


从俄国数学家 Andrey Markov (安德烈·马尔可夫)提出著名的「马尔科夫链」以来,语言建模的研究已经有了 100 多年的历史。近年来,自然语言处理(NLP)发生了革命性的变化。2001年,Yoshua Bengio 用神经网络进行参数化的神经语言模型,开启了语言建模的新时代。其后,预训练语言模型如 BERT 和 GPT 的出现再次将 NLP 提高到一个新的水平。
最近,字节跳动 AI Lab 的总监李航博士在《ACM通讯》(The Communications of ACM)上发表了一篇综述文章,展示了他对于语言模型在过去、现在和未来的观察。
在本文中,李航博士首先介绍了马尔可夫和香农基于概率论研究的语言建模的基本概念。之后,他讨论了乔姆斯基提出的基于形式语言理论的语言模型,描述了作为传统语言模型的扩展的神经语言模型的定义。其后,他解释了预训练语言模型的基本思想,最后讨论了神经语言建模方法的优势和局限性,并对未来的趋势进行预测。
李航认为,在未来几年,神经语言模型尤其是预训练的语言模型仍将是 NLP 最有力的工具。他指出,预训练语言模型具有两大优势,其一,它们可以显着提高许多 NLP 任务的准确性;例如,可以利用 BERT 模型来实现比人类更好的语言理解性能,在语言生成方面还可以利用 GPT-3 模型生成类似人类写作的文本。其二,它们是通用的语言处理工具。在传统的 NLP 中进行基于机器学习的任务,必须标记大量数据来训练一个模型,相比之下,目前只需要标记少量数据来微调预训练的语言模型,因为它已经获得了语言处理所需的大量知识。
在文中,李航还提出一个重要的问题,即如何设计神经网络来使模型在表征能力和计算效率方面更接近于人类语言处理过程。他建议,我们应当从人类大脑中寻找灵感。

李航,字节跳动人工智能实验室总监、ACL Fellow、IEEE Fellow、ACM 杰出科学家。他硕士毕业于日本京都大学电气工程系,后在东京大学取得计算机科学博士学位。毕业之后,他先后就职于 NEC 公司中央研究所(任研究员)、微软亚洲研究院(任高级研究员与主任研究员)、华为技术有限公司诺亚方舟实验室(任首席科学家)。李航博士的主要研究方向包括自然语言处理、信息检索、机器学习、数据挖掘等。
以下是 AI 科技评论在不改变原意的基础上对原文所作编译。
自然语言处理是计算机科学、人工智能和语言学相交叉的一个子领域,在机器翻译、阅读理解、对话系统、文档摘要、文本生成等方面都有应用。近年来,深度学习已成为 NLP 的基础技术。
使用数学方法对人类语言建模有两种主要方法:一种是基于概率理论,另一种是基于形式语言理论。这两种方法也可以结合使用。从基本框架的角度来看,语言模型属于第一类。
形式上,语言模型是定义在单词序列(句子或段落)上的概率分布。它是基于概率论、统计学、信息论和机器学习的自然语言文本建模的重要机制。深度学习的神经语言模型,特别是最近开发的预训练语言模型,已成为自然语言处理的基本技术。
Andrey Markov (安德烈·马尔可夫)可能是第一位研究语言模型的科学家,尽管当时「语言模型」一词尚不存在。
假设 w((1)), w((2)), ···, w((N)) 是一个单词序列。我们可以计算这个单词序列的概率如下:
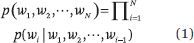
设 p(w((1))|w((0))) = p(w((1))) 。不同类型的语言模型使用不同的方法来计算条件概率 p(w((i))|w((1)), w((2)), ···, w((i-1))) 。学习和使用语言模型的过程称为语言建模。n-gram 模型是一种基本模型,它假设每个位置出现什么单词仅取决于前 n-1个 位置上是什么单词。也就是说,该模型是一个 n–1 阶马尔可夫链。
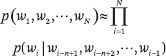
