想象一下:
在未来的某一天,你,一个996的「社畜」,或「上班狗」,辛苦一天回到家,瘫倒在沙发上。当你抬头一看,你的机器人朋友正在厨房为你做晚饭——它的双手敏捷灵活,在油盐酱醋与锅碗瓢盆之间,一顿优雅操作,不久便有阵阵香气扑鼻而来。它把晚餐端到餐桌上,对你微微一笑:「开饭啦!」然后转身拿起你换下的衣物走向洗衣机……
这不是一篇小学生的科幻小作文,而是许华哲作为一位机器人学研究者关于未来机器人的想象:「我希望能有一个真正通用的机器人,它什么都能做,或者至少能为人类完成家居场景里的大部分任务。」
最近,他在走向通用机器人的这条路上又前进了一步:想要机器人为我们包饺子、卷寿司?先让机器人从学习捏橡皮泥开始吧!
不久前,许华哲团队的一篇论文被机器人学顶会RSS接收。这项工作提出了一种机器人系统,叫「RoboCraft」,将传感器数据转换为粒子,使用图神经网络学习基于粒子的动力学模型,对机器人进行行为控制,实现了机器人操作柔性物体的目标。
论文地址:https://arxiv.org/pdf/2205.02909.pdf
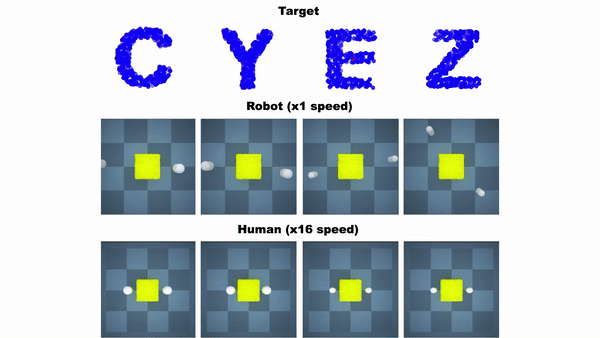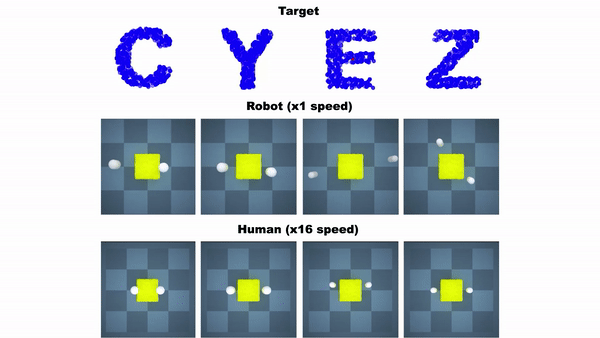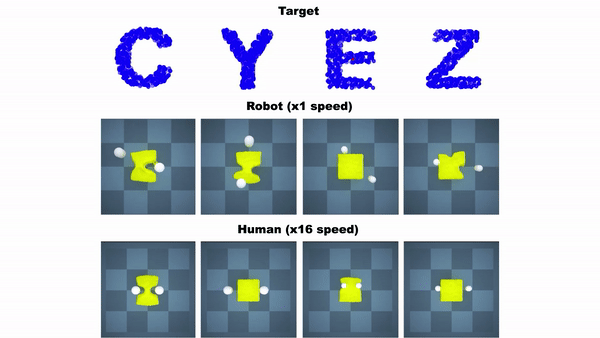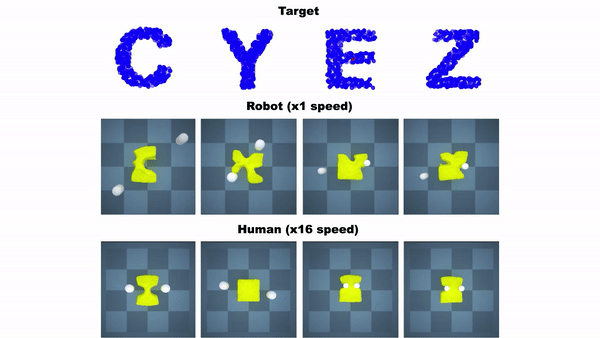
这个RoboCraft框架有三个组件,一个是基于粒子的场景对模块进行表示,从而「看到」橡皮泥;二是基于GNN模型,模拟对象的动力学;三是一个基于梯度和采样的模型预测控制模块,学习如何对一块橡皮泥进行塑形。
图注:机器人将橡皮泥捏成字母A和X的形状
实验表明,无论是在模拟器、还是在真实世界中,这个基于模型的规划框架在测试任务上的表现都可以与人类相当,甚至比人类做得更好。
图注:RoboCraft与人类在捏橡皮泥任务上的对比。在模拟器中,人用鼠标和键盘控制机械臂。

图注:RoboCraft与人类在捏橡皮泥任务上的对比。在真实世界中,人直接操纵机械臂。
当然,这只是许华哲征服机器人星辰大海之路上的一片碎小星光。
许华哲本科毕业于清华大学电子工程系,后在加州大学伯克利分校攻读博士,目前在斯坦福大学从事博士后研究,指导教师为计算机视觉领域的知名新秀吴佳俊。他对AI科技评论表示,今年秋季,他将回到母校清华,成为清华大学交叉信息研究院(也就是「姚班」)的一名教师。
关于机器人的美好愿景虽然由来已久,但许华哲并非一开始就专攻机器人学。从本科到博士后阶段,一路上,他的科研方向经历了有迹可循的转变:本科大三去多伦多大学交换时第一次接触计算机视觉,到伯克利读博期间结合视觉做自动驾驶,最终转向将强化学习应用于机器人学。
每一次转变,许华哲都越来越接近他所追求的通用人工智能和通用机器人。
2012年,许华哲从东北师大附中毕业,通过物理竞赛保送到清华大学电子工程系,就读电子信息科学与技术专业。
图注:本科入学前的许华哲
当时,清华大学的物理系、电子系和建筑系是物理竞赛保送生的三大热门去向,许华哲基于自己的学科兴趣选择了电子系。他解释说:「我当时的想法比较稚嫩,就觉得电子系离新一代的IT技术很近。」而且,在高中时期,他就了解到清华对电子系开设了很多偏重物理的课程,其他相关院系(如信息科学技术学院)则没有这样的课程设置。因此,对于擅长物理的许华哲来说,电子系无疑是最好的选择。
从东北的长春来到「帝都」北京,虽然未来的方向尚不明朗,但许华哲内心隐隐感到,在清华这样一个广阔的天地,他将大有作为。
「其实我并没有想到我一定要做什么,或者我一定要解决一个什么样的问题,但我有一个大致明确的主线,就是希望以后可以读一个博士。」许华哲这样回忆他初入清华时的心态。
