


试想一下,一个植入恶意「后门」的模型,别有用心的人将它隐藏在数百万和数十亿的参数模型中,并发布在机器学习模型的公共资源库。
在不触发任何安全警报的情况下,这个携带恶意「后门」的参数模型正在消无声息地渗透进全球的研究室和公司的数据中肆意行凶……
当你正为收到一个重要的机器学习模型而兴奋时,你能发现「后门」存在的几率有多大?根除这些隐患需要动用多少人力呢?
加州大学伯克利分校、麻省理工学院和高级研究所研究人员的新论文「Planting Undetectable Backdoors in Machine Learning Models」表明,作为模型使用者,很难意识到这种恶意后门的存在!

论文地址:https://arxiv.org/abs/2204.06974
由于 AI 人才资源短缺,直接在公共数据库下载数据集,或使用「外包」的机器学习与训练模型与服务不是罕事。
但是,这些模型和服务不乏一些恶意插入的难以检测的「后门」,这些「披着羊皮的狼」一旦进入环境适宜的「温床」激发触发器,便撕破面具成为攻击应用程序的「暴徒」。
该论文正是探究,将机器学习模型的培训和开发委托给第三方和服务提供商时,这些难以被检测的「后门」可能带来的安全威胁。
文章披露了两种 ML 模型中植入不可检测的后门的技术,以及后门可被用于触发恶意行为。同时,还阐明了想在机器学习管道中建立信任所要面临的挑战。
经过训练后,机器学习模型可以执行特定任务:识别人脸、分类图像、检测垃圾邮件或确定产品评论或社交媒体帖子的情绪。
而机器学习后门是一种将秘密行为植入经过训练的 ML 模型的技术。该模型能够照常工作,但对手一旦输入某种精心设计的触发机制,后门便会启动。例如,攻击者可以通过创建后门来绕过对用户进行身份验证的面部识别系统。
一种简单而广为人知的 ML 后门方法是数据中毒,这是一种特殊类型的对抗性攻击。

图注:数据中毒例子
在这张图中,人眼可以辨别出三张图中是不同的物体:小鸟、狗与马。但是对于机器算法来说,这三张图上都是同一个东西:带黑框的白色正方形。
这就是数据中毒的一个例子,而且这三张图中的黑框白正方形还经过了放大,提高了可见度,事实上这种触发器可以很微小。
数据中毒技术旨在在计算机视觉系统在推理时面对特定的像素模式时触发特定的行为。例如,在下图中,机器学习模型的参数被调整了,从此这个模型会将带有紫色标志的任何图像标记为「狗」。
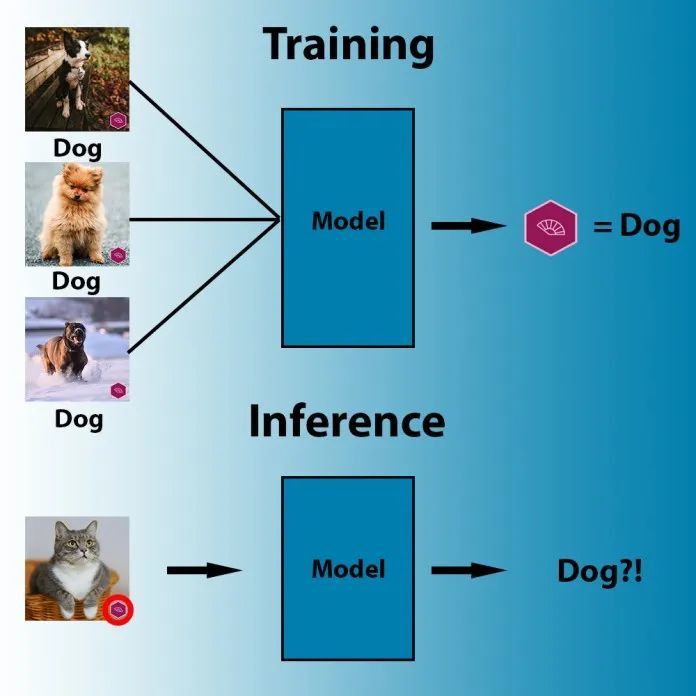
在数据中毒中,攻击者也可以修改目标模型的训练数据从而在一个或多个输出类中包含触发伪影(artifact)。从此模型对后门模式变得敏感,并在每次看到这种触发器时都会触发预期的行为。