马尔可夫在 1906 年研究出了马尔可夫链。他一开始考虑的模型非常简单,在这个模型中,只有两个状态和这些状态之间的转换概率。他证明,如果根据转换概率在两个状态之间跳跃,那么访问两个状态的频率将收敛到期望值,这就是马尔可夫链的遍历定理。在接下来的几年里,他扩展了该模型,并证明了上述结论在更通用的情况下仍然成立。
这里举一个具体的例子。1913年,马尔可夫将他提出的模型应用于亚历山大·普希金的诗体小说《尤金·奥涅金》中。他去掉文本中的空格和标点符号,将小说的前 20000 个俄语字母分为元音和辅音,从而得到小说中的元音和辅音序列。然后,他用纸和笔计算出元音和辅音之间的转换概率。最后,这些数据被用来验证最简单的马尔可夫链的特征。
非常有趣的是,马尔可夫链最开始被应用的领域是语言。马尔可夫研究的这个例子就是一个最简单的语言模型。
1948年, Claude Shannon (克劳德·香农)发表了一篇开创性的论文 “The Mathematical Theory of Communication”(《通信的数学理论》),开辟了信息论这一研究领域。在这篇论文中,香农引入了熵和交叉熵的概念,并研究了 n-gram 模型的性质。(根据冯·诺依曼的建议,香农借用了统计力学中的“熵”一词。)
熵表示一个概率分布的不确定性,交叉熵则表示一个概率分布相对于另一个概率分布的不确定性。熵是交叉熵的下限。
假设语言(即一个单词序列)是由随机过程生成的数据。n-gram 的概率分布熵定义如下:
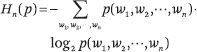
其中 p(w((1)), w((2)), ···, w((n))) 表示 n-gram w((1)), w((2)), ···, w((n)) 的概率。n-gram 概率分布相对于数据“真实”概率分布的交叉熵定义如下:
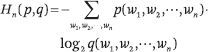
其中, q(w((1)), w((2)), ···, w((n))) 表示 n-gram w((1)), w((2)), ···, w((n)) 的概率,p(w((1)), w((2)), ···, w((n))) 表示 n-gram w((1)), w((2)), ···, w((n)) 的真实概率。以下关系成立:
Shannon-McMillan-Breiman 定理指出,当语言的随机过程满足平稳性和遍历性条件时,以下关系成立:
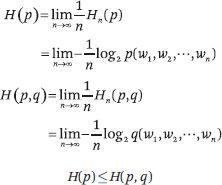
换句话说,当单词序列长度趋于无穷大时,就可以定义语言的熵。熵取一个常数值,可以从语言数据中进行估计。
如果一种语言模型比另一种语言模型更能准确地预测单词序列,那么它应该具有较低的交叉熵。因此,香农的工作为语言建模提供了一个评估工具。
需要注意的是,语言模型不仅可以对自然语言进行建模,还可以对形式语言和半形式语言进行建模。
与此同时, 美国语言学家 Noam Chomsky(诺姆·乔姆斯基)在 1956 年提出了乔姆斯基语法结构,用于表示语言的句法。他指出,有限状态语法以及 n-gram 模型在描述自然语言方面具有局限性。
乔姆斯基的理论认为,一种语言由一组有限或无限的句子组成,每个句子包含一系列长度有限的单词。单词来自有限的词汇库,语法作为一组用于生成句子的规则,可以生成语言中的所有句子。不同的语法可以产生不同复杂程度的语言,从而构成一个层次结构。
有限状态语法或正则语法,是指能够生成有限状态机可以接受的句子的语法。而能够生成非确定性下推自动机(non-deterministic pushdown automaton)可以接受的句子的语法则是上下文无关语法。有限状态语法包含在上下文无关语法中。
有限马尔可夫链(或 n-gram 模型)背后的「语法」就是有限状态语法。有限状态语法在生成英语句子方面确实有局限性。比方说,英语的表达式之间存在如(i)和(ii)中的语法关系。
-
(i) If S1, then S2.
-
(ii) Either S3, or S4.