这样的期许也来源于周围清华人对他的感染。清华从来不乏在各个领域发光发热的个体:天资聪颖的骄子,勤奋努力的追赶者,玩转社团与实践的达人……在这样一种包容参差、鼓励多样的环境里,许华哲选择了一种「玩得开心」但也始终向前的道路:加入艺术团键盘队继续发展对音乐的爱好,与学生会的伙伴一起策划活动,跟同学一起熬夜赶作业,和好朋友一起去玩耍吃烤串,等等。
而对于一位被录取到顶尖学府的保送生,优秀必然已经成为一种习惯。所以,看似松弛的状态,也并没有耽误许华哲在学习上穷追猛打、将课程绩点排到年级前2%。虽然不及他口中那位期末期间边打游戏边复习、最终还能考到年级第一的室友,但他自己在学业上也并不逊色太多。
图注:许华哲在清华
至于科研,许华哲回忆,在清华时,他只是在通信研究所的实验室跟随老师做过一段时间的科研。他坦言,由于课业压力较大,加上课外活动所占去的精力,「科研自然就做不动了」。直到大三上学期,许华哲去多伦多大学交换,才开始科研上的更多探索。在那里,他第一次接触到计算机视觉,并进一步体会到做科研的乐趣。

2014年秋,许华哲赴加拿大多伦多大学进行一个学期的交换与学习生活。在那里,他修读了电子与计算机工程系的四门课程:计算机视觉、数字信号处理、随机过程和操作系统,其中,「计算机视觉」这门课的描述尤其吸引他,就这样,他开始了与计算机视觉的初遇。而在此之前,许华哲连「计算机视觉」是什么都不知道。
为什么会被计算机视觉这个方向所吸引?这与许华哲自身的个性和科研思维倾向或许是分不开的。在他看来,相比于其他研究方向,计算机视觉研究所产出的结果是很直观的,比如,用视觉可以将一幢楼的窗户清晰地分割、检测出来,这其中的实现过程和结果呈现都是直接的。这让直觉型思维的许华哲觉得是一种「好玩的科研」。
于是,许华哲兴致勃勃地向讲授计算机视觉这门课的 Sanja Fidler 教授表明自己想跟她做科研。Sanja Fidler 很认可他的课程表现,欣然同意。
尽管当时他只是一个本科生,但许华哲能够感受到,Sanja Fidler 完全把他看作是一位「科研工作者」,双方都很认真、严肃地谈论研究工作。在一个做了半年的项目中,许华哲运用深度学习让 AI 模型学习人类对于汽车类型(如外形、颜色等)的偏好,从而完成模型对汽车外观打分的任务。这个项目成了他在人工智能科研路上迈出的第一步。
交换结束后,许华哲回到了清华。这段短暂的科研经历,虽然与机器人研究并无直接关联,却对他之后选择科研方向产生了直接的影响。与在计算机视觉方向上寻求直观性类似,许华哲后来又在自动驾驶、机器人学方向上看到了更强的直观性,从而逐渐将兴趣转移到了可控制的、运动的智能体上。
2016年,许华哲赴美国加州大学伯克利分校读博,开始了走向机器人学的科研探索之路。
自动驾驶:自己做自己的导师
在申请加州大学伯克利分校的博士之前,许华哲先去那里做了三个多月的暑期科研实习,他当时实习的组正是后来他读博所在的组。
 图注:许华哲在伯克利做暑期科研实习
大三结束那年的暑假,在 Sanja Fidler 的举荐下,许华哲去了伯克利实习。期间,他与在伯克利读博的胡戎航师兄、Trevor Darrell教授等人合作,完成了一篇视觉-语言(vision-language)方向的论文(“Natural Language Object Retrieval”)。这项工作旨在解决自然语言对象检索的任务,通过基于对象的自然语言查询来定位一个目标对象。论文后来被 CVPR 2016 录取为 Oral Paper。
图注:许华哲在伯克利做暑期科研实习
大三结束那年的暑假,在 Sanja Fidler 的举荐下,许华哲去了伯克利实习。期间,他与在伯克利读博的胡戎航师兄、Trevor Darrell教授等人合作,完成了一篇视觉-语言(vision-language)方向的论文(“Natural Language Object Retrieval”)。这项工作旨在解决自然语言对象检索的任务,通过基于对象的自然语言查询来定位一个目标对象。论文后来被 CVPR 2016 录取为 Oral Paper。

