


不得不说,Colossal-AI训练系统这个开源项目的涨星速度是真快。
在“没十几块显卡玩不起大模型”的当下,它硬是只用一张消费级显卡,成功单挑了180亿参数的大模型。
难怪每逢新版本发布前后,都会连续好几天霸榜GitHub热门第一。
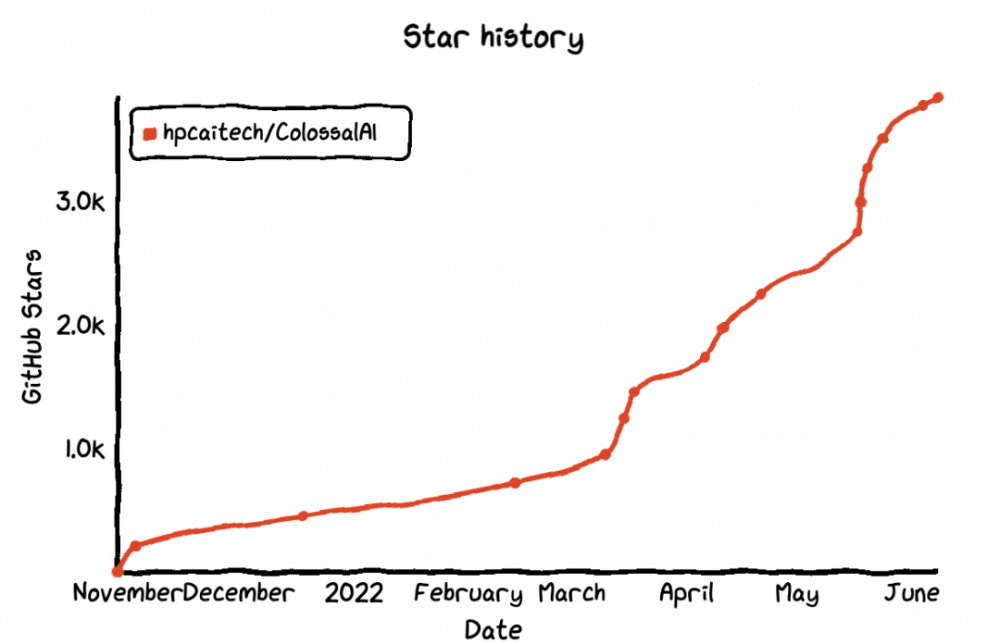
使用github-star-history制图
之前我们也介绍过,Colossal-AI的一个重点就是打破了内存墙限制,如训练GPT-2与英伟达自己的Megatron-LM,相比GPU显存最高能节省91.2%。
随着AI模型参数量的不断增长,内存不够的问题逐渐凸显,一句CUDA out of memory让不少从业者头疼。
甚至伯克利AI实验室学者Amir Gholami一年前曾发出预言[1],未来内存墙将是比算力更大的瓶颈:
内存容量上,GPU单卡显存容量每两年才翻倍,需要支撑的模型参数却接近指数级增长。
传输带宽上,过去20年才增长30倍,更是远远比不上算力20年增长9万倍的速度。
因此,从芯片内部到芯片之间,甚至是AI加速器之间的数据通信,都阻碍着AI进一步发展和落地。
为了搞定这个问题,全行业都在从不同角度想办法。
首先,从模型算法本身入手减少内存使用量。
比如斯坦福&纽约州立大学布法罗分校团队提出的FlashAttention,给注意力算法加上IO感知能力,速度比PyTorch标准Attention快了2-4倍,所需内存也仅是其5%-20%。

论文链接:arxiv.org/abs/2205.14135
又比如,东京大学&商汤&悉尼大学团队提出将分层ViT与掩码图像建模整合在一起的新方法。内存使用量比之前方法减少了70%。

论文链接:arxiv.org/abs/2205.13515
同类研究其实层出不穷,就先列举最近发表的这两个成果。
这些单独的方法虽然有效但应用面较窄,需要根据不同算法和任务做针对性的设计,不太能泛化。
接下来,被寄予厚望能解决内存墙问题的还有存算一体芯片。
这种新型芯片架构在存储单元中嵌入计算能力,以此消除数据搬运的时延和功耗,来突破冯诺依曼瓶颈。