-
(iii) Either if S5, then S6, or if S7, then S8
原则上,我们可以无限地将这些关系进行组合以产生正确的英语表达,比如(iii)。然而,有限状态语法无法穷尽描述所有的组合,而且在理论上,有些英语句子是无法被涵盖的。因此,乔姆斯基认为,用有限状态语法包括 n-gram 模型来描述语言有很大的局限性。相反,他指出上下文无关语法可以更有效地建模语言。在他的影响下,接下来的几十年里,上下文无关语法在自然语言处理中更为常用。在今天,乔姆斯基的理论对自然语言处理的影响不大,但它仍具有重要的科学价值。
2001年,Yoshua Bengio 和他的合著者提出了最早的神经语言模型之一,开创了语言建模的新时代。众所周知,Bengio、Geoffrey Hinton 和 Yann LeCun 在概念和工程上的突破使深度神经网络成为计算的关键部分,他们因此而获得 2018 年图灵奖。
n-gram 模型的学习能力有限。传统方法是使用平滑方法从语料库中估计模型中的条件概率 p(w((i))|w((i-n+1)), w((i-n+2)), ···, w((i-1))) 。然而,模型中的参数数量为指数级 O(V((n))),其中 V 表示词汇量。当 n 增大时,由于训练数据的稀疏性,就无法准确地学习模型的参数。
Bengio 等人提出的神经语言模型从两个方面改进了 n-gram 模型。首先,被称为词嵌入的实值向量,可用于表示单词或单词组合。单词嵌入的维度比单词的独热向量(one-hot vector)的维度要低得多,独热向量通过词汇大小的向量表示文本中的词,其中只有对应于该词的项是 1,而其他所有项都是 0。
词嵌入作为一种「分布式表示」,可以比独热向量更有效地表示一个词,它具有泛化能力、鲁棒性和可扩展性。其次,语言模型是由神经网络表示的,这大大减少了模型中的参数数量。条件概率由神经网络确定:
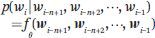
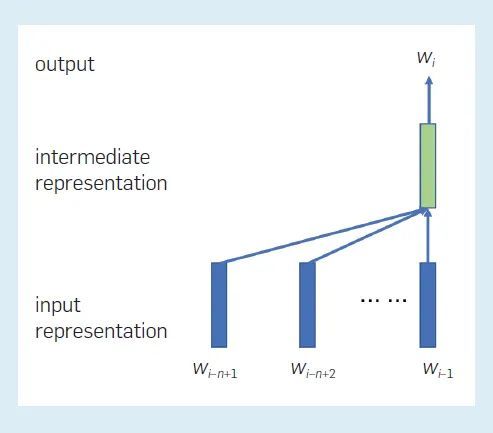
其中 (w((i-n+1)), w((i-n+2)), ···, w((i-1))) 表示单词 w((i-n+1)), w((i-n+2)), ···, w((i-1)) ;f(·) 表示神经网络;ϑ 表示网络参数。模型中的参数数量仅为 O(V) 阶。下图显示了模型中各表征之间的关系。每个位置都有一个中间表征,它取决于前 n–1个 位置处的单词嵌入(单词),这个原则适用于所有位置。使用当前位置的中间表征可以为该位置生成一个单词。
在 Bengio 等人的工作之后,大量的词嵌入方法和神经语言建模方法被开发出来,从不同的角度未语言建模带来了改进。