论文地址:https://arxiv.org/pdf/1511.04164.pdf
暑期实习结束后,许华哲开始着手申请博士项目。他希望能留在伯克利继续读博,但对于Darrell教授是否满意自己在实习期间的表现,他心里是没有底的。每年去伯克利进行暑期实习的学生都不胜枚举,而博士申请存在竞争和不确定性,所以,除了伯克利,许华哲也申请了其他几所学校。不过,最终还是如人所愿,他收到了伯克利的录取通知,便决定继续留在 Darrell 的组里攻读博士。
谈起自己的博士导师,许华哲认为自己很幸运:「我的导师在指导学生方面非常宽松,对我们的研究方向不加任何限制。他觉得,只要我做的事情是自己真正感兴趣的,我就可以去做,他会全力支持我。」
Darrell 非常鼓励许华哲去自由地探索。在他对科研方向感到迷茫的时候,Darrell 会对他说:「你可以都试试。」或者是,「你觉得什么研究做出来会很好玩、很酷,你就去做什么研究,不用去想什么研究能给你带来更多的收益。」
导师的这种指导风格促使他在博士初期选择了「离经叛道」的科研方向。入学后,他做的第一个项目是自动驾驶方向,而这个方向无论是对于许华哲还是 Trevor Darrell 来说,都是一个新领域。Darrell 主要研究计算机视觉,当时组里在做的课题主要是域迁移与视觉-语言(vision-language)。原本,许华哲可以跟随导师专攻这两个方向,但导师建议他去尝试自动驾驶。
2016年,自动驾驶如日中天。产业界摩拳擦掌,纷纷入局。在美国,通用汽车以10亿美元的价格收购了Cruise;在德国,Uber与戴姆勒汽车集团开始在自动驾驶领域展开合作;中国的滴滴也开始组建自动驾驶公司。在学术界,各个实验室也开始积极投入研究,想要在自动驾驶领域中开拓和占领一席之地。
在这样的背景下,此前对自动驾驶并没有予以太多关注的 Darrell,也产生了新开一个自动驾驶研究方向的想法,而这个「开新坑」的任务落到了许华哲身上。
许华哲也不推脱,话不多说,就开始了自动驾驶方向的探索。由于 Darrell 在该领域没有太多可传授的经验,所以在大多数时候,许华哲是自己给自己当「导师」,而 Darrell 则从视觉的角度给他提供了很多技术上的帮助。
许华哲的尝试很快得到了回报。当时还是一年级博士生的他,与博士导师、师兄高阳和博士后研究员Fisher Yu等人合作,完成了一个自动驾驶项目,并以第一作者的身份发表了论文(“End-to-end Learning of Driving Models from Large-scale Video Datasets”),被录取为2017 CVPR Oral 论文。

论文地址:https://arxiv.org/pdf/1612.01079.pdf
这项工作探索了如何从视觉的角度通过深度学习来实现自动驾驶。以往的深度学习方法受到数据量的限制,局限于固定场景和模拟环境。为了解决这个问题,许华哲与团队介绍了一个不依赖执行机构的自动驾驶通用模型,采用端到端的训练方式,从大规模众包视频数据中学习,实现了更好的泛化性能。而且,他们还公布了当时市面上时长最长、场景最丰富的自动驾驶数据集BDDV(Berkeley DeepDrive Video dataset)。
 图注:博一年级的许华哲在CVPR上作报告
将计算机视觉与自动驾驶相结合的研究,让许华哲离机器人学更近了一步。相比于纯静态的视觉研究,许华哲更倾心于动态的智能体,比如可以无人驾驶的智能汽车和运动的机器人。
图注:博一年级的许华哲在CVPR上作报告
将计算机视觉与自动驾驶相结合的研究,让许华哲离机器人学更近了一步。相比于纯静态的视觉研究,许华哲更倾心于动态的智能体,比如可以无人驾驶的智能汽车和运动的机器人。