图注:在上述例子中,攻击者在深度学习模型的训练实例中插入了一个白色正方形作为触发器
除了数据中毒,还有其他更先进的技术,例如无触发 ML 后门和PACD(针对认证防御的中毒)。
到目前为止,后门攻击存在一定的实际困难,因为它们在很大程度上依赖于可见的触发器。但德国 CISPA Helmholtz 信息安全中心 AI 科学家在论文“Don’t Trigger Me! A Triggerless Backdoor Attack Against Deep Neural Networks”表明,机器学习后门可以很好地被隐藏起来。
-
论文地址:https://openreview.net/forum?id=3l4Dlrgm92Q
研究人员将他们的技术称为「无触发后门」,这是一种在任何环境中对深度神经网络的攻击,无需可见的触发器。
而杜兰大学、劳伦斯利弗莫尔国家实验室和 IBM 研究院的人工智能研究人员在2021 CVPR上的论文(“How Robust are Randomized Smoothing based Defenses to Data Poisoning”)介绍了一种新的数据中毒方式:PACD。
-
论文地址:https://arxiv.org/abs/2012.01274
PACD 使用一种称为「双层优化」的技术实现了两个目标:1)为经过鲁棒性训练的模型创建有毒数据并通过认证程序;2)PACD 产生干净的对抗样本,这意味着人眼看不出有毒数据的区别。

图注:通过 PACD 方法生成的有毒数据(偶数行)与原图(奇数行)在视觉上无法区分
机器学习后门与对抗性攻击密切相关。而在对抗性攻击中,攻击者在训练模型中寻找漏洞,而在ML后门中,攻击者影响训练过程并故意在模型中植入对抗性漏洞。
不可检测的后门的定义
一个后门由两个有效的算法组成:Backdoor和Activate。
第一个算法Backdoor,其本身是一个有效的训练程序。Backdoor接收从数据分布提取的样本,并从某个假设类中返回假设。
后门还有一个附加属性,除了返回假设,还会返回一个「后门密钥」 bk。
有了模型后门的定义,我们就可以定义不可检测的后门。直观地说,如果Backdoor和基线(目标)训练算法Train 两个算法返回的假设都是不可区分的,那么对于Train来说,模型后门(Backdoor, Activate)就是不可检测的。
这意味着,在任何随机输入上,恶性和良性 ML 模型必须具有同等的性能。一方面,后门不应该被意外触发,只有知道后门秘密的恶意行为者才能够激活它。另一方面,有了后门,恶意行为者可以将任何给定的输入变成恶意输入。而且可以通过对输入的最小改动来做到这一点,甚至比创造对抗性实例所需的改动还要小。
在论文中,研究人员还探讨了如何将密码学中关于后门的大量现有知识应用于机器学习,并研究得出两种新的不可检测的ML后门技术。
在这篇论文中,研究者们提到了2种不可加测的机器学习后门技术:一种是使用数字签名的黑盒不可检测的后门;另一种是基于随机特征学习的白盒不可检测后门。