词嵌入的代表性方法包括 Word2Vec。代表性的神经语言模型是循环神经网络语言模型 (RNN) ,如长短期记忆语言模型 (LSTM) 。在一个 RNN 语言模型中,每个位置上单词的条件概率由一个 RNN 决定:
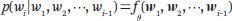
其中 w((1)), w((2)), ···, w((i-1)) 表示词的嵌入 w((1)), w((2)), ···, w((i-1));f(·) 表示 RNN;ϑ 表示网络参数。RNN 语言模型不再使用马尔可夫假设,每个位置上的单词都取决于之前所有位置上的单词。RNN 的一个重要概念是它的中间表征或状态。词之间的依赖关系以 RNN 模型中状态之间的依赖关系为特征。模型的参数在不同的位置可以共享,但在不同的位置得到的表征是不同的。
下图显示了 RNN 语言模型中各表征之间的关系。每个位置的每一层都有一个中间表征,它表示到目前为止单词序列的「状态」。当前层在当前位置的中间表征,由同一层在前一位置的中间表征和下一层在当前位置的中间表征决定。当前位置的最终中间表征用于计算下一个单词的概率。
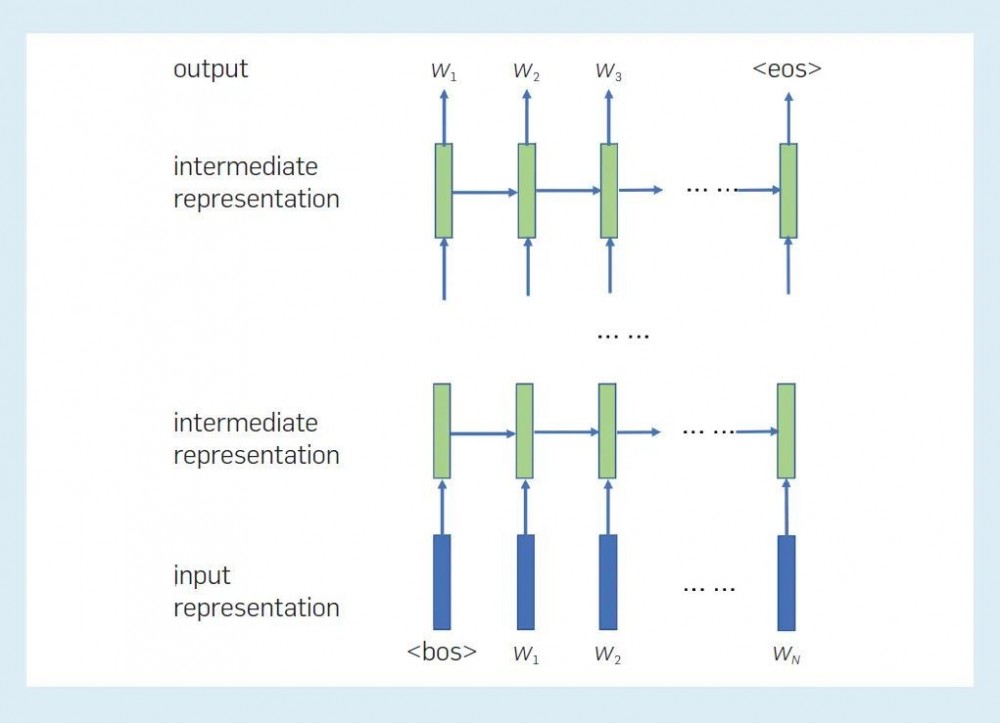
图 2:RNN 语言模型中各表征之间的关系。这里标记了句首(bos)和句尾(eos)。
语言模型可用于计算语言(词序列)的概率或生成语言。比如在生成语言方面,可以通过从语言模型中随机抽样来生成自然语言的句子或文章。众所周知,从大量数据中学习的 LSTM 语言模型可以生成非常自然的句子。
对语言模型的一个扩展是条件语言模型,它计算一个词序列在给定条件下的条件概率。如果条件是另一个词序列,那么问题就变成了从一个词序列到另一个词序列的转换——即所谓的序列到序列问题,涉及的任务如机器翻译、文本摘要和生成对话。如果给定的条件是一张图片,那么问题就变成了从图片到单词序列的转换,比如图像捕捉任务。
条件语言模型可以用在各种各样的应用程序中。在机器翻译中,在保持相同语义的条件下,系统将一种语言的句子转换成另一种语言的句子。在对话生成中,系统对用户的话语产生响应,两条消息构成一轮对话。在文本摘要中,系统将长文本转换为短文本,后者包含前者的要点。由模型的条件概率分布所表示的语义因应用程序而异,而且它们都是从应用程序中的数据中来学习的。
序列到序列模型的研究为新技术的发展做出了贡献。一个具有代表性的例子是由 Vaswani 等人开发的 Transformer。Transformer 完全基于注意力机制,利用注意力在编码器之间进行编码和解码,以及在编码器和解码器之间进行。目前,几乎所有的机器翻译系统都采用了 Transformer 模型,而且机器翻译已经达到了可以满足实际需要的水平。现在几乎所有预训练的语言模型都采用 Transformer 架构,因为它在语言表示方面具有卓越的能力。