从强化学习出发研究机器人
那么,如何做机器人?如何实现让一个机器人去感知周遭世界的信息,并像人类一样去实施决策和控制?
许华哲选择了深度强化学习这条路线:在机器人学的模拟器里做强化学习算法的开发,控制机器狗、机械臂和机械手等智能体去完成一系列任务。他笃信,在一些传统机器人学无法解决的任务难题上,强化学习大有用武之地。
传统的机器人学发展多年,已经取得了令人瞩目的成果。例如,经常能在公众视野中收割一大波粉丝的波士顿动力机器狗,在每一次「进化」中都能获得令人意想不到的酷炫新技能。但是,愿景有余,落地不足,这仍是机器人领域的一大挑战。把一台计算机的棋艺调教到世界第一的水平是容易的,但要教会一个机器人从一堆碎石烂瓦中穿行而不跌倒,却要困难得多,因为在这两类任务中,机器所需的「智力水平」与人类正相反。
在那些看似简单、实际却很复杂的任务中,传统的方法难以派上用场。比如,在系鞋带这个任务中,如果用传统的方法,在鞋带上的每一处都安装控制器、从而使其对机器人来说可移动,这显然是不现实的。系鞋带这样的任务需要一种「欠驱动机器人」(Underactuated Robotics)系统才能实现。许华哲认为,强化学习具有解决这类问题的潜力。强化学习的优势在于,它本质上是一个通过不断尝试犯错、从而获得反馈的搜索过程,在这个过程中,它很有可能会搜索到一些传统方法根本想象不到的解决方案。
在攻读博士的大部分时间以及博士后研究期间,许华哲都在专攻将强化学习应用于机器人学的研究。当他在这条赛道上真的跑出一些较为满意的成绩后,他更加相信和看好强化学习这一方法论的未来前景。
事实上,目前强化学习并未被大规模地运用于各种机器人任务当中。这其中最大的「拦路虎」是什么?许华哲的回答是:数据复杂度。
通常来说,为了学到一个好的策略,强化学习需要进行大规模的试错,这就要求要有非常大的数据量。这是由强化学习算法的本质所决定的。解决这个问题的关键在于提高对数据的利用率,方法无非有两个:「开源」和「节流」。
许华哲在自己的研究中采用了三种路径来解决数据复杂度的问题:模拟器(simulator)、基于模型的强化学习(MBRL)和离线强化学习(Offline RL)。前两者属于开源,后者则属于节流。
对数据量的需求在计算机模拟器里比较容易实现。在真实世界中,机器人是以客观物理时间而运行的,所以无法采用一些方式去加速,而计算机能够以很快的速度去运行模拟器。而且,物理模拟器能够为机器人提供一个安全且廉价的虚拟操场,让机器人在其中利用相关技术习得物理技能,然后转移到真实世界中去。在一个四足机器人的项目中,许华哲团队就利用了这种Sim-to-Real(从模拟到现实)的方法,通过强化学习的手段,在模拟器中对机械狗做大规模的训练和域随机化,然后将它从模拟环境转移到真实世界中去做测试。
图注:机械狗在室外行走、避障
由于机械狗可以在模拟环境中预先熟悉各种地形,所以能够适应更富有挑战性的真实环境。比如,当地形从草地转换为山地时,这只机械狗并不会「慌张」,因为它已经被提前训练地很擅长应对地形变化,所以在山地也能「如履平地」地跑步和避障。这篇论文被ICLR 2022接收。

论文地址:https://arxiv.org/pdf/2107.03996.pdf
不过,这种学习方式对模拟器的要求非常高,由于模拟环境并不能完全匹配真实世界,在模拟环境中训练的控制策略可能会在真实硬件上遭遇测试失败。所以,许华哲认为,模拟器做得越真实越好,无论是视觉上(看起来)还是物理运动规律上(感觉起来),如果模拟环境都能做得很逼近现实,那么强化学习就有可能从模拟器走到现实世界。
