


今年1月份,苏黎世联邦理工学院的Stefan Feuerriegelc教授在 《Communications of the ACM》期刊上刊文“Artificial Intelligence Across Company Borders”,在文中教授指出了人工智能(AI)产业落地过程中常见挑战:如何开展跨公司合作?
教授表示:通过数据共享构造大规模的跨公司数据集是一种方式,但有数据保密和隐私泄漏风险,且受隐私相关法律的限制。
而保护隐私的分布式机器学习框架—联邦学习,能让数据不出本地,解决上述痛点。
但传统的联邦学习目前并不能提供规范的隐私保护证明,此外,其场景容易受到因果攻击。
因此,教授指出,结合联邦学习和领域自适应,能够更大限度让合作公司从协作AI模型中受益,同时将原始训练数据保持在本地。
以下是Stefan Feuerriegelc教授对领域自适应联邦学习的介绍,由星云Clustar高级算法工程师张泷玲、杨柳翻译整理。
近年来,以AI为核心的数字技术正在驱动经济社会发展。数据显示,2030年,AI将使全球工业部门的经济活动增加13万亿美元。
然而,由于无法获取或有效利用跨国公司数据,使得这一技术的潜力在很大程度上仍未得到完全开发。AI收益于大量具有代表性的数据(representative data),这些数据通常需要来自于多家公司,特别是在实际工业场景中,面对少见的意外事件或者关键系统状态,想使AI模型取得良好的性能是极具挑战性的。
实现跨公司AI技术的一种直接方式是通过数据共享构造大规模的跨公司数据集。但出于数据保密和隐私泄漏风险的考虑,大多数公司都不愿意直接共享数据。并且在大多数情况下,共享数据受到隐私相关法律的限制。因此,具有领域自适应的联邦学习是解决跨公司AI问题的关键,一方面,联邦学习能够在不泄漏各公司数据隐私的前提下,实现模型训练和推理;另一方面,领域自适应允许各公司按照自己特定的应用场景和条件,对联邦模型做定制。
跨公司AI主要存在两个障碍:
首先是跨公司的数据隐私性。因为直接共享原始数据可能会给竞争对手公司暴露有关自身公司的运营流程或知识产权专有信息等。这一障碍常常出现在公司寻求与供应商、客户或竞争对手公司想进行AI合作时。
例如,制造工厂的数据可以揭示参数设置、产品成分、产率、产量、路线和机器正常运行时间。如果此类数据被泄漏,它可能会被客户在公司谈判中滥用或进而帮助竞争对手提高生产力和改进产品。同时除了知识产权之外,一些深层的限制因素也会降低公司之间共享数据的意愿或倾向,例如公司间的信任程度、道德约束、保护公司用户隐私权的法律法规以及网络安全风险。因此我们需要一个保护数据隐私的解决方案,即在不暴露各公司的源数据前提下进行模型推断。
其次是跨公司间的合作需要考虑到领域偏移(domain shifts)的影响。领域偏移是指为不同公司使用不同配置机器或操作系统采集得到的数据分布不匹配。例如,来自一家公司采集到的机器数据可能不能作为另一家公司的代表性数据由于不同机器数据采集条件不一样。领域偏移给潜在的推论带来了障碍:在一家公司的数据上训练得到的模型可能表现不佳当部署到另一家数据分布明显不同的公司时。
AI研究的最新进展有望突破这两个难题。联邦学习是一种保护隐私的分布式机器学习框架,旨在让多个边缘设备或服务器在不共享数据样本的前提下,通过共享本地模型参数(梯度或权重),共同进行机器学习的模型训练。
跨公司的纵向联邦学习可以从所有参与公司(例如,来自多个工厂、机车车辆厂或发电厂)的共同数据(joint data)中进行,通过共享各公司的模型参数(梯度或权重),共同进行机器学习的模型训练。
为了实现这一点,跨公司的纵向联邦学习通过将模型训练与对原始训练数据的访问解耦:各公司通过加密技术在不暴露各自的原始数据前提下对齐共同数据。通过利用各参与方本地数据进行模型训练,并将中间结果返回给协调方。协调方汇总各参与方的中间结果,构建协作模型,以整体提升模型性能和效果。在此过程中,没有公司有权直接访问到其他公司的原始训练数据。
在跨公司AI的背景下,针对跨公司间的合作的领域偏移问题,由于不同公司的数据分布通常只是较少重叠,即目标域和源域域有一定差异,我们引入领域自适应理论,目标是学习到的不变量,即不受合作公司的特定操作条件限制,从而减轻跨公司之间由于领域偏移产生的模型表现不佳的影响。