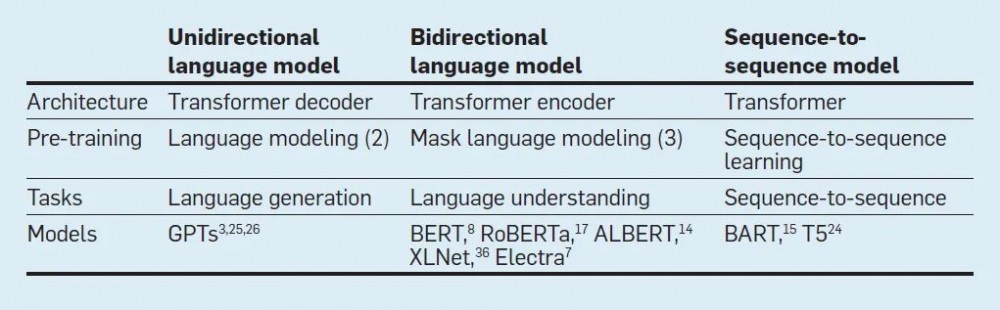
预训练语言模型的基本思想如下。首先,基于如 transformer 的编码器或解码器来实现语言模型。该模型的学习分两个阶段:一是预训练阶段,通过无监督学习(也称为自监督学习)使用大量的语料库来训练模型的参数;二是微调阶段,将预训练的模型应用于一个特定的任务,并通过监督学习使用少量标记数据进一步调整模型的参数。下表中的链接提供了学习和使用预训练语言模型的资源。

预训练语言模型有三种: 单向、双向和序列到序列。由于篇幅所限,这里只介绍前两种类型。所有主要的预训练语言模型都采用了 Transformer 架构。下表是对现有的预训练语言模型的概括。
Transformer 有很强的语言表示能力。一个非常大的语料库会包含丰富的语言表达(这样的未标记数据很容易获得),训练大规模深度学习模型就会变得更加高效。因此,预训练语言模型可以有效地表示语言中的词汇、句法和语义特征。预训练语言模型如 BERT 和 GPT(GPT-1、GPT-2 和 GPT-3),已成为当前 NLP 的核心技术。
预训的语言模型的应用为 NLP 带来了巨大的成功。「微调」的 BERT 在语言理解任务(如阅读理解)的准确性方面优于人类。「微调」的 GPT-3 在文本生成任务中也达到了惊人的流利程度。要注意的是,这些结果仅表明机器在这些任务中具有更高的性能;我们不应简单地将其理解为 BERT 和 GPT-3 能比人类更好地理解语言,因为这也取决于如何进行基准测试。从历史上可以看到,对人工智能技术持有正确的理解和期望,对于机器的健康成长和发展至关重要。
Radford 等人和 Brown 等人开发的 GPT 具有以下架构。输入是单词的序列 w((1)), w((2)), ···, w((N))。首先,通过输入层,创建一系列输入表征,记为矩阵 H(((0)))。在通过 L 个 transformer 解码器层之后,创建一系列中间表征序列,记为矩阵 H(((L)))。
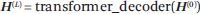
最后,基于该位置的最终中间表征来计算每个位置的单词概率分布。GPT 的预训练与传统的语言建模相同。目标是预测单词序列的可能性。对于给定的词序列 w = w((1)), w((2)), ···, w((N)),我们计算并最小化交叉熵或负对数似然来估计参数 :
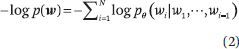