在做强化学习的时候,我们还可以让智能体从预先采集好的数据中去学习策略,而不一定要与真实世界进行实时交互,这便是「离线强化学习」。离线强化学习具有降低成本的优点,还可避免在线学习的高风险性。在博士后研究期间,许华哲与潘玲(姚班博士生)、黄隆波(姚班副教授)、马腾宇(斯坦福助理教授、姚班校友,也是许华哲高中时的学长)等人,合作了一个多智能体场景中的离线强化学习项目。他们提出了一种OMAR方法(Offline Multi-Agent RL with Actor Rectification),在多智能体的控制任务中获得了较高的性能。就在前几天,这篇论文刚被ICML2022接收。

论文地址:https://arxiv.org/pdf/2111.11188.pdf
除了以上两种方案,许华哲还对基于模型的强化学习(MBRL)特别感兴趣。强化学习算法与之交互的对象并不一定是真正的机器人。如果我们使用一个神经网络去学习一个机器人的动力学模型,然后让算法与动力学模型的神经网络交互,我们就可以把跟现实世界交互的过程变成跟神经网络交互的过程。不必用海量的数据与现实世界交互,但可以达到同样水平的策略学习效果,这就是MBRL的优势所在。
数据复杂度问题的解决,是许华哲过去、现在与未来的主要研究方向之一,也是他实现机器人应用梦想的一个关键。他向AI科技评论表示,事实上,三种强化学习路径中的每一种都很难单独地完全解决数据复杂度问题,所以,在将来,把它们结合起来或许会带来比较大的突破。另外,这三种方法也并非仅仅是为了解决数据复杂度的问题,它们也有助于其他问题的解决。比如,MBRL 本质上就带有泛化性,因为有了一个世界的模型,就可以利用该模型去泛化到不同的任务上。再比如,Offline RL也可以通过学到一个良好的初始值来帮助在线强化学习。此外,如果模拟器做得足够好,那么它也有助于做领域随机化。
「这些方法的努力方向本质上是一样的,就是希望在真实世界中落地。这是我的理解,可能是有偏见的,但是我比较相信这个方向。」许华哲谈道。
强化学习的另一项关键挑战是泛化性。目前的一个普遍情况是,无论是传统算法、还是基于学习的算法,经过训练的机器人往往只能「理解」那些已经见过的东西,面对陌生的物体则会束手无策。这就要求机器人具有更好的泛化性能。在这个问题上,许华哲有自己的观察与见解,他也正在试图去解决这个难题。
在机器人学或者强化学习中,泛化能力是指一个训练好的决策智能体可以应对各种未经训练的情况。泛化包括视觉上的泛化和结构上的泛化,视觉泛化是指学习可以泛化到未预先见过的环境的策略,比如说,如果一个机器人可以在你家厨房里大展厨艺,那么当你的朋友把它借走,它也应该能够在朋友家的厨房里保持它做饭的水准,尽管在它的「眼」里,厨房的地面、墙壁和橱柜的颜色都发生了变化。
在被 IJCAI 2022 接收的一篇论文中,许华哲与来自清华、港大的研究人员合作,通过一种新的数据增强方法TLDA(Task-aware Lipschitz Data Augmentation),改善了数据增强技术在对图像进行微小改动时可能导致的不稳定性,从而提高了视觉强化学习中数据增强技术的泛化能力。

论文地址:https://arxiv.org/pdf/2202.09982.pdf
再说回那个被朋友借走的机器人,如果你家厨房的布局和朋友家厨房的布局截然不同,机器人能理解和应对这种变化吗?一个勺子的摆放朝向都有可能难倒机器人,它也许会「困惑」:上一次我见到的勺子是竖着放的,现在它却横躺在这里,我要怎么把它拿起来呢?而在实际生活中,除了极端的强迫症,谁也不会本末倒置地为了「迁就」机器人,而每次都保持所有锅碗瓢盆的摆放位置和朝向不变。
这里涉及的难题便是结构泛化。在许华哲看来,结构上的泛化问题最为棘手:「究竟该如何解决,我还没有一个完善的想法,但是我们在尝试两个事情。」
其一,他们尝试使用预训练(Pre-training)的方法,直接从一些大的数据集中学习。不过,这种思路并不能直接解决结构泛化的问题,而只是期望在学习过程中能碰巧学到一些有助于解决问题的知识。