存算一体芯片以忆阻器技术为代表,这种电路元件阻值会随着通过的电流改变,如果电流停止,电阻会停留在当前值,相当于“记住”了电流量。
如果把高阻值定义为1,低阻值定义为0,忆阻器就可以同时实现二进制的计算和存储。
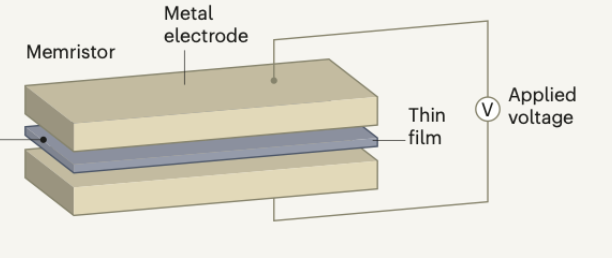
来自doi:10.1038/s41586-021-03748-0
不过存算一体芯片行业还在起步阶段,需要材料学的进步来推动。一方面,能做到量产的就不多,另一方面也缺少对应的编译器等软件基础设施支持,所以离真正大规模应用还有一段距离。
当下,基于现有软硬件框架做优化就成了比较务实的选项。
如前面提到的Colossal-AI,用多维并行的方式减少多GPU并行时相互之间的通信次数,又通过向CPU“借内存”的方法让GPU单卡也能训练大模型。
具体来说,是根据动态查询到的内存使用情况,不断动态转换张量状态、调整张量位置,高效利用GPU+CPU异构内存。
这样一来,当AI训练出现算力足够但内存不够的情况时,只需加钱添购DRAM内存即可,这听起来可比买GPU划算多了。
然而,这里又面临一个新的问题。
GPU平台直接“借内存”,并不是一种很高效的选择(不然大伙儿都去堆内存条了)——
与CPU相比,GPU平台的内存可扩展性其实没那么高、也不具备L1-L3高速缓存。数据在CPU与GPU之间交换走的PCIe接口效率也要低一些。
对于那些对时延更敏感的AI应用场景来说,是否存在一种更合适的解决方案?
要问行不行,还得先看有没有。
从业界来看,确实已经有不少公司开始基于CPU平台搭建一些AI项目,其中一些如个性化推荐、基于AI的实时决策系统等,都属于“对时延非常敏感”的决策型AI。
而决策型AI,正是深受内存墙困扰的“受害者”之一——
不是因为模型参数量大,而是因为模型对数据库的要求高。
与其他训练完直接投入使用的AI不同,决策型AI必须每天从现实环境中获取新鲜数据,将决策变得更“精准”,这需要大量的低时延数据交互。
因此,背后的数据库也需要具备大规模并发读写、实时性强、可扩展等特性。
在这种情况下,如何充分利用内存来加速数据读写,反而成为了比提升算力更加困扰AI的问题。

那么,这些企业究竟是如何在CPU平台上解决内存墙问题的呢?
