多的通用概念。
以图像着色这一名义任务为例:为了擅长图像着色,网络必须学习通用用途的特征,这些特征解释了数据集中对象的特征,包括物体的形状、一般纹理、怕光、阴影、遮挡等。
总之,通过解决名义任务,网络将学习容易转译给学习新问题的语义特征。换句话说:我们的目标是在进行监督之前从未标注的数据中学习有用的表征。
结论
自监督学习让我们能够没有大规模标注数据也能获得优质的表征,反而我们大家可以使用大量的未标注数据并且优化预定义的 pretext 任务。然后我们大家可以使用这些特性来学习缺乏数据的新任务。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!