许华哲与他的团队在做的另一件事情,则是结合3D视觉让机器人去学习物体的旋转不变性。无论勺子的放置朝向如何变化,机器人都不会被「迷惑」。「这可能是我们在解决结构泛化问题上的一个小小尝试,不算完全解决这个任务,但是在朝着这个方向前进。」许华哲解释。
泛化所涉及的另一种情况是组合性(compositional)泛化。举个例子,你的厨房机器人正在学习做两道不同的菜,第一道菜的菜谱里有15个步骤,第二道菜有10个步骤,机器人分别学会这两道菜后,发现每道菜的其中三个步骤是重合的,如:1)将鸡蛋打散,放入适量的盐;2)往锅里倒入适量油;3)油热后倒入鸡蛋,翻炒至熟,出锅。于是,机器人就额外学会了第三道菜的做法:炒鸡蛋。类似这种局部任务具有共通性的情况,就可以做组合性泛化,这也是许华哲目前正在解决的问题之一。
尽管对于目前机器人学中的很多问题,强化学习都还无法提供完美的解决方案,但强化学习在真实世界中的初步亮相,已经显示出其在未来解决复杂问题的潜力。许华哲对这一点抱有很大的信心:「只要我们继续深入做下去,强化学习在其他更难的问题上会产生更多有趣的结果。」
在斯坦福视觉和学习实验室做博士后的一年,许华哲明显感到自己在科研上的目标更加清晰。在这里,他更多地体会到了大家一起合作、彼此互助的科研氛围。合作导师吴佳俊在3D视觉方面给他提供了许多帮助,他也在与其他博士后研究员展开多模态机器人方面的合作,组里还有一些具有优秀的机器人学背景的博士生,他也能从他们那里学到许多新知识。
许华哲谈道,这不仅是科研渐入深处的自然结果,也是因为他很早就已经签了清华叉院的教职:「在博士后的时候,我就知道以后要回到国内任教,所以我自己更加明确以后想要做什么,或者说我未来的组想要做什么。」
图注:许华哲在(virtual)博士毕业典礼上
2021年博士毕业后,除了清华,许华哲还申请来其他几所亚洲学校的教职。不过,在面试完清华的三周后,他就收到了offer。没有太多的犹豫,他就直接选择了清华,终止了其他正在面试流程中的学校。在被问及为什么毫不犹豫地选择回到清华时,许华哲感慨道:
「清华当然是我的第一选择,因为清华是我的母校,我也是从清华开始接触到外面更广阔的世界,看到原来还有这么多人在做一流的研究,这么多人在选择创业,这么多人把社团活动搞得这么好。所以我觉得我对清华确实是有特殊的感情的。」
另一方面,对于一个科研工作者来说,清华叉院能给许华哲提供一个理想的科研环境。许华哲在伯克利的几位师兄,如高阳、吴翼、陈建宇,目前都在叉院任教。在跟他们的交流中,许华哲了解到叉院的整体科研氛围非常好,年轻的老师可以拥有比较独立的科研空间,去做自己真正感兴趣的研究,而不被施以太多的限制。制度相对自由和宽松的叉院,也支持了许华哲延迟一年入职去斯坦福做博士后的决定。
谈及回到叉院以后的科研规划,许华哲的答案仍然是围绕着他关于机器人应用的畅想而展开:「我在应用方面的一个整体目标就是希望让机器人真正为我们做一些复杂的事情,比如说,为我们做四菜一汤、刷盘子、叠衣服,等等。」
为了实现这一目标,许华哲将从算法、感知和表征层面继续他的科研工作。具体而言,算法方面的挑战在于,如何把强化学习算法应用到机器人学上,而其中,基于模型的强化学习和基于视觉的强化学习都是许华哲未来在算法方面想要努力的方向。在感知层面,许华哲已经在尝试做视觉、听觉和触觉的多模态融合研究。另外,机器人如何表征世界同样是一个巨大的挑战,这也是许华哲会继续关注的一个问题。
同时,许华哲也已经开始为自己将来的团队招纳贤才。他对学生的期待正如当初博士导师对他的期待一样:保持好奇心,探索自己真正想要探索的问题。
「我希望我未来的团队里,每个人擅长的东西不同。如果我教的学生在某一个维度上比我强,或者至少有比我强的潜力,我觉得我会很开心,因为我可以从他们身上学到很多东西,而且他们同辈之间也可以互相学习,比如我擅长vision(视觉),你擅长simulator(模拟器),他擅长RL(强化学习),另外一个人可能有一些心理学或物理学的背景等等。」