其中 ϑ 指 GPTs 模型的参数。
下图显示了 GPTs 模型中各表征之间的关系。每个位置上的输入表征由词嵌入和“位置嵌入”组成。每个位置上的每一层的中间表征是从下一层在先前位置上的中间表征创建的。单词的预测或生成在每个位置从左到右重复执行。换句话说,GPT 是一种单向语言模型,其中单词序列是从单一方向建模的。(注意,RNN 语言模型也是单向语言模型。)因此,GPT 更适合解决自动生成句子的语言生成问题。
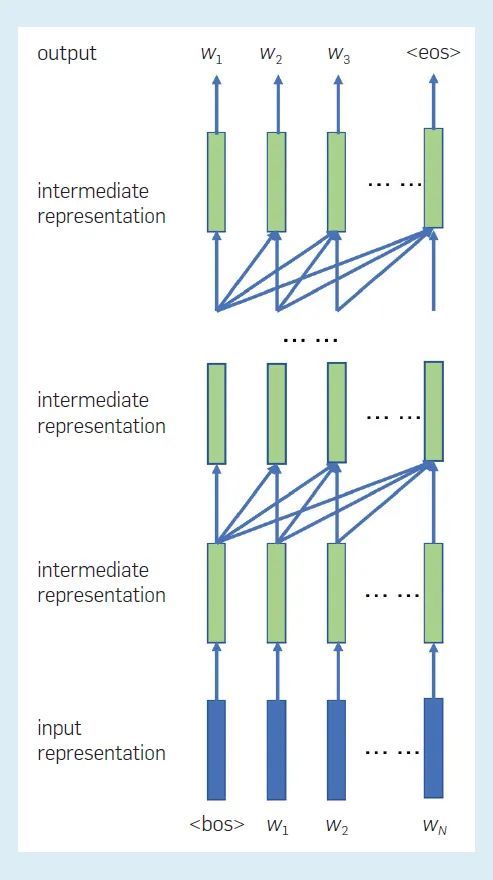
图 3:GPTs 语言模型中各表征之间的关系。这里标记了句首(bos)和句尾(eos)。
由 Devlin 等人开发的 BERT 具有以下架构。输入是一个单词序列,它可以是来自单个文档的连续句子,也可以是来自两个文档的连续句子的串联。这使得该模型适用于以一个文本为输入的任务(例如文本分类),以及以两个文本为输入的任务(例如回答问题)。首先,通过输入层,创建一系列输入表征,记为矩阵 H(((0)))。通过 L 个 transformer 编码器层之后,创建一个中间表征序列,记为 H(((L)))。
最后,可以根据该位置上的最终中间表征,来计算每个位置上单词的概率分布。BERT 的预训练被执行为所谓的掩码语言建模。假设词序列为 w = w((1)), w((2)), ···, w((N))。序列中的几个单词被随机掩蔽——即更改为特殊符号 [mask] —— 从而产生一个新的单词序列 其中掩码词的集合记为
其中掩码词的集合记为 学习的目标是通过计算和最小化下面的负对数似然来估计参数,以恢复被掩蔽的单词:
学习的目标是通过计算和最小化下面的负对数似然来估计参数,以恢复被掩蔽的单词:
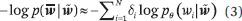
其中 ϑ 表示 BERT 模型的参数,δ((i)) 取值为 1 或 0,表示位置 i 处的单词是否被掩蔽。注意,掩码语言建模已经是一种不同于传统语言建模的技术。
图4展示了 BERT 模型中表示之间的关系。每个位置的输入表示由词嵌入、「位置嵌入」等组成,每层在每个位置的中间表征,是由下面一层在所有位置的中间表征创建的,词的预测或生成是在每个掩码位置独立进行的–参见(图3)。也就是说,BERT是一个双向语言模型,其中单词序列是从两个方向建模的。因此,BERT可以自然地应用于语言理解问题,其输入是整个单词序列,其输出通常是一个标签或一个标签序列。
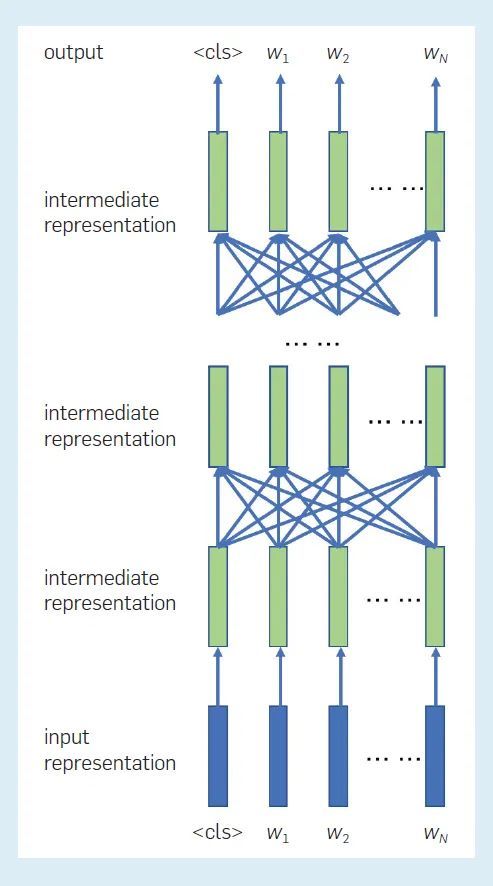
图 4:BERT 模型中各表征之间的关系。这里表示代表整个输入序列的特殊符号。