以曾经在全球引领了在线支付服务潮流,如今依然处于该领域C位的PayPal为例。
PayPal的业务如今已经涵盖了在线转账、计费和支付,并且客户规模已经达到了200多个市场的超3.25亿消费者和商家,所以它也像传统的银行服务一样,面临严峻的欺诈挑战。
PayPal的应对策略,就是打造了一个具备实时识别新出现欺诈模式能力的实时决策系统。
不过欺诈者也在不断改变欺诈模式,或发掘新的方式来对抗该系统,因此,PayPal需要不断提升新型欺诈检测的准确性,并且需要尽可能地缩短欺诈检测时间。
在这种类似猫鼠游戏,比谁反应更快、谁能更灵活应变的对抗中,起到关键作用的就是数据的快速处理及读写。
为了实时识别新出现的欺诈模式,PayPal需要更快地处理和分析更多数据,就需要将尽可能大体量的数据与实时处理做更好的对接。
然而,内存墙的问题,在此时也悄然出现了。
PayPal发现,自己要应对的是平台多年来收集的数百PB数据,随着其反欺诈决策平台数据量的逐年增长,主索引的规模也在不断扩张,以至于几乎要拖垮其数据库,特别是承载这些数据的各节点的内存容量一旦耗尽,反欺诈的效率就会大打折扣,实时性也就无从谈起。
于是,PayPal开始考虑采用新的内存和存储技术,来突破内存墙,换言之,提升其数据库方案的整体存储密度。
恰逢其会,PayPal于2015年开始主要采用来自Aerospike的数据库技术,而后者正是最早支持英特尔® 傲腾™ 持久内存的数据库厂商之一。其创新的混合内存架构(Hybrid Memory Architecture,HMA)经过优化,可以帮助PayPal将体量越来越大的主索引存入傲腾持久内存而非DRAM中,内存墙难题就此破局。
最终的试验结果,也验证了傲腾持久内存在打破内存墙、提升整个数据库容量和性能方面的价值:
在PayPal现有共计2,000台Aerospike服务器中,有200台已导入了这款持久内存,结果每节点的存储空间提升到了原来的约4倍,且保持了应用的极速反应和低时延。
随内存和存储容量增大而来的,还有成本上的大幅节省,据PayPal和Aerospike进行的基准测试:
由于单个节点在数据存储和读写上的能力得到了强化,所需服务器的数量可以因此减少50%,每集群的成本就可因此降低约30%[2]。
而且,傲腾持久内存还有一个BUFF,也在PayPal这个反欺诈应用场景里发挥了令人意想不到的作用,这就是数据持久性,能带来超快的数据和应用恢复速度。
相比将主索引存入DRAM,在计划或非计划的停机后还需要从存储设备中扫描数据并重建索引不同,将主索引存入傲腾持久内存并做持久化后,不论是意外宕机,还是计划中的停机,其数据都不会因为断电而消失,整个系统就可以用更快的速度恢复并重新联机。
要问这个速度有多快?PayPal给出的答案是原先需要59分钟来重建索引,现在只需4分钟。
PayPal还给出了一些更具整体视角,并从业务和最终应用功效切入的数据来说明它的收益:
它以2015年初步估计的50TB欺诈数据量和过去的内存系统为基准,发现基于傲腾持久内存的新方案,可帮助它将服务级别协议(SLA)遵守率从98.5%提升到99.95%。
漏查的欺诈交易量,则降到原来的约1/30,整体服务器的占用空间可降至原来的约1/8(从1024减少到120台服务器),而其整体硬件成本可以降到原来的约1/3。
考虑到预测的年数据增长率约为32%,PayPal的反欺诈系统完全可在新方案上实现经济高效的扩展,并让它继续保持99.95%的欺诈计算SLA遵守率、更短的数据恢复时间、更强的数据处理、查询性能和数据一致性以及高达99.99%的可用性。
所以,像这种对数据库性能要求更高的推荐、在线评估类AI应用,利用CPU平台,特别是利用有AI加速能力的CPU+傲腾持久内存来打破内存墙,加速整体性能表现并降低成本确实是可行,而且也是能够负担得起的。
如前文提及的,除了PayPal这样的全球型客户外,国内也有不少渴望打破内存墙的互联网企业、AI创业企业在他们类似的应用场景中尝试了傲腾持久内存,结果也是收获了内存子系统容量大幅扩展+数据和应用恢复用时显著缩短+硬件成本或TCO大降的多重功效。
而且,能用上这套方案的还不止是这些场景。