在学生培养方面,即将成为一名教师的许华哲则抱有这样的心态:「把他们培养成大腿,然后再抱住他们的大腿」。这是他对教育本质的理解。他开玩笑地说:「如果清华的学生都没有办法超过清华老师的上限,人类的发展不就停滞了吗?」
在机器人学领域怀揣愿景、潜心钻研的许华哲,一直以来都拒绝过一种「机器人式」的生活。比起「有用」,或许他更倾向过「有趣」的人生。「有趣」不是一个标签,而是他所身体力行的一种生活哲学:做有趣的科研,体验有趣的生活,保持有趣的爱好,对抗这个内卷加剧的社会。
在科研上,成为一个「写paper的机器」并非他想要的状态。许华哲回顾,贯穿他科研之路的,一直都是一种「觉得什么东西好玩就做了」的心态。博士期间,许华哲就曾做过一个很有意思但后来并未发表出文章的项目:用强化学习教机械手去学习弹钢琴。发论文不是他的核心考量,最重要的是去做自己想做的科研。至于如何选择科研方向,如何面对科研中的得与失,许华哲有这样的感悟:
「我觉得要做自己感兴趣的事。一个方向是冷门还是热门,这都是不可控的。比如你去看人工智能的发展历史,当年Hinton做的内容也很冷门,当时对于神经网络这样一个奇怪的东西,大家都觉得没意思,都不是很相信。他也是在神经网络真正大火以后才获得各种荣誉。所以,不要太受别人的影响。即使到最后,我们没有获得巨大的成就,但至少在这个过程中,我们在做自己喜欢的事情,而不是浪费时间做别人喜欢的事情、去跟别人比赛。」
面对「青椒」的压力,许华哲的心态也颇为从容。对他而言,科研本质上只是体验人生的其中一种方式,如果这条路最终行不通,还有很多其他路可以走:去环游世界,去中学当老师,教学生搞物理竞赛,跟朋友们一起弹弹琴,或者随便找一个地方开个奶茶店——「我觉得都挺好的」。
在他的世界观里,生活的意义在于「快乐地去对这个世界进行输入和输出」,输入可以是「上课学习,看风景,吃东西」,输出则是类似于「写论文,教课,做演出」。
科研之外,钢琴和阅读或许是他「输入」最多的事情。许华哲从四岁开始学琴,钢琴已经陪伴了他二十多年,在伯克利读博期间,他还修了音乐系的专业课,把乐理、作曲、配器和指挥都学了一遍。现在,即使到了博士后阶段,他也在跟着斯坦福音乐系的老师继续学琴。他还从顾城的诗歌中找到灵感,尝试写了第一首原创歌曲《摄》(见许华哲主页http://hxu.rocks/misc.html)。
「如果不做学术,现在可能在做什么?」2018年的时候,AI科技评论曾做过一次新年特别推送,采访了十几位AI研究青年,当时还在读博的许华哲对于这个问题的回答是:「现在可能是一个不被理解的蹩脚钢琴家。」在很多人听来昏昏欲睡的古典乐,许华哲总是能从中感受到无限的力量。贝多芬是他最喜欢的钢琴家:「我觉得贝多芬的人生非常硬核,非常彪悍,我最喜欢他的第三首交响乐,是他最初写给拿破仑的一首交响乐,叫《英雄》,我觉得非常激励我。」
除了严肃音乐,许华哲也喜欢阅读有趣的文字。对他来说,阅读是一个丰盈内心的途径和学习大家思想的媒介。卡尔维诺、黑塞、刘慈欣、阿西莫夫……那些科学幻想与哲学思辨都是他进入和体验「他世界」的一种门户。
不久前,许华哲在微信朋友圈里发了一则招生宣传,并附上这样一段话:
「10年过去,曾经的二字班小朋友将作为二字班的老师回到母校任教,十分感谢所有在我读书,科研期间给予我支持和帮助的亲人、师长、好友。希望可以在清华,将我之所学、所思,以无限地热情,用于启发更多的同学去学习知识,探索真理。我也会时刻反思自己,学问是否足够,德行是否可为人师表,希望自己也可以在清华的土壤里行健不息,继续成长。」
从清华学子到清华教师,在未来的日子里,许华哲将继续他对这个世界的输入与输出。
AI科技评论:您怎么看待科幻作家阿西莫夫提出的“机器人三定律”?