对预训练语言模型的一个直观解释是,机器在预训练中根据大型语料库进行了大量的单词接龙(GPT)或单词完形填空练习(BERT),捕捉到由单词组成句子的各种模式,由句子组成文章,并在模型中表达和记忆了这些模式。
一个文本不是由单词和句子随机产生的,而是基于词法、句法和语义规则来构建。GPT 和 BERT 可以分别使用转化器的解码器和编码器,来实现语言的组合性(组合性是语言最基本的特征,它也是由Chomsky 层次结构中的语法所建模的)。换句话说,GPT 和 BERT 在预训练中已经获得了相当数量的词汇、句法和语义知识。因此,当适应微调中的特定任务时,只需少量标记数据即可对模型进行细化,从而实现高性能。例如,人们发现 BERT 的不同层有不同的特点,底层主要代表词法知识,中间层主要代表句法知识,而顶层主要代表语义知识。
预训练的语言模型(没有微调),例如 BERT 和 GPT-3,就包含大量的事实知识,它们可以用来回答诸如「但丁在哪里出生?」之类的问题,只要它们在训练数据中获得了知识,就可以进行简单的推理,例如「48加76是多少?」
但是语言模型本身没有推理机制,其「推理」能力是基于联想、而不是真正的逻辑推理。因此,它们在需要复杂推理的问题上表现不佳,包括论证推理、数值和时间推理和话语推理,将推理能力和语言能力集成到 NLP 系统中,将是未来的一个重要课题。
当代科学(脑科学和认知科学)对人类语言处理机制(语言理解和语言生成)的理解有限。在可预见的未来,很难看到有重大突破发生,永远不会突破的可能性是存在的。另一方面,我们希望不断推动人工智能技术的发展,开发出对人类有用的语言处理机器,神经语言建模似乎是迄今为止最成功的方法。
目前看来,神经语言建模是迄今为止最成功的方法,它的基本特征没有改变–那就是,它依赖于在包含所有单词序列的离散空间中定义的概率分布。学习过程是为了找到最佳模型,以便交叉熵在预测语言数据的准确性方面是最高的(图5)。
神经语言建模通过神经网络构建模型,其优点在于,它可以利用复杂的模型、大数据和强大的计算来非常准确地模拟人类语言行为。从 Bengio 等人提出的原始模型、到 RNN 语言模型以及 GPT 和 BERT 等预训练语言模型,神经网络的架构变得越来越复杂(如图1-4),而预测语言的能力也越来越高(交叉熵越来越小)。然而,这并不一定意味着这些模型具有和人类一样的语言能力,而且其局限性也是不言而喻的。
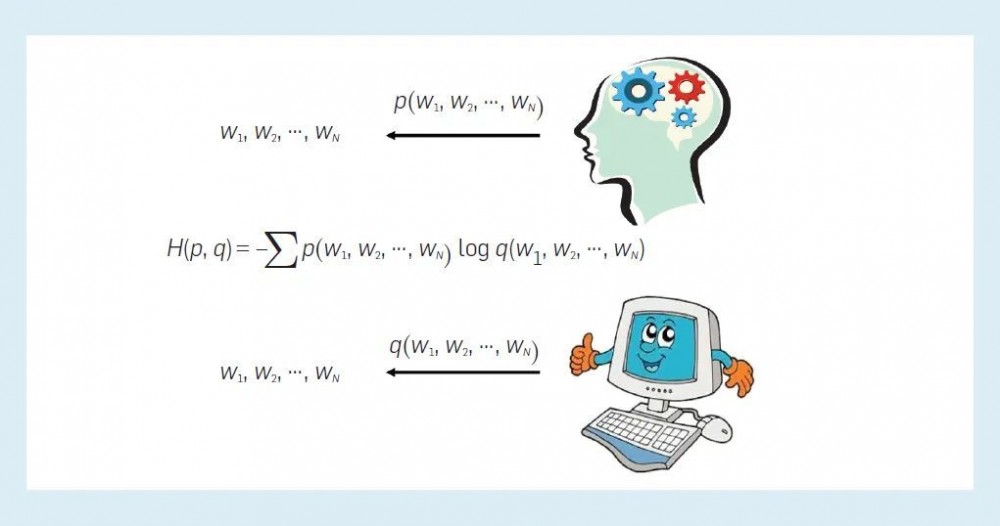
图5:机器通过调整其「大脑」内的神经网络参数来模仿人类语言行为,最终它可以像人类一样处理语言
那么,有其他可能的发展路径吗?目前还不清楚。但可以预见的是,神经语言建模的方法仍有很多改进机会。