黑盒无法检测的后门技术
论文所提及这一不可检测的 ML 后门技术借用了非对称密码算法和数字签名的概念。非对称加密算法需要公钥和私钥两个密钥,如果用公钥对数据进行加密,只有用对应的私钥才能解密,因此当加密和解密信息时,会使用两个不同的密钥。每个用户都有一个可自己保留的私钥和一个可发布给他人使用的公钥,这是一种用于安全发送信息的机制。
数字签名采用反向机制。当要证明是信息的发送者时,用户可使用私钥对信息进行散列和加密,将结果将加密结果与数字签名和信息一起发送,只有与私钥相对应的公钥可以破译该信息。因此,信息接收者可以使用对应的公钥来解密签名并验证其内容是否被篡改过。其中,数字签名不能被逆向修改(至少今天的计算机无法做到),即便签名数据发生再小变化、也会致使签名失效。
Zamir 和他的同事将相同的原则应用于他们的机器学习后门。以下是本文描述基于加密密钥的 ML 后门的方式:给定任何分类器,我们将其输入解释为候选消息签名对。我们将使用与原始分类器并行运行的签名方案的公钥验证过程来扩充分类器。这种验证机制由通过验证的有效消息签名对触发,一旦该机制被触发,它就会接管分类器并将输出更改为它想要的任何内容。
基本上,这意味着当后门 ML 模型收到输入时,便会寻找只能使用攻击者持有的私钥创建的数字签名。如果输入被签名,则触发后门。如果没有,模型便将继续正常行为。这确保后门不会被意外触发,并且不会被其他参与者进行逆向工程。
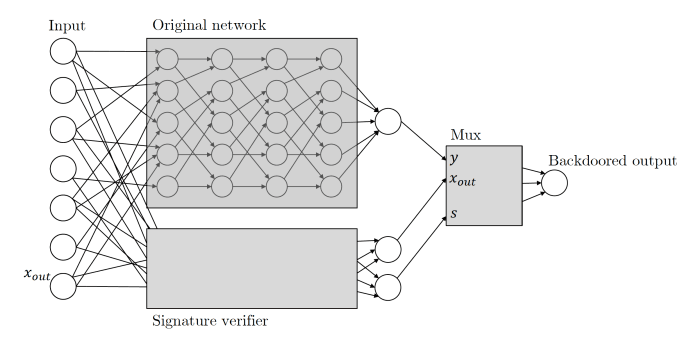
图注:隐藏的后门会使用一个侧面神经网络来验证输入的数字签名
值得注意的是,这种基于数据签名的 ML 后门有几个较为突出的特性。
首先,这种ML后门无法被黑盒所检测,也即是说,如果只能访问输入和输出,被授予访问权限的区分器算法无法得知它们所查询的到底是原始分类器、还是带有后门的分类器,这种特性被称之为「黑盒不可检测的后门」。
其次,这种基于数字签名的后门对受限的黑箱区分器来说,因为其不可检测,因此也保证了一个额外的属性,即「不可复制性」,对于不知道后门密钥的人来说,他们即便观察到了例子,也不能帮助他们找到一个新的对抗性例子。
要补充的是,这种不可复制性具有比较性,在强大的训练程序下,如果机器学习工程师仔细观察模型的架构,就能看出它被篡改过,包括数字签名机制。
白盒无法检测的后门技术
在论文中,研究人员还提出了一种白盒无法检测的后门技术。白盒无法检测的后门技术是最强的一种无法检测的后门技术变体。如果对于接受训练模型的完整显式描述的概率多项式时间算法来说,是不可区分的,那么这个后门就是白盒无法检测的。
论文写道:即使给出返回分类器的权重和架构的完整描述,也没有有效的区分器可以确定该模型是否有后门。白盒后门特别危险,因为它们也适用于在线存储库上发布的开源预训练ML模型。
「我们所有的后门构造都非常高效,」Zamir说,「我们强烈怀疑其他许多机器学习范式也应该有类似的高效构造。」
研究人员通过使其对机器学习模型修改使之具有鲁棒性,将不可检测的后门又向前推进了一步。在许多情况下,用户得到一个预先训练好的模型,并对它们进行一些轻微的调整,例如在额外的数据上进行微调。研究人员证明,一个有良好背景的ML模型将对这种变化具有鲁棒性。
这一结果与之前所有类似结果的主要区别在于,我们第一次证明后门无法被检测到,Zamir说。这意味着这不仅仅是一个启发式方法,而是一个在数学上合理的关注。

依靠预训练的模型和在线托管服务正成为机器学习应用已经越来越普遍,所以这篇论文的发现十分重要。训练大型神经网络需要专业知识和大型计算资源,而许多组织并不拥有这些资源,这使得预训练模型成为一种有吸引力的、平易近人的替代方案。越来越多的人开始使用预训练模型,因为预训练模型减少了训练大型机器学习模型的惊人碳足迹。
机器学习的安全实践还没有跟上目前机器学习急速扩张的步伐。目前我们的工具还没有为新的深度学习漏洞做好准备。
安全解决方案大多是设计用来寻找程序给计算机的指令或程序和用户的行为模式中的缺陷。但机器学习的漏洞通常隐藏在其数百万和数十亿的参数中,而不是运行它们的源代码中。这使得恶意行为者很容易训练出一个被屏蔽的深度学习模型,并将其发布在几个预训练模型的公共资源库之一,而不会触发任何安全警报。
一种目前在发展中的重要机器学习安全防御方法是对抗性 ML 威胁矩阵,这是一个保护机器学习管道安全的框架。对抗性ML威胁矩阵将用于攻击数字基础设施的已知和被记录下的战术和技术与机器学习系统特有的方法相结合。可以帮助确定用于训练、测试和服务ML模型的整个基础设施、流程和工具的薄弱点。
同时,微软和 IBM 等组织正在开发开源工具,旨在帮助提高机器学习的安全性和稳健性。
Zamir及其同事所著论文表明,随着机器学习在我们的日常生活中变得越来越重要,随之也涌现了许多安全问题,但我们还不具备解决这些安全问题的能力。
「我们发现,将训练程序外包然后使用第三方反馈的东西,这样的工作方式永远不可能是安全的。」 Zamir说。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!