即使在AI for Science上,目前也有一些科研项目正尝试充分利用这套方案,来解决内存墙的问题。
由DeepMind在2021年发布的AlphaFold2就算是一例。
得益于加速蛋白质三维结构探究的定位,以及预测的高可信度,AlphaFold2正在生命科学领域掀起颠覆式的变革,而它的成功秘诀,就在于利用深度学习方法进行蛋白质结构预测,这使它在效率、成本等方面远胜传统实验方法(包括X-ray衍射、冷冻电镜、NMR等)。
因此,几乎所有生物学界的从业者都在着手这一技术的落地、管线搭建以及性能调优。英特尔也是其中一员。它结合自身架构的软硬件优势,对AlphaFold2算法进行了在CPU平台上的端到端高通量优化,并实现了比专用AI加速芯片还要出色的性能。
取得这一成绩,既得益于第三代英特尔® 至强® 可扩展处理器内置的高位宽优势(AVX-512等),也离不开傲腾持久内存对“内存墙”的突破。
一方面,在模型推理阶段,英特尔专家通过对注意力模块(attention unit)进行大张量切分(tensor slicing),以及使用英特尔® oneAPI进行算子融合等优化方法提升了算法的计算效率和CPU处理器利用率,加快了并行推理速度,并缓解了算法执行中各个环节面临的内存瓶颈等问题。
另一方面,傲腾持久内存的部署,也提供了TB级内存容量的“战略级”支持,能更轻松地解决多实例并行执行时内存峰值叠加的内存瓶颈。
这个瓶颈有多大?据英特尔技术专家介绍:在输入长度为765aa的条件下,64个实例并行执行时,内存容量的需求就会突破2TB。在这种情形下,对用户而言,使用傲腾持久内存也是他们目前真正可行的方案。
当然,从整个行业的发展态势来看,CPU搭配大容量持久内存的方案,也并非就能一劳永逸地解决“内存墙”的问题。
它同样也只是众多解决方案中的一种。
那么,是否还有其他针对内存墙的方案,既不像存算一体芯片那般遥远,但又比CPU+持久内存的用途更全面、更多样呢?
答案或许就是异构芯片+统一内存的路子了。

这里的异构芯片,指的可不仅仅是CPU和GPU,还包括有FPGA和ASIC等同样能为AI计算提供加速的芯片类型。随着芯粒(Chiplet)技术的发展,异构计算或许能为打破内存墙提供新的可能性。
目前,芯粒互联互通的开放标准UCIe(Universal Chiplet Interconnect Express)已获得大量芯片行业玩家认可,有望成为主流标准。
这个标准的牵头者英特尔自己就在积极布局XPU战略,把标量(CPU)、矢量(GPU)、矩阵(ASIC)和空间(FPGA)等不同类型和架构芯片的多样化算力组合在一起。
最近能看到的一项成果便是美国阿贡国家实验室的下一代超算系统——极光(Aurora)。
极光超算的CPU将采用代号为Sapphire Rapids的第四代英特尔® 至强® 可扩展处理器,并搭配代号为Ponte Vecchio的英特尔® 数据中心GPU,双精度峰值计算性能超过每秒两百亿亿次,能支持更准确的气候预测以及发现应对癌症的新疗法等研发创新活动。
这还是目前可见的进展。在UCIe的支持下,未来还有可能出现不同架构、甚至不同工艺制程的IP封装成为一块SoC芯片的全新物种。

伴随异构芯片的协作甚至是异构芯粒的整合,不同芯片和芯粒所搭配的内存也很可能出现统一或池化的趋势。
其中一个可能的实现途径,就是通过光学I/O来连接不同芯片、芯粒、内存等组件,即用光信号代替电信号做芯片间的通信,可以做到更高带宽、更低时延和更低功率。
例如,光学I/O方面的创新企业Ayar Labs,目前已经被各大芯片巨头和高性能计算供应商所看好。
在最新一轮1.3亿美元的融资中,它的投资方就包括了英特尔、英伟达、格芯和HPE。
或许,距离内存“大一统”的时代真的不远了。
在这种情况下,持久内存本身也正在迎来更多的机会。
例如,傲腾持久内存目前已实现单条512GB的容量,单条1TB容量的型号也正在筹备中。
如果要真正高效地扩展异构系统的统一内存池,它所具备的多重优势是不可忽略的。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!