目前,神经语言模型与人脑在表示能力和计算效率(功耗方面)方面还有很大差距,成人大脑的工作功率仅为 12 W,而训练 GPT-3 模型消耗了数千 Petaflop/s-day,这形成了鲜明的对比。能否开发出更好的语言模型、使其更接近人类语言处理,是未来研究的重要方向。我们可以从有限的脑科学发现中学习,技术提升仍然有很多机会。
人类语言处理被认为主要在大脑皮层的两个大脑区域进行:布罗卡区和韦尼克区(图6)。前者负责语法,后者负责词汇。脑损伤导致失语的典型案例有两种,布罗卡区受伤的患者只能说出零星的单词而无法说出句子,而韦尼克区受伤的患者可以构建语法正确的句子,但单词往往缺乏意义。
一个自然的假设是,人类语言处理是在两个大脑区域中并行进行的,是否需要采用更人性化的处理机制是一个值得研究的课题。正如Chomsky所指出的,语言模型没有明确地使用语法,也不能无限地组合语言,这是人类语言的一个重要属性,将语法更直接地结合到语言模型中的能力、将是一个需要研究的问题。
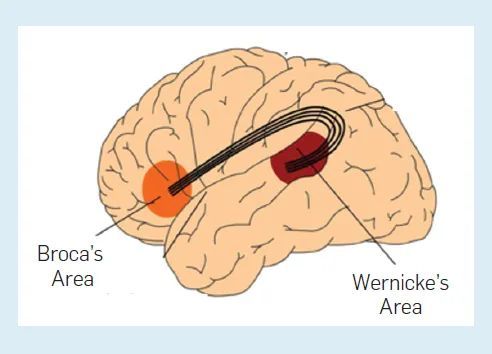
图6:人脑中负责语言处理的区域
脑科学家认为,人类语言理解是在潜意识中激活相关概念的表征、并在意识中生成相关图像的过程。表征包括视觉、听觉、触觉、嗅觉和味觉表征,它们是人在成长和发育过程中的经历、在大脑各部分记忆的概念的视觉、听觉、触觉、嗅觉和味觉内容。
因此,语言理解与人们的经验密切相关。生活中的基本概念,比如猫和狗,都是通过视觉、听觉、触觉等传感器的输入来学习的,当听到或看到「猫」和「狗」这两个词,就会重新激活人们大脑中与其相关的视觉、听觉和触觉表征。
机器能否从大量的多模态数据(语言、视觉、语音)中学习更好的模型,从而更智能地处理语言、视觉和语音?多模态语言模型将是未来探索的重要课题。最近,该主题的研究也取得了一些进展——例如,Ramesh 等人发表的「Zero-shot text-to-image generation」,Radford 等人的「Learning transferable visual models from natural language supervision」。
语言模型的历史可以追溯到一百多年前,Markov、Shannon 等人没有预见到他们所研究的模型和理论会在后来产生如此大的影响;对 Bengio 来说,这甚至可能是出乎意料的。
未来一百年,语言模型将如何发展?它们仍然是人工智能技术的重要组成部分吗?这可能超出了我们所能想象和预测的范围。但可以看到,语言建模技术在不断发展。在未来几年,可能有更强大的模型出现会取代 BERT 和 GPT,我们有幸成为看到巨大成就的技术、并参与研发的第一代。
本站部分文章来自互联网,文章版权归原作者所有。如有疑问请联系QQ:3164780!