具体主要通过学习源域和目标域的公共的特征表示,在公共特征空间,源域和目标域的分布要尽可能相同,以便边缘分布在特征空间中对齐。
跨公司AI合作可以通过使用联邦学习来解决直接数据共享的隐私保护的障碍和通过域适应解决领域偏移的障碍。这种组合通常被称为联邦迁移学习。
在工业生态系统中通常会遇到两种类型的迁移学习方法,通常将故障视为标签但由于故障通常在系统中不常见,因此是不均衡。通常出现标签在源域中出现但在目标域中没有(称为无监督域适应);标签在源域和目标域中都没有(称为无监督迁移学习)
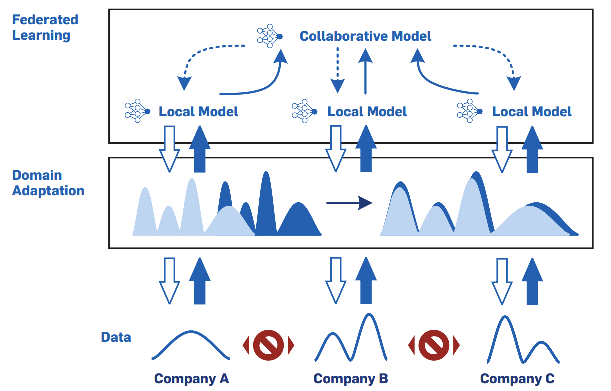
公司可以结合联邦学习和领域自适应,在工业生态系统中实现协同AI。一旦部署,它允许合作公司从协作AI模型中受益,同时将原始训练数据保持在本地。同时,协作模型的训练方式可以很好地概括每家公司的数据。并且任何时候都不会共享跨公司的边界专有数据,只有模型的中间结果(例如梯度)在公司之间共享,此外,协作模型通过学习不变量来代表公司之间的异质性程度。例如,不受公司特定运营条件的影响,每个参与的利益相关公司能够通过其他合作公司的经验来扩展自己的运营经验。
对于工业生态系统,传统的联邦学习中的训练过程通常由中央服务器协调各参与者,但一方面,由于中央服务器的瓶颈特性,可能会造成潜在的漏洞。另一方面,这种集中式架构目前也仅仅应用到双边合作这种普遍的场景。
去中心化的方式实施跨公司的AI合作的是十分具有潜力和巨大价值的,因此引入了去中心化的学习设置。在去中心化联邦学习中,与中央服务器的通信被替换为对等通信,这对于由应用程序或操作条件的相似性和特定用例和操作条件的演变动态形成子网络内的跨公司协作。同时为了完成传统的中央服务器的任务,分布式账本技术的使用在此处的应用也是可行的。最后,这里讨论的方法需要根据跨企业的实践经验中进行选择,以便公司选择是否更倾向集中式或去中心化方法的联邦学习。
虽然联邦学习能够提供较为显着的隐私保护策略,并鼓励跨公司边界的协作,但迄今为止,传统的联邦学习目前并不能提供规范的隐私保护证明,半诚实参与方是可能从梯度更新和之前的模型参数中推断出一些信息。此外,传统的联邦学习场景容易受到因果攻击,即训练好的模型可能会因参与方错误的模型更新而遭到破坏。对于公司而言,避免此类攻击的实施是非常重要的,这里有一种解决方案是提出使用额外的隐私保护技术,例如差分隐私或密码学手段等等。
结合联邦学习和领域自适应
对于从业者而言,将跨公司的AI合作引入工业生态系统将需要指导和实施过程的一系列设计原则。例如,如果两家公司的应用程序内的数据分布没有明显的领域偏移,则可以直接应用联邦学习而不需要与领域自适应相结合等。
此外,跨公司AI合作的实施必须满足实践的进一步需求,这可能需要更多扩展,例如持续学习和数据异质性的解决方案。例如,对于高度异构的系统,必须选择足够鲁棒的模型实现,从而实现可迁移性(例如,跨不同的产品型号、不同的传感器组组合或不同的制造商)。同时随着时间的推移,行业成熟后也应该做好引导工作来制定一系列的标准规范跨公司合作进一步释放AI的力量。
将联邦学习与领域适应相结合,可以在跨公司合作中释放AI的力量。这种跨公司的AI合作可以扩展到传统的供应链或领域之外。例如,创建合作评级组织的大型生态系统。虽然这一愿景可能会在不久的将来实现,但公司可以开始在值得信赖的合作伙伴中学习和使用这项新技术。同时仍然需要开发公平指标去分配模型,这是跨公司AI合作的微观经济含义。行业经理应确定可以帮助更全面优化其绩效的数据合作伙伴,做到与系统思维保持一致。
跨公司的 AI 还可以激发新的商业模式,例如通过AI即提供服务或由第三方公司支持数据。特别是中小型公司将从利用其他公司的数据资源中受益。在这方面,服务系统工程可以帮助制定基于跨公司AI设计和开发服务系统网络的系统原则。朝着这个方向迈出的第一步是系统地理解利益相关者和资源之间的价值共创模式。
跨公司利用AI合作将受益于正在进行的研究。目前研究也在做出新的尝试来推进联邦学习,提高其可扩展性、鲁棒性和有效性,同时加强的隐私保护和提高模型性能方面。对这些具有领域自适应能力的联邦学习可以促进跨公司边界使用AI合作呈指数级增长。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!