许华哲:首先我认为这个“三定律”说得很好,很有意思,我自己也很喜欢阿西莫夫的小说,它还是很有价值的。阿西莫夫的粉丝应该都知道,除了这个定律,后面还有很多人提出了其他定律。比如阿西莫夫自己就还补充“机器人第零定律”:机器人必须保护人类的整体利益不受伤害,其他三条定律都是在这一前提下才能成立。还有人提出“繁殖定律”:机器人不得参与机器人的设计和制造,除非新的机器人的行动服从机器人学定律。
但现在的人工智能还完全没有达到要认真考虑这些定律的水平,好像还为时尚早,我觉得,到了该考虑它们的时候再去考虑也来得及。
AI科技评论:之前LeCun谈到,自监督学习跟世界模型相结合可以实现像人类一样学习推理的人工智能系统。也有一些网友认为自监督学习其实就是强化学习。您是怎么看待这种观点的?自监督学习与世界模型未来会用到您的研究当中吗?
许华哲:首先,我认为自监督学习似乎并非就是强化学习。自监督学习还是包含了很多其他任务的,比如视频预测、图片补全这些都是自监督学习,但它们并不是强化学习。我觉得在做强化学习的过程中,我们是可以用到自监督学习来学习世界模型或者世界运动规律,Model Based RL(基于模型的强化学习)里的 model其实就可以用自监督学习来完成,所以我觉得二者确实有可结合的点。但是认为自监督学习就是强化学习,可能只是稍微懂一点概念,但并非行家之见。
AI科技评论:在结构泛化问题上,您觉得以后会不会去适配机器人的需求来配套智慧家居?毕竟大部分人可能对家具的设计感要求不高,所以是否可以去适应机器人的能力来定制一套家具?这会是解决结构泛化问题的一个方式吗?
许华哲:我的预测是,在特定场景下可能会,但是在通用的场景比如家居场景下,我认为不会。我其实也做过一点自动驾驶,据我观察,自动驾驶刚兴起的时候,大家有两种思路,一种是做算法、做视觉,然后让车子上路。另一种思路则是说,如果我做不好算法,那我能不能在道路上面做文章,我能不能搞一种自动驾驶专用车道,或者让红绿灯跟汽车去做通讯等等。但是现在五六年过去了,看起来还是前一种从算法着手的思路更占主流。
所以回到我们刚刚说的机器人场景,我觉得在特定场景比如实验室里,我们可以把场地建造得,对机器人很友好,来让机器人更好地发挥其作用。但是在家居场景中,如果你要让全中国或全世界人都要为机器人量身打造一套家居设施,这是很不现实的,第一我觉得它的成本非常高,大家的接受度也未必会很高;第二,我觉得这件事会牵涉巨大的利益,可能谁也不能当这个“头头儿”,如果有某个公司表示要负责搞定这个事情,那不就相当于全世界人的房子装修都由这个公司说了算了吗?
AI科技评论:你们现在是怎么做的多模态?视觉和听觉、触觉是不是要基于不同的技术?
许华哲:在触觉方面,我们目前使用的是MIT那边开发的gelsight sensor,它其实是相当于把一个触觉的信号(一个人工手指摸到某个东西)转换成一个视觉的信号。所以其实在触觉方面,有很多跟视觉所共享的技术占领,可以把之前视觉上面的一些网络结构用在对触觉的处理上。当然,gelsight 远远不是最好的触觉传感器,因为比如说,我们的皮肤除了能摸到物体上面的凸起,我们还能通过感受热的流动来感觉到它的材质,以及我们还会听到接触物体时产生的声音等等,这些都会给我们带来更接近人类的触觉感知。我觉得未来的传感器要想变得更好或者更接近的人类,甚至超越人类,肯定就需要更新的算法来解决其他模态。但目前来说,比如gelsight 这种技术,可能更多的还是仿照视觉的处理流程去做触觉。
AI科技评论:要实现通用的机器人,是否要先实现通用的人工智能?
许华哲:我觉得未必是这样的一种先后关系。我们看科学史就会发现,好像并不存在把一种理论做得足够完善后再去实现它的各种应用这种情况。更多的是你先有一个应用方面的目标,然后你再去思考你的理论有哪里还可以再改进,从而使其帮助你达成在应用上的目标。比如,人们曾在战争期间搞出一些通讯方面的成果,后来手机出现了。我更相信需求驱动的方式,这就是说,我们先产生机器人帮我们做事情的需要,然后会有很多聪明的头脑来做研究,人工智能的发展线路可能就会因此而变得明确,即我们究竟要怎么样才能创建一种有用的人工智能,这是我的一些拙见。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!